Compiling Expressions
Giữa chặng đường đời của chúng ta, tôi thấy mình lạc giữa khu rừng tăm tối
nơi con đường thẳng đã mất dấu.Dante Alighieri, Inferno
Chương này thật sự thú vị, không chỉ vì một, hay hai, mà là ba lý do.
Thứ nhất, nó mang đến mảnh ghép cuối cùng trong pipeline execute của VM. Khi đã hoàn thiện, chúng ta có thể dẫn luồng source code của người dùng từ bước scanning cho đến khi execute.
Thứ hai, chúng ta sẽ viết một compiler thực thụ. Nó sẽ parse source code và xuất ra một chuỗi các lệnh nhị phân cấp thấp. Ừ thì, đó là bytecode chứ không phải tập lệnh gốc của một con chip nào, nhưng nó gần “sát kim loại” hơn nhiều so với jlox. Chúng ta sắp trở thành những kẻ “hack” ngôn ngữ thực sự.
Thứ ba và cuối cùng, tôi sẽ giới thiệu với bạn một trong những thuật toán mà tôi yêu thích nhất: “top-down operator precedence parsing” của Vaughan Pratt. Đây là cách thanh nhã nhất mà tôi biết để parse biểu thức. Nó xử lý gọn gàng các toán tử prefix, postfix, infix, mixfix, bất kỳ dạng -fix nào bạn có. Nó giải quyết precedence và associativity một cách nhẹ nhàng. Tôi thật sự rất thích nó.
Như thường lệ, trước khi đến phần thú vị, chúng ta cần xử lý vài bước chuẩn bị. Bạn phải ăn rau trước khi được ăn tráng miệng. Đầu tiên, hãy bỏ đi phần scaffolding tạm thời mà ta viết để test scanner và thay bằng thứ gì đó hữu ích hơn.
InterpretResult interpret(const char* source) {
in interpret()
replace 2 lines
Chunk chunk; initChunk(&chunk); if (!compile(source, &chunk)) { freeChunk(&chunk); return INTERPRET_COMPILE_ERROR; } vm.chunk = &chunk; vm.ip = vm.chunk->code; InterpretResult result = run(); freeChunk(&chunk); return result;
}
Chúng ta tạo một chunk rỗng mới và chuyển nó cho compiler. Compiler sẽ lấy chương trình của người dùng và lấp đầy chunk bằng bytecode. Ít nhất, đó là những gì nó sẽ làm nếu chương trình không có lỗi compile. Nếu gặp lỗi, compile() sẽ trả về false và chúng ta bỏ chunk đó đi vì không dùng được.
Ngược lại, nếu compile thành công, chúng ta gửi chunk hoàn chỉnh sang VM để execute. Khi VM chạy xong, chúng ta giải phóng chunk và kết thúc. Như bạn thấy, signature của compile() giờ đã khác.
#define clox_compiler_h
replace 1 line
#include "vm.h" bool compile(const char* source, Chunk* chunk);
#endif
Chúng ta truyền vào chunk nơi compiler sẽ ghi code, và compile() trả về kết quả compile thành công hay không. Chúng ta cũng thay đổi signature tương tự trong phần implementation.
#include "scanner.h"
function compile()
replace 1 line
bool compile(const char* source, Chunk* chunk) {
initScanner(source);
Lệnh gọi initScanner() là dòng duy nhất còn lại từ chương này. Hãy gỡ bỏ code tạm mà ta viết để test scanner và thay bằng ba dòng này:
initScanner(source);
in compile()
replace 13 lines
advance(); expression(); consume(TOKEN_EOF, "Expect end of expression.");
}
Lệnh gọi advance() sẽ “mồi bơm” cho scanner. Chúng ta sẽ sớm thấy nó làm gì. Sau đó, ta parse một biểu thức duy nhất. Chúng ta chưa xử lý statement, nên đây là phần duy nhất của grammar được hỗ trợ. Chúng ta sẽ quay lại khi thêm statement trong vài chương tới. Sau khi compile xong biểu thức, ta phải ở cuối source code, nên ta kiểm tra token EOF.
Chúng ta sẽ dành phần còn lại của chương này để làm cho hàm này hoạt động, đặc biệt là lời gọi expression() kia. Thông thường, ta sẽ nhảy ngay vào định nghĩa hàm đó và triển khai từ trên xuống dưới.
Nhưng chương này thì khác. Kỹ thuật parsing của Pratt rất đơn giản khi bạn đã nắm toàn bộ trong đầu, nhưng hơi khó để chia thành từng phần nhỏ. Nó đệ quy, tất nhiên, đó là một phần của vấn đề. Nhưng nó cũng dựa vào một bảng dữ liệu lớn. Khi ta xây dựng thuật toán, bảng này sẽ có thêm nhiều cột.
Tôi không muốn phải xem lại hơn 40 dòng code mỗi khi mở rộng bảng. Thế nên, chúng ta sẽ tiếp cận lõi của parser từ bên ngoài, xử lý tất cả phần xung quanh trước khi vào phần “ruột” hấp dẫn. Điều này sẽ đòi hỏi bạn kiên nhẫn hơn và dành chút “bộ nhớ tạm” trong đầu, nhưng đây là cách tốt nhất mà tôi có thể nghĩ ra.
