A Map of the Territory
Bạn phải có một tấm bản đồ, dù nó có sơ sài đến đâu. Nếu không, bạn sẽ lang thang khắp nơi. Trong The Lord of the Rings tôi chưa bao giờ để ai đi xa hơn khả năng của họ trong một ngày.
J. R. R. Tolkien
Chúng ta không muốn lang thang vô định, nên trước khi bắt đầu, hãy khảo sát vùng lãnh thổ mà những người đi trước trong việc xây dựng ngôn ngữ đã vẽ ra. Điều này sẽ giúp chúng ta hiểu mình đang đi đâu và những con đường thay thế mà người khác đã chọn.
Trước hết, tôi muốn đặt ra một cách viết tắt. Phần lớn cuốn sách này nói về implementation của một ngôn ngữ, điều này khác với bản thân ngôn ngữ ở dạng lý tưởng kiểu Plato. Những thứ như “stack”, “bytecode” và “recursive descent” là các chi tiết kỹ thuật mà một implementation cụ thể có thể sử dụng. Từ góc nhìn của người dùng, miễn là cỗ máy kết quả tuân thủ đúng đặc tả của ngôn ngữ, thì tất cả chỉ là chi tiết implementation.
Chúng ta sẽ dành rất nhiều thời gian cho những chi tiết này, nên nếu mỗi lần nhắc đến chúng tôi đều phải viết “language implementation” thì chắc ngón tay tôi sẽ mòn mất. Thay vào đó, tôi sẽ dùng từ “language” để chỉ một ngôn ngữ, hoặc implementation của nó, hoặc cả hai, trừ khi sự khác biệt là quan trọng.
2 . 1Các thành phần của một ngôn ngữ
Các kỹ sư đã xây dựng ngôn ngữ lập trình từ thời “trung cổ” của ngành máy tính. Ngay khi chúng ta có thể nói chuyện với máy tính, chúng ta nhận ra việc đó quá khó và phải nhờ chính chúng giúp đỡ. Tôi thấy thật thú vị là, dù máy móc ngày nay nhanh hơn hàng triệu lần và có dung lượng lưu trữ lớn hơn hàng nghìn lần, cách chúng ta xây dựng ngôn ngữ lập trình hầu như không thay đổi.
Dù vùng đất mà các nhà thiết kế ngôn ngữ khám phá là rất rộng, những con đường họ khai phá qua đó lại không nhiều. Không phải ngôn ngữ nào cũng đi đúng một lộ trình — một số chọn vài lối tắt — nhưng nhìn chung chúng khá giống nhau, từ chiếc compiler COBOL đầu tiên của Chuẩn đô đốc Grace Hopper cho đến một ngôn ngữ mới toanh transpile sang JavaScript mà “tài liệu” chỉ là một file README duy nhất, chỉnh sửa cẩu thả trong một kho Git nào đó.
Tôi hình dung mạng lưới các con đường mà một implementation có thể chọn giống như việc leo núi. Bạn bắt đầu ở chân núi với chương trình ở dạng raw source text — về cơ bản chỉ là một chuỗi ký tự. Mỗi giai đoạn sẽ phân tích chương trình và biến đổi nó thành một dạng biểu diễn ở mức cao hơn, nơi mà semantics — tức là điều tác giả muốn máy tính thực hiện — trở nên rõ ràng hơn.
Cuối cùng, chúng ta lên đến đỉnh. Từ đây, ta có thể nhìn toàn cảnh chương trình của người dùng và thấy được code của họ có nghĩa là gì. Rồi ta bắt đầu đi xuống phía bên kia ngọn núi. Chúng ta biến đổi dạng biểu diễn ở mức cao nhất này xuống các dạng ở mức thấp hơn, từng bước một, để tiến gần hơn đến thứ mà chúng ta biết cách khiến CPU thực sự execute.