17 . 1Biên dịch một lượt (Single-Pass Compilation)
Một compiler thường có hai nhiệm vụ chính. Nó parse source code của người dùng để hiểu ý nghĩa của nó. Sau đó, nó dùng kiến thức đó để xuất ra các lệnh cấp thấp tạo ra cùng một ngữ nghĩa. Nhiều ngôn ngữ tách hai vai trò này thành hai pass riêng biệt trong quá trình triển khai. Một parser tạo ra AST — giống như jlox đã làm — rồi một code generator sẽ duyệt AST và xuất ra target code.
Trong clox, chúng ta sẽ áp dụng cách tiếp cận kiểu “old-school” và gộp hai pass này thành một. Ngày xưa, các “hacker” ngôn ngữ làm vậy vì máy tính khi đó thực sự không đủ bộ nhớ để lưu toàn bộ AST của một file source. Còn chúng ta làm vậy vì nó giúp compiler đơn giản hơn, điều này rất có lợi khi lập trình bằng C.
Những compiler single-pass như chúng ta sắp xây không phù hợp với mọi ngôn ngữ. Vì compiler chỉ có “tầm nhìn qua lỗ khóa” vào chương trình của người dùng khi sinh code, ngôn ngữ phải được thiết kế sao cho bạn không cần quá nhiều ngữ cảnh xung quanh để hiểu một đoạn cú pháp. May mắn thay, Lox nhỏ gọn, kiểu động lại rất phù hợp với điều đó.
Điều này có nghĩa là, về mặt thực tế, module C “compiler” của chúng ta sẽ có những chức năng bạn sẽ nhận ra từ jlox để parsing — tiêu thụ token, khớp loại token mong đợi, v.v. — và cũng có các hàm cho code gen — phát bytecode và thêm constant vào chunk đích. (Và điều đó cũng có nghĩa là tôi sẽ dùng “parsing” và “compiling” thay thế cho nhau xuyên suốt chương này và các chương sau.)
Chúng ta sẽ xây dựng phần parsing và phần code generation trước. Sau đó, chúng ta sẽ nối chúng lại với đoạn code ở giữa, đoạn này dùng kỹ thuật của Pratt để parse grammar đặc trưng của Lox và xuất ra bytecode đúng.
17 . 2Parsing Token
Bắt đầu với nửa đầu của compiler. Tên hàm này chắc nghe quen lắm.
#include "scanner.h"
static void advance() { parser.previous = parser.current; for (;;) { parser.current = scanToken(); if (parser.current.type != TOKEN_ERROR) break; errorAtCurrent(parser.current.start); } }
Giống như trong jlox, nó bước tới token tiếp theo trong luồng token. Nó yêu cầu scanner lấy token kế tiếp và lưu lại để dùng sau. Trước khi làm vậy, nó lấy token current cũ và cất vào trường previous. Điều này sẽ hữu ích sau này khi chúng ta cần lấy lexeme sau khi đã match một token.
Code để đọc token tiếp theo được bao trong một vòng lặp. Nhớ rằng, scanner của clox không báo lỗi lexical. Thay vào đó, nó tạo ra các error token đặc biệt và để parser chịu trách nhiệm báo lỗi. Chúng ta xử lý điều đó ở đây.
Chúng ta tiếp tục lặp, đọc token và báo lỗi, cho đến khi gặp một token không lỗi hoặc tới cuối file. Bằng cách này, phần còn lại của parser chỉ thấy token hợp lệ. Token hiện tại và token trước đó được lưu trong struct này:
#include "scanner.h"
typedef struct { Token current; Token previous; } Parser; Parser parser;
static void advance() {
Giống như ở các module khác, chúng ta có một biến global duy nhất của kiểu struct này để không phải truyền trạng thái qua lại giữa các hàm trong compiler.
17 . 2 . 1Xử lý lỗi cú pháp
Nếu scanner đưa cho chúng ta một error token, chúng ta cần báo cho người dùng biết. Điều đó được thực hiện bằng:
add after variable parser
static void errorAtCurrent(const char* message) { errorAt(&parser.current, message); }
Chúng ta lấy vị trí từ token hiện tại để báo cho người dùng lỗi xảy ra ở đâu và chuyển tiếp nó tới errorAt(). Thường thì, chúng ta sẽ báo lỗi tại vị trí của token vừa tiêu thụ, nên chúng ta đặt tên ngắn hơn cho hàm khác này:
add after variable parser
static void error(const char* message) { errorAt(&parser.previous, message); }
Phần xử lý thực sự diễn ra ở đây:
add after variable parser
static void errorAt(Token* token, const char* message) { fprintf(stderr, "[line %d] Error", token->line); if (token->type == TOKEN_EOF) { fprintf(stderr, " at end"); } else if (token->type == TOKEN_ERROR) { // Nothing. } else { fprintf(stderr, " at '%.*s'", token->length, token->start); } fprintf(stderr, ": %s\n", message); parser.hadError = true; }
Đầu tiên, chúng ta in ra vị trí lỗi. Chúng ta cố gắng hiển thị lexeme nếu nó dễ đọc với con người. Sau đó, chúng ta in thông báo lỗi. Tiếp theo, chúng ta đặt flag hadError. Cờ này ghi nhận việc có lỗi xảy ra trong quá trình compile hay không. Trường này cũng nằm trong struct parser.