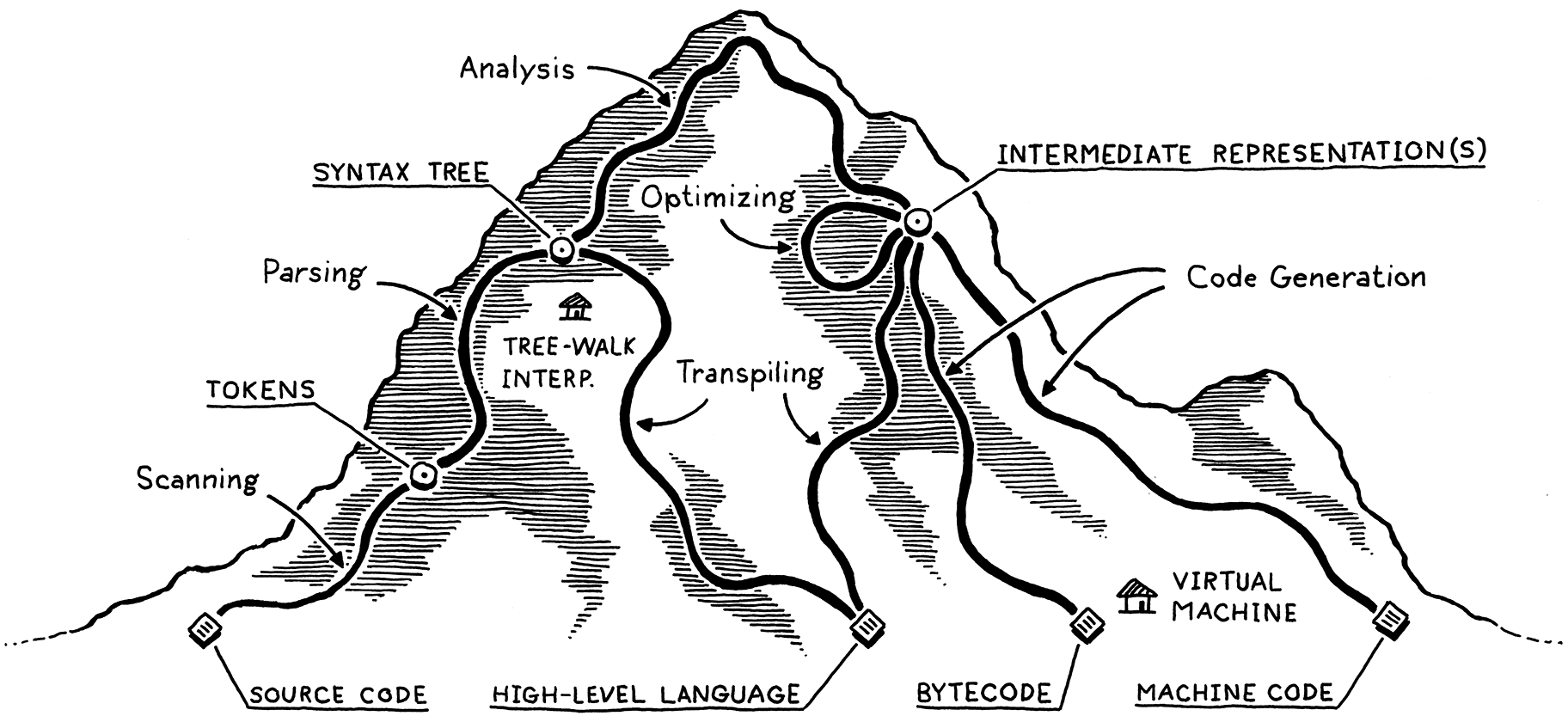
Hãy lần theo từng con đường và điểm thú vị đó. Hành trình của chúng ta bắt đầu từ bên trái, với phần văn bản thô của source code người dùng:

2 . 1 . 1Scanning
Bước đầu tiên là scanning, còn được gọi là lexing, hoặc (nếu bạn muốn gây ấn tượng) lexical analysis. Tất cả đều có nghĩa gần như nhau. Tôi thích từ “lexing” vì nó nghe như việc một siêu ác nhân sẽ làm, nhưng tôi sẽ dùng “scanning” vì nó có vẻ phổ biến hơn một chút.
Một scanner (hoặc lexer) nhận vào luồng ký tự tuyến tính và gom chúng lại thành một chuỗi thứ gì đó giống như “từ“. Trong ngôn ngữ lập trình, mỗi “từ” như vậy được gọi là một token. Một số token chỉ là một ký tự, như ( và ,. Số khác có thể dài nhiều ký tự, như số (123), string literal ("hi!"), và identifier (min).
Một số ký tự trong file source thực ra không mang ý nghĩa gì. Whitespace thường không quan trọng, và comment, theo định nghĩa, bị ngôn ngữ bỏ qua. Scanner thường loại bỏ chúng, để lại một chuỗi token có ý nghĩa rõ ràng.
![[var] [average] [=] [(] [min] [+] [max] [)] [/] [2] [;]](image/a-map-of-the-territory/tokens.png)
2 . 1 . 2Parsing
Bước tiếp theo là parsing. Đây là lúc cú pháp của chúng ta có một grammar — khả năng ghép các biểu thức và câu lệnh lớn hơn từ những phần nhỏ hơn. Bạn đã từng phân tích câu trong giờ học tiếng Anh chưa? Nếu rồi, bạn đã làm điều mà một parser làm, chỉ khác là tiếng Anh có hàng ngàn “keyword” và vô số mơ hồ, còn ngôn ngữ lập trình thì đơn giản hơn nhiều.
Một parser nhận chuỗi token phẳng và xây dựng một cấu trúc cây phản ánh bản chất lồng nhau của grammar. Những cây này có vài tên gọi khác nhau — parse tree hoặc abstract syntax tree — tùy vào việc chúng gần với cấu trúc cú pháp gốc của ngôn ngữ đến mức nào. Trong thực tế, dân lập trình thường gọi chúng là syntax tree, AST, hoặc đơn giản là tree.
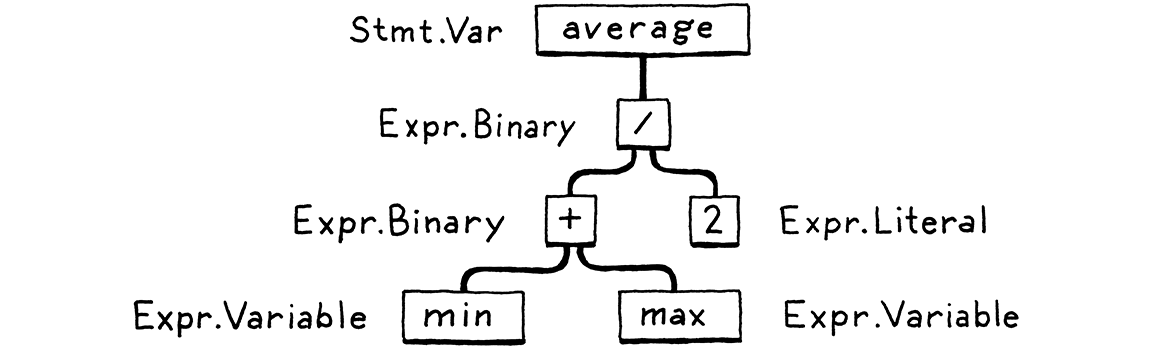
Parsing có một lịch sử lâu dài và phong phú trong khoa học máy tính, gắn liền với cộng đồng nghiên cứu trí tuệ nhân tạo. Nhiều kỹ thuật hiện nay dùng để parse ngôn ngữ lập trình vốn được nghĩ ra để parse ngôn ngữ tự nhiên bởi các nhà nghiên cứu AI, những người từng cố gắng khiến máy tính nói chuyện với chúng ta.
Hóa ra ngôn ngữ tự nhiên quá rối rắm so với các grammar cứng nhắc mà những parser đó có thể xử lý, nhưng chúng lại hoàn hảo cho các grammar nhân tạo đơn giản của ngôn ngữ lập trình. Tiếc là, con người chúng ta vẫn có thể dùng sai những grammar đơn giản đó, nên công việc của parser còn bao gồm việc báo cho chúng ta biết khi nào ta mắc lỗi, bằng cách đưa ra syntax error.
2 . 1 . 3Static analysis
Hai giai đoạn đầu tiên khá giống nhau ở hầu hết các implementation. Giờ thì những đặc điểm riêng của từng ngôn ngữ bắt đầu xuất hiện. Ở thời điểm này, chúng ta đã biết cấu trúc cú pháp của code — như biểu thức nào được lồng trong biểu thức nào — nhưng ngoài ra thì chưa biết nhiều hơn.
Trong một biểu thức như a + b, ta biết là đang cộng a và b, nhưng chưa biết những cái tên đó ám chỉ điều gì. Chúng là biến cục bộ? Biến toàn cục? Chúng được định nghĩa ở đâu?
Phân tích đầu tiên mà hầu hết các ngôn ngữ thực hiện được gọi là binding hoặc resolution. Với mỗi identifier, ta tìm xem tên đó được định nghĩa ở đâu và “nối dây” chúng lại với nhau. Đây là lúc scope xuất hiện — vùng trong source code mà một tên nhất định có thể được dùng để tham chiếu đến một khai báo cụ thể.
Nếu ngôn ngữ là statically typed, đây là lúc ta thực hiện type check. Khi đã biết a và b được khai báo ở đâu, ta cũng có thể xác định kiểu của chúng. Nếu các kiểu đó không hỗ trợ phép cộng với nhau, ta sẽ báo type error.
Hít một hơi thật sâu. Chúng ta đã lên đến đỉnh núi và có thể nhìn bao quát toàn bộ chương trình của người dùng. Tất cả những thông tin ngữ nghĩa mà ta thu được từ quá trình phân tích này cần được lưu trữ ở đâu đó. Có vài cách để “cất” chúng:
-
Thường thì, chúng được lưu ngay lại dưới dạng attributes trên chính syntax tree — các trường bổ sung trong node, không được khởi tạo khi parsing nhưng sẽ được điền vào sau đó.
-
Đôi khi, ta lưu dữ liệu trong một bảng tra cứu riêng. Thông thường, khóa của bảng này là các identifier — tên biến và khai báo. Trong trường hợp đó, ta gọi nó là symbol table và giá trị tương ứng với mỗi khóa cho biết identifier đó tham chiếu đến cái gì.
-
Công cụ quản lý dữ liệu mạnh mẽ nhất là biến đổi tree thành một cấu trúc dữ liệu hoàn toàn mới, thể hiện trực tiếp hơn ngữ nghĩa của code. Đó chính là phần tiếp theo.
Mọi thứ đến thời điểm này được xem là front end của implementation. Bạn có thể đoán rằng mọi thứ sau đó là back end, nhưng không hẳn vậy. Ngày xưa, khi các thuật ngữ “front end” và “back end” ra đời, compiler đơn giản hơn nhiều. Sau này, các nhà nghiên cứu đã nghĩ ra những giai đoạn mới để chèn vào giữa hai phần đó. Thay vì bỏ các thuật ngữ cũ, William Wulf và cộng sự đã gộp những giai đoạn mới này vào một cái tên vừa duyên dáng vừa nghịch lý về không gian: middle end.