Token previous;
in struct Parser
bool hadError;
} Parser;
Lúc trước tôi đã nói rằng compile() nên trả về false nếu có lỗi. Giờ chúng ta có thể làm điều đó.
consume(TOKEN_EOF, "Expect end of expression.");
in compile()
return !parser.hadError;
}
Tôi còn một flag nữa để giới thiệu cho việc xử lý lỗi. Chúng ta muốn tránh “lỗi dây chuyền”. Nếu người dùng mắc lỗi trong code và parser bị lạc vị trí trong grammar, chúng ta không muốn nó tuôn ra một đống lỗi vô nghĩa sau lỗi đầu tiên.
Chúng ta đã xử lý điều này trong jlox bằng panic mode error recovery. Trong Java interpreter, chúng ta ném một exception để thoát ra khỏi toàn bộ code parser tới một điểm mà ta có thể bỏ qua token và đồng bộ lại. Trong C, chúng ta không có exception. Thay vào đó, chúng ta sẽ dùng một chút “ảo thuật”. Chúng ta thêm một flag để theo dõi xem hiện tại có đang ở panic mode hay không.
bool hadError;
in struct Parser
bool panicMode;
} Parser;
Khi xảy ra lỗi, chúng ta bật flag này.
static void errorAt(Token* token, const char* message) {
in errorAt()
parser.panicMode = true;
fprintf(stderr, "[line %d] Error", token->line);
Sau đó, chúng ta cứ tiếp tục compile như bình thường, như thể lỗi chưa từng xảy ra. Bytecode sẽ không bao giờ được execute, nên việc tiếp tục cũng không gây hại gì. Mẹo ở đây là khi flag panic mode đang bật, chúng ta đơn giản bỏ qua mọi lỗi khác được phát hiện.
static void errorAt(Token* token, const char* message) {
in errorAt()
if (parser.panicMode) return;
parser.panicMode = true;
Có khả năng parser sẽ “đi lạc vào bụi rậm”, nhưng người dùng sẽ không biết vì tất cả lỗi đều bị nuốt mất. Panic mode kết thúc khi parser tới một điểm đồng bộ. Với Lox, chúng ta chọn ranh giới statement, nên khi sau này thêm statement vào compiler, chúng ta sẽ tắt flag ở đó.
Những trường mới này cần được khởi tạo.
initScanner(source);
in compile()
parser.hadError = false; parser.panicMode = false;
advance();
Và để hiển thị lỗi, chúng ta cần một header chuẩn.
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
Còn một hàm parsing cuối cùng, một “người bạn cũ” từ jlox.
add after advance()
static void consume(TokenType type, const char* message) { if (parser.current.type == type) { advance(); return; } errorAtCurrent(message); }
Nó giống advance() ở chỗ đọc token tiếp theo. Nhưng nó cũng kiểm tra token đó có đúng loại mong đợi hay không. Nếu không, nó báo lỗi. Hàm này là nền tảng của hầu hết các lỗi cú pháp trong compiler.
OK, vậy là đủ cho phần front-end lúc này.
17 . 3Sinh Bytecode (Emitting Bytecode)
Sau khi chúng ta parse và hiểu một phần chương trình của người dùng, bước tiếp theo là dịch nó thành một chuỗi các lệnh bytecode. Và nó bắt đầu bằng bước đơn giản nhất có thể: thêm một byte vào chunk.
add after consume()
static void emitByte(uint8_t byte) { writeChunk(currentChunk(), byte, parser.previous.line); }
Thật khó tin là những thứ “vĩ đại” lại có thể đi qua một hàm đơn giản như vậy. Nó ghi byte được truyền vào — byte này có thể là một opcode hoặc một toán hạng (operand) của một lệnh. Nó cũng gửi kèm thông tin dòng của token trước đó để khi xảy ra lỗi runtime, chúng ta biết nó gắn với dòng nào.
Chunk mà chúng ta đang ghi được truyền vào compile(), nhưng nó cần “đi” đến được emitByte(). Để làm điều đó, chúng ta dựa vào hàm trung gian này:
Parser parser;
add after variable parser
Chunk* compilingChunk; static Chunk* currentChunk() { return compilingChunk; }
static void errorAt(Token* token, const char* message) {
Hiện tại, con trỏ chunk được lưu trong một biến cấp module, giống như cách chúng ta lưu các trạng thái global khác. Sau này, khi bắt đầu compile các hàm do người dùng định nghĩa, khái niệm “current chunk” sẽ phức tạp hơn. Để tránh phải quay lại và sửa nhiều code, tôi đóng gói logic đó vào hàm currentChunk().