2 . 1 . 4Intermediate representations
Bạn có thể hình dung compiler như một đường ống, nơi mỗi giai đoạn có nhiệm vụ tổ chức dữ liệu biểu diễn code của người dùng theo cách giúp giai đoạn tiếp theo dễ triển khai hơn. Front end của đường ống phụ thuộc vào ngôn ngữ nguồn mà chương trình được viết. Back end thì quan tâm đến kiến trúc cuối cùng nơi chương trình sẽ chạy.
Ở giữa, code có thể được lưu ở một dạng intermediate representation (IR) nào đó, không gắn chặt với cả dạng nguồn lẫn dạng đích (vì thế mới gọi là “intermediate”). Thay vào đó, IR đóng vai trò như một giao diện giữa hai “ngôn ngữ” này.
Điều này cho phép bạn hỗ trợ nhiều ngôn ngữ nguồn và nhiều nền tảng đích với ít công sức hơn. Giả sử bạn muốn viết compiler cho Pascal, C và Fortran, và muốn nhắm đến x86, ARM, và… SPARC chẳng hạn. Thông thường, điều đó đồng nghĩa với việc bạn phải viết chín compiler đầy đủ: Pascal→x86, C→ARM, và mọi kết hợp khác.
Một shared intermediate representation sẽ giảm đáng kể khối lượng đó. Bạn chỉ cần viết một front end cho mỗi ngôn ngữ nguồn để sinh ra IR. Sau đó, viết một back end cho mỗi kiến trúc đích. Giờ thì bạn có thể kết hợp chúng để tạo ra mọi tổ hợp.
Còn một lý do lớn khác khiến ta muốn biến đổi code sang một dạng thể hiện rõ hơn ngữ nghĩa của nó…
2 . 1 . 5Optimization
Khi đã hiểu chương trình của người dùng có nghĩa là gì, chúng ta hoàn toàn có thể thay thế nó bằng một chương trình khác có cùng semantics nhưng được thực hiện hiệu quả hơn — tức là chúng ta có thể tối ưu hóa nó.
Một ví dụ đơn giản là constant folding: nếu một biểu thức nào đó luôn cho ra cùng một giá trị, ta có thể tính toán nó ngay tại thời điểm compile và thay đoạn code của biểu thức đó bằng kết quả. Nếu người dùng gõ:
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
thì ta có thể thực hiện toàn bộ phép tính đó ngay trong compiler và đổi code thành:
pennyArea = 0.4417860938;
Tối ưu hóa là một phần cực kỳ lớn trong lĩnh vực ngôn ngữ lập trình. Nhiều lập trình viên chuyên về ngôn ngữ dành cả sự nghiệp ở mảng này, vắt kiệt từng giọt hiệu năng từ compiler của họ để làm benchmark nhanh hơn chỉ một phần trăm nhỏ. Nó có thể trở thành một kiểu ám ảnh.
Trong cuốn sách này, chúng ta sẽ chủ yếu bỏ qua “cái hang” đó. Nhiều ngôn ngữ thành công lại có rất ít tối ưu hóa ở compile-time. Ví dụ, Lua và CPython sinh ra code tương đối chưa được tối ưu, và tập trung phần lớn nỗ lực cải thiện hiệu năng ở runtime.
2 . 1 . 6Code generation
Chúng ta đã áp dụng tất cả các tối ưu hóa có thể nghĩ ra cho chương trình của người dùng. Bước cuối cùng là chuyển nó sang dạng mà máy có thể thực sự chạy được. Nói cách khác, generating code (hay code gen), trong đó “code” ở đây thường chỉ các lệnh dạng assembly nguyên thủy mà CPU execute, chứ không phải “source code” mà con người muốn đọc.
Cuối cùng, chúng ta đã ở back end, bắt đầu đi xuống phía bên kia ngọn núi. Từ đây trở đi, cách biểu diễn code của chúng ta sẽ ngày càng nguyên thủy hơn, giống như quá trình tiến hóa chạy ngược, khi ta tiến gần đến thứ mà cỗ máy “đơn giản” của mình có thể hiểu.
Giờ ta phải đưa ra quyết định: sinh ra lệnh cho CPU thật hay cho CPU ảo? Nếu sinh ra machine code thật, ta sẽ có một file executable mà hệ điều hành có thể nạp trực tiếp vào chip. Native code chạy cực nhanh, nhưng việc sinh ra nó tốn rất nhiều công sức. Kiến trúc CPU ngày nay có hàng đống lệnh, pipeline phức tạp, và đủ “hành lý lịch sử” để chất đầy khoang hành lý của một chiếc 747.
Việc “nói ngôn ngữ” của chip cũng đồng nghĩa compiler của bạn bị ràng buộc vào một kiến trúc cụ thể. Nếu compiler của bạn sinh ra machine code x86, nó sẽ không chạy được trên thiết bị ARM. Từ tận những năm 60, trong thời kỳ bùng nổ kiến trúc máy tính, sự thiếu tính di động này là một trở ngại thực sự.
Để vượt qua vấn đề đó, những hacker như Martin Richards và Niklaus Wirth — nổi tiếng với BCPL và Pascal — đã làm compiler sinh ra virtual machine code. Thay vì lệnh cho một con chip thật, họ tạo ra code cho một cỗ máy giả tưởng, lý tưởng hóa. Wirth gọi nó là p-code (viết tắt của portable), nhưng ngày nay, chúng ta thường gọi là bytecode vì mỗi lệnh thường dài đúng một byte.