Chúng ta khởi tạo biến module mới này trước khi ghi bất kỳ bytecode nào:
bool compile(const char* source, Chunk* chunk) {
initScanner(source);
in compile()
compilingChunk = chunk;
parser.hadError = false;
Rồi, ở cuối cùng, khi compile xong chunk, chúng ta kết thúc mọi thứ.
consume(TOKEN_EOF, "Expect end of expression.");
in compile()
endCompiler();
return !parser.hadError;
Hàm này gọi đến:
add after emitByte()
static void endCompiler() { emitReturn(); }
Trong chương này, VM của chúng ta chỉ xử lý biểu thức. Khi bạn chạy clox, nó sẽ parse, compile và execute một biểu thức duy nhất, rồi in kết quả. Để in giá trị đó, tạm thời chúng ta dùng lệnh OP_RETURN. Vì vậy, compiler sẽ thêm một lệnh như vậy vào cuối chunk.
add after emitByte()
static void emitReturn() { emitByte(OP_RETURN); }
Nhân tiện đang ở phần back end, ta cũng có thể làm cho cuộc sống dễ dàng hơn một chút.
add after emitByte()
static void emitBytes(uint8_t byte1, uint8_t byte2) { emitByte(byte1); emitByte(byte2); }
Theo thời gian, chúng ta sẽ gặp đủ nhiều trường hợp cần ghi một opcode theo sau bởi một toán hạng một byte, nên đáng để định nghĩa một hàm tiện ích như thế này.
17 . 4Parsing các biểu thức Prefix
Chúng ta đã tập hợp xong các hàm tiện ích cho parsing và code generation. Mảnh ghép còn thiếu là đoạn code ở giữa để kết nối chúng lại.

Bước duy nhất trong compile() mà chúng ta còn chưa triển khai là hàm này:
add after endCompiler()
static void expression() { // What goes here? }
Chúng ta chưa sẵn sàng để triển khai mọi loại biểu thức trong Lox. Thậm chí, chúng ta còn chưa có Boolean. Trong chương này, chúng ta chỉ quan tâm đến bốn loại:
- Số literal:
123 - Dấu ngoặc đơn để nhóm:
(123) - Phủ định đơn ngôi (unary negation):
-123 - “Bốn kỵ sĩ” của số học:
+,-,*,/
Khi chúng ta lần lượt viết hàm compile cho từng loại biểu thức này, chúng ta cũng sẽ xây dựng dần các yêu cầu cho table-driven parser sẽ gọi chúng.
17 . 4 . 1Parser cho token
Trước mắt, hãy tập trung vào các biểu thức Lox mà mỗi cái chỉ gồm một token duy nhất. Trong chương này, đó chỉ là số literal, nhưng sau này sẽ có thêm. Đây là cách chúng ta compile chúng:
Chúng ta ánh xạ mỗi loại token sang một loại biểu thức khác nhau. Chúng ta định nghĩa một hàm cho mỗi loại biểu thức để xuất ra bytecode phù hợp. Sau đó, chúng ta tạo một mảng con trỏ hàm. Các chỉ số trong mảng tương ứng với giá trị enum TokenType, và hàm ở mỗi chỉ số là code để compile một biểu thức của loại token đó.
Để compile số literal, chúng ta lưu con trỏ đến hàm sau tại chỉ số TOKEN_NUMBER trong mảng.
add after endCompiler()
static void number() { double value = strtod(parser.previous.start, NULL); emitConstant(value); }
Chúng ta giả định token của số literal đã được tiêu thụ và lưu trong previous. Chúng ta lấy lexeme đó và dùng thư viện chuẩn C để chuyển nó thành giá trị double. Sau đó, chúng ta sinh code để load giá trị đó bằng hàm này:
add after emitReturn()
static void emitConstant(Value value) { emitBytes(OP_CONSTANT, makeConstant(value)); }
Đầu tiên, chúng ta thêm giá trị vào bảng constant, rồi phát ra lệnh OP_CONSTANT để đẩy nó lên stack khi runtime. Để chèn một mục vào bảng constant, chúng ta dùng:
add after emitReturn()
static uint8_t makeConstant(Value value) { int constant = addConstant(currentChunk(), value); if (constant > UINT8_MAX) { error("Too many constants in one chunk."); return 0; } return (uint8_t)constant; }
Phần lớn công việc diễn ra trong addConstant(), hàm mà chúng ta đã định nghĩa ở chương trước. Hàm đó thêm giá trị được truyền vào cuối bảng constant của chunk và trả về chỉ số của nó. Nhiệm vụ chính của hàm mới này là đảm bảo chúng ta không có quá nhiều constant. Vì lệnh OP_CONSTANT dùng một byte cho toán hạng chỉ số, chúng ta chỉ có thể lưu và load tối đa 256 constant trong một chunk.
Về cơ bản, chỉ cần vậy thôi. Miễn là có code phù hợp để tiêu thụ token TOKEN_NUMBER, tra hàm number() trong mảng con trỏ hàm, rồi gọi nó, chúng ta đã có thể compile số literal thành bytecode.
17 . 4 . 2Dấu ngoặc đơn để nhóm (Parentheses for grouping)
Mảng con trỏ hàm parsing “tưởng tượng” của chúng ta sẽ tuyệt vời nếu mọi biểu thức chỉ dài đúng một token. Tiếc là hầu hết lại dài hơn. Tuy nhiên, nhiều biểu thức bắt đầu bằng một token cụ thể. Chúng ta gọi chúng là biểu thức prefix. Ví dụ, khi đang parse một biểu thức và token hiện tại là (, ta biết chắc mình đang gặp một biểu thức nhóm trong ngoặc.
Hóa ra mảng con trỏ hàm của chúng ta cũng xử lý được những trường hợp này. Hàm parsing cho một loại biểu thức có thể tiêu thụ thêm bất kỳ token nào nó muốn, giống như trong một recursive descent parser thông thường. Đây là cách xử lý dấu ngoặc:
add after endCompiler()
static void grouping() { expression(); consume(TOKEN_RIGHT_PAREN, "Expect ')' after expression."); }
Một lần nữa, chúng ta giả định dấu ( ban đầu đã được tiêu thụ. Chúng ta gọi đệ quy lại vào expression() để compile biểu thức bên trong ngoặc, rồi parse dấu ) đóng ở cuối.
Về phía back end, một biểu thức nhóm thực sự chẳng có gì cả. Chức năng duy nhất của nó là cú pháp — cho phép bạn chèn một biểu thức có precedence thấp vào chỗ mà precedence cao hơn được mong đợi. Vì vậy, nó không có ngữ nghĩa runtime riêng và không phát ra bytecode nào. Lời gọi expression() bên trong sẽ lo việc sinh bytecode cho biểu thức nằm trong ngoặc.
17 . 4 . 3Phủ định đơn ngôi (Unary negation)
Dấu trừ đơn ngôi (unary minus) cũng là một biểu thức prefix, nên nó cũng hoạt động với mô hình của chúng ta.
add after number()
static void unary() { TokenType operatorType = parser.previous.type; // Compile the operand. expression(); // Emit the operator instruction. switch (operatorType) { case TOKEN_MINUS: emitByte(OP_NEGATE); break; default: return; // Unreachable. } }
Token - ở đầu đã được tiêu thụ và đang nằm trong parser.previous. Chúng ta lấy loại token từ đó để biết mình đang xử lý toán tử unary nào. Hiện tại thì chưa cần thiết, nhưng điều này sẽ hợp lý hơn khi chúng ta dùng cùng hàm này để compile toán tử ! trong chương tiếp theo.
Giống như trong grouping(), chúng ta gọi đệ quy expression() để compile toán hạng. Sau đó, chúng ta phát bytecode để thực hiện phép phủ định. Có thể bạn thấy hơi lạ khi ghi lệnh negate sau bytecode của toán hạng, vì dấu - xuất hiện bên trái, nhưng hãy nghĩ theo thứ tự execute:
- Ta đánh giá toán hạng trước, để lại giá trị của nó trên stack.
- Sau đó, ta pop giá trị đó, phủ định nó, rồi push kết quả.
Vì vậy, lệnh OP_NEGATE nên được phát ra cuối cùng. Đây là một phần công việc của compiler — parse chương trình theo thứ tự xuất hiện trong source code và sắp xếp lại thành thứ tự execute.
Tuy nhiên, có một vấn đề với đoạn code này. Hàm expression() mà nó gọi sẽ parse bất kỳ biểu thức nào làm toán hạng, bất kể precedence. Khi chúng ta thêm toán tử nhị phân và cú pháp khác, điều này sẽ gây lỗi. Xem ví dụ:
-a.b + c;
Ở đây, toán hạng của - chỉ nên là biểu thức a.b, không phải toàn bộ a.b + c. Nhưng nếu unary() gọi expression(), hàm này sẽ “ăn” hết phần còn lại, bao gồm cả +. Nó sẽ sai khi coi - có precedence thấp hơn +.
Khi parse toán hạng cho unary -, chúng ta cần compile chỉ những biểu thức ở một mức precedence nhất định hoặc cao hơn. Trong recursive descent parser của jlox, chúng ta làm điều đó bằng cách gọi vào hàm parse cho loại biểu thức có precedence thấp nhất mà ta muốn cho phép (trong trường hợp này là call()). Mỗi hàm parse một loại biểu thức cụ thể cũng sẽ parse luôn các loại có precedence cao hơn, nên bao trùm cả phần còn lại của bảng precedence.
Các hàm parsing như number() và unary() ở clox thì khác. Mỗi hàm chỉ parse đúng một loại biểu thức. Chúng không “xâu chuỗi” để bao gồm các loại có precedence cao hơn. Chúng ta cần một giải pháp khác, và nó trông như thế này:
add after unary()
static void parsePrecedence(Precedence precedence) { // What goes here? }
Hàm này — khi được triển khai — sẽ bắt đầu từ token hiện tại và parse bất kỳ biểu thức nào ở mức precedence cho trước hoặc cao hơn. Chúng ta sẽ cần chuẩn bị thêm trước khi viết thân hàm này, nhưng bạn có thể đoán rằng nó sẽ dùng bảng con trỏ hàm parsing mà tôi đã nhắc đến. Tạm thời, đừng lo quá nhiều về cách nó hoạt động. Để truyền “precedence” làm tham số, chúng ta định nghĩa nó dưới dạng số.