Những lệnh nhân tạo này được thiết kế để bám sát semantics của ngôn ngữ hơn một chút, và không bị ràng buộc vào những đặc thù hay “rác lịch sử” của bất kỳ kiến trúc máy tính cụ thể nào. Bạn có thể hình dung nó như một dạng mã nhị phân cô đọng, mã hóa các thao tác mức thấp của ngôn ngữ.
2 . 1 . 7Virtual machine
Nếu compiler của bạn sinh ra bytecode, công việc chưa kết thúc ở đó. Vì không có chip nào “nói” bytecode này, bạn phải dịch nó. Một lần nữa, bạn có hai lựa chọn. Bạn có thể viết một mini-compiler cho từng kiến trúc đích, chuyển bytecode thành native code cho máy đó. Bạn vẫn phải làm việc cho mỗi con chip mà bạn hỗ trợ, nhưng giai đoạn cuối này khá đơn giản và bạn có thể tái sử dụng toàn bộ phần còn lại của pipeline compiler cho tất cả các máy. Về cơ bản, bạn đang dùng bytecode như một intermediate representation.
Hoặc bạn có thể viết một virtual machine (VM), một chương trình mô phỏng một con chip giả tưởng hỗ trợ kiến trúc ảo của bạn tại runtime. Chạy bytecode trong VM sẽ chậm hơn so với dịch nó sang native code trước, vì mỗi lệnh phải được mô phỏng tại runtime mỗi khi nó chạy. Đổi lại, bạn có được sự đơn giản và tính di động. Viết VM của bạn bằng, chẳng hạn, C, và bạn có thể chạy ngôn ngữ của mình trên bất kỳ nền tảng nào có C compiler. Đây chính là cách mà interpreter thứ hai chúng ta xây dựng trong cuốn sách này hoạt động.
2 . 1 . 8Runtime
Cuối cùng, chúng ta đã “rèn giũa” chương trình của người dùng thành một dạng có thể execute. Bước cuối cùng là chạy nó. Nếu chúng ta compile sang machine code, chỉ cần bảo hệ điều hành nạp file executable và thế là xong. Nếu compile sang bytecode, ta cần khởi động VM và nạp chương trình vào đó.
Trong cả hai trường hợp, trừ những ngôn ngữ ở mức cực kỳ thấp, ta thường cần một số dịch vụ mà ngôn ngữ cung cấp khi chương trình đang chạy. Ví dụ, nếu ngôn ngữ tự động quản lý bộ nhớ, ta cần một garbage collector để thu hồi các vùng nhớ không còn dùng. Nếu ngôn ngữ hỗ trợ phép kiểm tra “instance of” để bạn biết mình đang có loại object nào, thì ta cần một cơ chế để theo dõi kiểu của từng object trong quá trình execute.
Tất cả những thứ này diễn ra ở runtime, nên hợp lý khi gọi nó là runtime. Trong một ngôn ngữ được compile hoàn toàn, phần code hiện thực runtime sẽ được chèn trực tiếp vào file executable kết quả. Ví dụ, trong Go, mỗi ứng dụng được compile sẽ có bản sao runtime của Go được nhúng trực tiếp bên trong. Nếu ngôn ngữ chạy bên trong một interpreter hoặc VM, thì runtime sẽ nằm ở đó. Đây là cách hầu hết các implementation của Java, Python và JavaScript hoạt động.
2 . 2Shortcuts and Alternate Routes
Đó là con đường dài bao quát mọi giai đoạn có thể triển khai. Nhiều ngôn ngữ đi hết toàn bộ lộ trình này, nhưng cũng có vài lối tắt và đường vòng khác.
2 . 2 . 1Single-pass compilers
Một số compiler đơn giản trộn lẫn parsing, analysis và code generation để sinh ra code đầu ra trực tiếp ngay trong parser, mà không hề tạo ra syntax tree hay IR nào. Những single-pass compilers này sẽ hạn chế thiết kế của ngôn ngữ. Bạn sẽ không có cấu trúc dữ liệu trung gian để lưu thông tin toàn cục về chương trình, và cũng không quay lại xử lý phần code đã parse trước đó. Điều đó có nghĩa là ngay khi gặp một biểu thức, bạn phải biết đủ thông tin để compile nó chính xác.
Pascal và C được thiết kế xoay quanh giới hạn này. Thời đó, bộ nhớ quý giá đến mức một compiler có thể không đủ chỗ để giữ cả một source file trong bộ nhớ, chứ chưa nói đến toàn bộ chương trình. Đây là lý do grammar của Pascal yêu cầu các khai báo kiểu phải xuất hiện đầu tiên trong một block. Và cũng là lý do trong C, bạn không thể gọi một hàm nằm phía dưới code định nghĩa nó, trừ khi bạn có một khai báo forward declaration rõ ràng để báo cho compiler biết những gì cần thiết để sinh code cho lời gọi hàm đó.