} Parser;
add after struct Parser
typedef enum { PREC_NONE, PREC_ASSIGNMENT, // = PREC_OR, // or PREC_AND, // and PREC_EQUALITY, // == != PREC_COMPARISON, // < > <= >= PREC_TERM, // + - PREC_FACTOR, // * / PREC_UNARY, // ! - PREC_CALL, // . () PREC_PRIMARY } Precedence;
Parser parser;
Đây là toàn bộ các mức precedence của Lox, từ thấp đến cao. Vì C tự động gán số tăng dần cho enum, điều này có nghĩa là PREC_CALL có giá trị số lớn hơn PREC_UNARY. Ví dụ, giả sử compiler đang xử lý đoạn code:
-a.b + c
Nếu ta gọi parsePrecedence(PREC_ASSIGNMENT), nó sẽ parse toàn bộ biểu thức vì + có precedence cao hơn assignment. Nếu thay vào đó ta gọi parsePrecedence(PREC_UNARY), nó sẽ compile -a.b và dừng lại. Nó không tiếp tục qua + vì phép cộng có precedence thấp hơn toán tử unary.
Với hàm này, việc bổ sung phần thân còn thiếu cho expression() trở nên dễ dàng.
static void expression() {
in expression()
replace 1 line
parsePrecedence(PREC_ASSIGNMENT);
}
Chúng ta chỉ cần parse mức precedence thấp nhất, vốn bao gồm tất cả các biểu thức có precedence cao hơn. Giờ, để compile toán hạng cho một biểu thức unary, ta gọi hàm mới này và giới hạn ở mức phù hợp:
// Compile the operand.
in unary()
replace 1 line
parsePrecedence(PREC_UNARY);
// Emit the operator instruction.
Chúng ta dùng chính precedence PREC_UNARY của toán tử unary để cho phép lồng các biểu thức unary như !!doubleNegative. Vì toán tử unary có precedence khá cao, điều này sẽ loại trừ đúng các toán tử nhị phân. Nói đến đây thì…
17 . 5Parsing các biểu thức Infix
Các toán tử nhị phân (binary operators) khác với những biểu thức trước đó vì chúng là infix. Với các biểu thức khác, chúng ta biết mình đang parse cái gì ngay từ token đầu tiên. Nhưng với biểu thức infix, ta sẽ không biết mình đang ở giữa một toán tử nhị phân cho đến sau khi đã parse toán hạng bên trái, rồi mới “đụng” vào token toán tử nằm ở giữa.
Ví dụ:
1 + 2
Hãy thử đi qua quá trình compile nó với những gì ta biết đến giờ:
-
Ta gọi
expression(). Hàm này lại gọi
parsePrecedence(PREC_ASSIGNMENT). -
Hàm đó (khi được triển khai) sẽ thấy token số ở đầu và nhận ra ta đang parse một số literal. Nó chuyển quyền điều khiển sang
number(). -
number()tạo một constant, phát lệnhOP_CONSTANT, rồi trả vềparsePrecedence().
Rồi sao nữa? Lời gọi parsePrecedence() phải tiêu thụ toàn bộ biểu thức cộng, nên nó cần tiếp tục bằng cách nào đó. May mắn là parser đang ở đúng vị trí ta cần. Sau khi compile xong biểu thức số ở đầu, token tiếp theo là +. Đây chính xác là token mà parsePrecedence() cần để phát hiện rằng ta đang ở giữa một biểu thức infix và nhận ra rằng biểu thức vừa compile thực ra là toán hạng của nó.
Vì vậy, mảng con trỏ hàm “tưởng tượng” này không chỉ liệt kê các hàm parse biểu thức bắt đầu bằng một token nhất định. Thay vào đó, nó là một bảng con trỏ hàm. Một cột ánh xạ các hàm parser prefix với loại token. Cột thứ hai ánh xạ các hàm parser infix với loại token.
Hàm mà chúng ta sẽ dùng làm infix parser cho TOKEN_PLUS, TOKEN_MINUS, TOKEN_STAR và TOKEN_SLASH là:
add after endCompiler()
static void binary() { TokenType operatorType = parser.previous.type; ParseRule* rule = getRule(operatorType); parsePrecedence((Precedence)(rule->precedence + 1)); switch (operatorType) { case TOKEN_PLUS: emitByte(OP_ADD); break; case TOKEN_MINUS: emitByte(OP_SUBTRACT); break; case TOKEN_STAR: emitByte(OP_MULTIPLY); break; case TOKEN_SLASH: emitByte(OP_DIVIDE); break; default: return; // Unreachable. } }
Khi một hàm parser prefix được gọi, token dẫn đầu đã được tiêu thụ. Một hàm parser infix thì còn “in medias res” hơn nữa — toàn bộ biểu thức toán hạng bên trái đã được compile và toán tử infix tiếp theo cũng đã được tiêu thụ.
Việc toán hạng bên trái được compile trước là hoàn toàn ổn. Điều đó có nghĩa là khi runtime, đoạn code đó sẽ được execute trước. Khi chạy, giá trị nó tạo ra sẽ nằm trên stack — đúng chỗ mà toán tử infix cần.