2 . 2 . 2Tree-walk interpreters
Một số ngôn ngữ lập trình bắt đầu execute code ngay sau khi parse nó thành AST (có thể kèm một chút static analysis). Để chạy chương trình, interpreter sẽ duyệt syntax tree từng nhánh và từng lá, đánh giá từng node khi đi qua.
Kiểu implementation này phổ biến trong các dự án sinh viên và những ngôn ngữ nhỏ, nhưng không được dùng rộng rãi cho các ngôn ngữ general-purpose vì nó thường chậm. Một số người dùng từ “interpreter” chỉ để nói về những implementation kiểu này, nhưng số khác định nghĩa rộng hơn, nên tôi sẽ dùng cụm từ rõ ràng tree-walk interpreter để chỉ chúng. Interpreter đầu tiên của chúng ta sẽ hoạt động theo cách này.
2 . 2 . 3Transpilers
Việc viết một back end hoàn chỉnh cho một ngôn ngữ có thể tốn rất nhiều công sức. Nếu bạn có sẵn một IR tổng quát để nhắm tới, bạn có thể gắn front end của mình vào đó. Nếu không, có vẻ như bạn sẽ bị “kẹt”. Nhưng điều gì sẽ xảy ra nếu bạn coi một source language khác như thể nó là một intermediate representation?
Bạn viết một front end cho ngôn ngữ của mình. Sau đó, ở back end, thay vì làm toàn bộ công việc để hạ thấp semantics xuống một ngôn ngữ đích nguyên thủy, bạn tạo ra một chuỗi source code hợp lệ của một ngôn ngữ khác có mức độ trừu tượng tương đương với ngôn ngữ của bạn. Rồi bạn dùng các công cụ compile sẵn có của ngôn ngữ đó như một lối thoát để “xuống núi” và tới được thứ bạn có thể execute.
Trước đây, người ta gọi cách này là source-to-source compiler hoặc transcompiler. Sau khi các ngôn ngữ compile sang JavaScript để chạy trong trình duyệt trở nên phổ biến, chúng đã khoác lên mình cái tên “hipster” là transpiler.
Trong khi transcompiler đầu tiên dịch từ một assembly language sang một assembly language khác, thì ngày nay, hầu hết transpiler làm việc với các ngôn ngữ bậc cao hơn. Sau khi UNIX lan truyền mạnh mẽ tới đủ loại máy móc, đã hình thành một truyền thống lâu dài về các compiler sinh ra C làm ngôn ngữ đầu ra. Compiler C có mặt ở khắp nơi UNIX tồn tại và tạo ra code hiệu quả, nên nhắm tới C là một cách tốt để chạy ngôn ngữ của bạn trên nhiều kiến trúc.
Ngày nay, trình duyệt web là “cỗ máy” của thời đại, và “machine code” của chúng là JavaScript, nên dường như gần như mọi ngôn ngữ ngoài kia đều có compiler nhắm tới JS, vì đó là cách chính để chạy code của bạn trong trình duyệt.
Front end — scanner và parser — của một transpiler trông giống như các compiler khác. Sau đó, nếu ngôn ngữ nguồn chỉ là một lớp cú pháp đơn giản bao quanh ngôn ngữ đích, nó có thể bỏ qua hoàn toàn bước phân tích và đi thẳng tới việc xuất ra cú pháp tương ứng trong ngôn ngữ đích.
Nếu hai ngôn ngữ khác nhau nhiều về semantics, bạn sẽ thấy nhiều giai đoạn quen thuộc của một compiler đầy đủ, bao gồm cả phân tích và thậm chí tối ưu hóa. Rồi, khi đến bước code generation, thay vì xuất ra một ngôn ngữ nhị phân như machine code, bạn tạo ra một chuỗi source code (hay đúng hơn là code đích) đúng ngữ pháp trong ngôn ngữ mục tiêu.
Dù theo cách nào, bạn cũng sẽ chạy đoạn code kết quả đó qua pipeline compile sẵn có của ngôn ngữ đích, và thế là xong.
2 . 2 . 4Just-in-time compilation
Cách cuối cùng này không hẳn là một lối tắt, mà giống như một pha leo núi nguy hiểm chỉ dành cho dân chuyên. Cách nhanh nhất để execute code là compile nó sang machine code, nhưng bạn có thể không biết kiến trúc mà máy của người dùng cuối hỗ trợ. Vậy phải làm sao?
Bạn có thể làm giống như HotSpot Java Virtual Machine (JVM), Common Language Runtime (CLR) của Microsoft, và hầu hết các JavaScript interpreter. Trên máy của người dùng cuối, khi chương trình được nạp — từ source trong trường hợp JS, hoặc bytecode độc lập nền tảng đối với JVM và CLR — bạn compile nó sang native code cho kiến trúc mà máy của họ hỗ trợ. Tất nhiên, điều này được gọi là just-in-time compilation. Hầu hết dân lập trình chỉ gọi tắt là “JIT”, phát âm vần với “fit”.
Những JIT tinh vi nhất sẽ chèn các hook profiling vào code đã sinh để xem vùng nào là quan trọng nhất về hiệu năng và loại dữ liệu nào đang đi qua chúng. Sau đó, theo thời gian, chúng sẽ tự động compile lại những hot spot đó với các tối ưu hóa nâng cao hơn.
2 . 3Compilers & Interpreters
Giờ thì tôi đã “nhồi” vào đầu bạn một lượng thuật ngữ lập trình đủ để làm thành một cuốn từ điển, chúng ta cuối cùng cũng có thể bàn đến một câu hỏi đã làm đau đầu dân lập trình từ thuở khai thiên lập địa: Sự khác nhau giữa compiler và interpreter là gì?
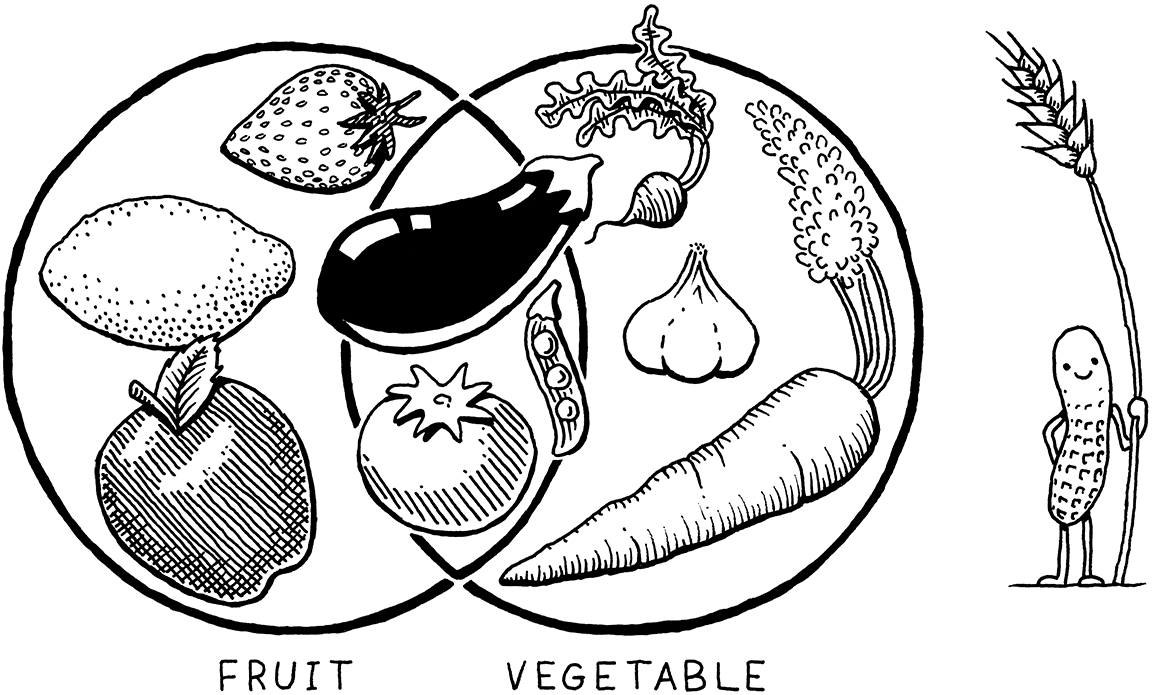
Hóa ra, câu hỏi này giống như hỏi sự khác nhau giữa “fruit” (quả) và “vegetable” (rau). Nghe thì có vẻ là một lựa chọn nhị phân, hoặc cái này hoặc cái kia, nhưng thực ra “fruit” là một thuật ngữ thực vật học, còn “vegetable” là thuật ngữ ẩm thực. Một bên không nhất thiết phủ định bên kia. Có những loại quả không phải rau (táo), có những loại rau không phải quả (cà rốt), nhưng cũng có những loại thực vật ăn được vừa là quả vừa là rau, như cà chua.
Quay lại với ngôn ngữ lập trình:
-
Compiling là một implementation technique liên quan đến việc dịch một source language sang một dạng khác — thường là mức thấp hơn. Khi bạn sinh ra bytecode hoặc machine code, bạn đang compile. Khi bạn transpile sang một ngôn ngữ bậc cao khác, bạn cũng đang compile.
-
Khi ta nói một implementation của ngôn ngữ “là một compiler”, ý là nó dịch source code sang một dạng khác nhưng không execute nó. Người dùng phải tự lấy output đó và chạy.
-
Ngược lại, khi ta nói một implementation “là một interpreter”, ý là nó nhận source code và execute ngay lập tức. Nó chạy chương trình “từ source”.
Giống như táo và cam, có những implementation rõ ràng là compiler và không phải interpreter. GCC và Clang nhận code C của bạn và compile sang machine code. Người dùng cuối chạy file executable đó trực tiếp và có thể chẳng bao giờ biết công cụ nào đã compile nó. Vậy nên chúng là compiler cho C.
Trong các phiên bản cũ của implementation Ruby chuẩn của Matz, người dùng chạy Ruby trực tiếp từ source. Implementation parse code và execute ngay bằng cách duyệt syntax tree. Không có bước dịch nào khác, dù là bên trong hay ở dạng mà người dùng thấy được. Vậy nên đây chắc chắn là một interpreter cho Ruby.