Sau đó, ta đến binary() để xử lý phần còn lại của các toán tử số học. Hàm này compile toán hạng bên phải, tương tự như cách unary() compile toán hạng của nó. Cuối cùng, nó phát bytecode thực hiện phép toán nhị phân.
Khi chạy, VM sẽ execute code của toán hạng trái và phải, theo thứ tự đó, để lại giá trị của chúng trên stack. Sau đó, nó execute lệnh của toán tử. Lệnh này pop hai giá trị, tính toán, rồi push kết quả.
Đoạn code có lẽ khiến bạn chú ý ở đây là dòng getRule(). Khi parse toán hạng bên phải, ta lại phải quan tâm đến precedence. Xem ví dụ:
2 * 3 + 4
Khi parse toán hạng bên phải của biểu thức *, ta chỉ cần lấy 3, chứ không phải 3 + 4, vì + có precedence thấp hơn *. Ta có thể định nghĩa một hàm riêng cho mỗi toán tử nhị phân, mỗi hàm sẽ gọi parsePrecedence() và truyền vào mức precedence đúng cho toán hạng của nó.
Nhưng như vậy thì khá tẻ nhạt. Precedence của toán hạng bên phải của mỗi toán tử nhị phân luôn cao hơn một mức so với chính nó. Ta có thể tra điều đó một cách động bằng getRule() (sẽ nói sau). Dùng cách này, ta gọi parsePrecedence() với mức cao hơn một bậc so với toán tử hiện tại.
Bằng cách này, ta có thể dùng một hàm binary() duy nhất cho tất cả các toán tử nhị phân, dù chúng có precedence khác nhau.
17 . 6Pratt Parser
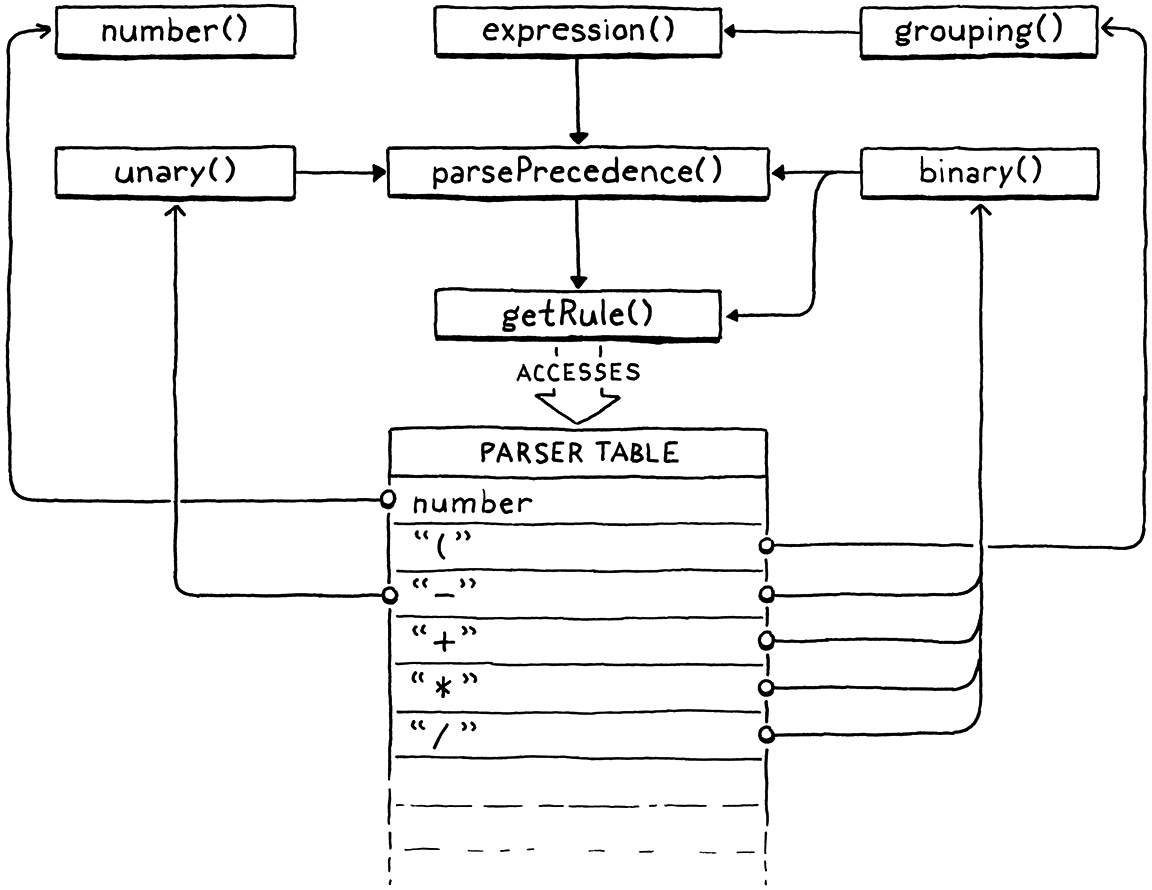
Giờ thì chúng ta đã có đầy đủ các mảnh ghép của compiler. Chúng ta có một hàm cho mỗi production trong grammar: number(), grouping(), unary() và binary(). Chúng ta vẫn cần triển khai parsePrecedence() và getRule(). Chúng ta cũng biết mình cần một bảng mà, khi cho vào một loại token, sẽ cho phép tìm được:
- Hàm compile một biểu thức prefix bắt đầu bằng token thuộc loại đó.