Thế còn CPython thì sao? Khi bạn chạy chương trình Python bằng nó, code sẽ được parse và chuyển sang một định dạng bytecode nội bộ, rồi được execute bên trong VM. Từ góc nhìn của người dùng, đây rõ ràng là một interpreter — họ chạy chương trình từ source. Nhưng nếu “lột da” CPython ra, bạn sẽ thấy rõ ràng là có quá trình compile diễn ra.
Câu trả lời là nó cả hai. CPython là một interpreter, và nó có một compiler. Trên thực tế, hầu hết các ngôn ngữ scripting đều hoạt động theo cách này, như bạn có thể thấy:
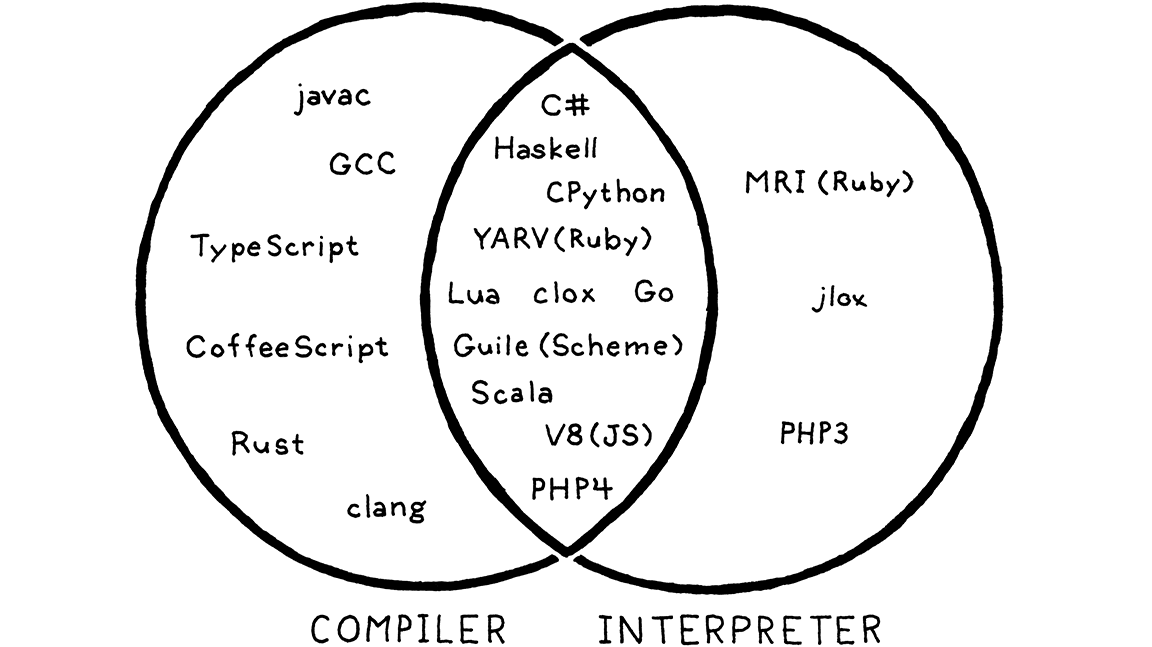
Vùng giao nhau ở giữa cũng chính là nơi interpreter thứ hai của chúng ta tồn tại, vì nó compile nội bộ sang bytecode. Vậy nên, dù cuốn sách này trên danh nghĩa là về interpreter, chúng ta cũng sẽ bàn đến cả compilation.
2 . 4Hành trình của chúng ta
Có khá nhiều thông tin để tiếp nhận cùng lúc. Đừng lo. Đây không phải là chương mà bạn cần hiểu hết tất cả các phần và chi tiết này. Tôi chỉ muốn bạn biết rằng chúng tồn tại và đại khái cách chúng kết nối với nhau.
Tấm bản đồ này sẽ hữu ích cho bạn khi khám phá vùng đất ngoài con đường có hướng dẫn mà chúng ta sẽ đi trong cuốn sách này. Tôi muốn để bạn khao khát tự mình khám phá và lang thang khắp ngọn núi đó.
Nhưng, bây giờ, đã đến lúc bắt đầu hành trình của chính chúng ta. Hãy siết chặt dây giày, buộc chặt ba lô, và cùng lên đường. Từ đây trở đi, tất cả những gì bạn cần tập trung là con đường ngay trước mắt.
2 . 5Thử thách
-
Chọn một implementation mã nguồn mở của một ngôn ngữ bạn thích. Tải source code về và khám phá. Thử tìm phần code hiện thực scanner và parser. Chúng được viết thủ công hay sinh ra bằng công cụ như Lex và Yacc? (Các file
.lhoặc.ythường ám chỉ trường hợp thứ hai.) -
Just-in-time compilation thường là cách nhanh nhất để hiện thực các ngôn ngữ dynamically typed, nhưng không phải tất cả đều dùng nó. Có những lý do nào để không dùng JIT?
-
Hầu hết các implementation Lisp compile sang C cũng chứa một interpreter cho phép chúng execute code Lisp ngay lập tức. Tại sao?