- Hàm compile một biểu thức infix mà toán hạng bên trái theo sau bởi token thuộc loại đó.
- Precedence của một biểu thức infix dùng token đó làm toán tử.
Chúng ta gói gọn ba thuộc tính này trong một struct nhỏ, đại diện cho một hàng trong bảng parser.
} Precedence;
add after enum Precedence
typedef struct { ParseFn prefix; ParseFn infix; Precedence precedence; } ParseRule;
Parser parser;
Kiểu ParseFn chỉ là một typedef đơn giản cho một kiểu hàm không nhận tham số và không trả về giá trị.
} Precedence;
add after enum Precedence
typedef void (*ParseFn)();
typedef struct {
Bảng điều khiển toàn bộ parser của chúng ta là một mảng ParseRule. Chúng ta đã nói về nó mãi rồi, và cuối cùng bạn cũng được thấy nó.
add after unary()
ParseRule rules[] = { [TOKEN_LEFT_PAREN] = {grouping, NULL, PREC_NONE}, [TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE}, [TOKEN_LEFT_BRACE] = {NULL, NULL, PREC_NONE}, [TOKEN_RIGHT_BRACE] = {NULL, NULL, PREC_NONE}, [TOKEN_COMMA] = {NULL, NULL, PREC_NONE}, [TOKEN_DOT] = {NULL, NULL, PREC_NONE}, [TOKEN_MINUS] = {unary, binary, PREC_TERM}, [TOKEN_PLUS] = {NULL, binary, PREC_TERM}, [TOKEN_SEMICOLON] = {NULL, NULL, PREC_NONE}, [TOKEN_SLASH] = {NULL, binary, PREC_FACTOR}, [TOKEN_STAR] = {NULL, binary, PREC_FACTOR}, [TOKEN_BANG] = {NULL, NULL, PREC_NONE}, [TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_EQUAL_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_GREATER] = {NULL, NULL, PREC_NONE}, [TOKEN_GREATER_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_LESS] = {NULL, NULL, PREC_NONE}, [TOKEN_LESS_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE}, [TOKEN_STRING] = {NULL, NULL, PREC_NONE}, [TOKEN_NUMBER] = {number, NULL, PREC_NONE}, [TOKEN_AND] = {NULL, NULL, PREC_NONE}, [TOKEN_CLASS] = {NULL, NULL, PREC_NONE}, [TOKEN_ELSE] = {NULL, NULL, PREC_NONE}, [TOKEN_FALSE] = {NULL, NULL, PREC_NONE}, [TOKEN_FOR] = {NULL, NULL, PREC_NONE}, [TOKEN_FUN] = {NULL, NULL, PREC_NONE}, [TOKEN_IF] = {NULL, NULL, PREC_NONE}, [TOKEN_NIL] = {NULL, NULL, PREC_NONE}, [TOKEN_OR] = {NULL, NULL, PREC_NONE}, [TOKEN_PRINT] = {NULL, NULL, PREC_NONE}, [TOKEN_RETURN] = {NULL, NULL, PREC_NONE}, [TOKEN_SUPER] = {NULL, NULL, PREC_NONE}, [TOKEN_THIS] = {NULL, NULL, PREC_NONE}, [TOKEN_TRUE] = {NULL, NULL, PREC_NONE}, [TOKEN_VAR] = {NULL, NULL, PREC_NONE}, [TOKEN_WHILE] = {NULL, NULL, PREC_NONE}, [TOKEN_ERROR] = {NULL, NULL, PREC_NONE}, [TOKEN_EOF] = {NULL, NULL, PREC_NONE}, };
Bạn có thể thấy grouping và unary được đặt vào cột parser prefix cho các loại token tương ứng. Ở cột tiếp theo, binary được gắn với bốn toán tử số học infix. Các toán tử infix này cũng được thiết lập precedence ở cột cuối.
Ngoài những cái đó, phần còn lại của bảng đầy NULL và PREC_NONE. Hầu hết các ô trống này là vì không có biểu thức nào gắn với các token đó. Bạn không thể bắt đầu một biểu thức bằng, ví dụ, else, và } thì sẽ là một toán tử infix khá khó hiểu.
Ngoài ra, chúng ta vẫn chưa hoàn thiện toàn bộ grammar. Ở các chương sau, khi thêm các loại biểu thức mới, một số ô này sẽ được gán hàm. Một điều tôi thích ở cách tiếp cận parsing này là nó giúp dễ dàng thấy token nào đang được grammar sử dụng và token nào còn trống.
Giờ khi đã có bảng, chúng ta cuối cùng cũng sẵn sàng viết code để dùng nó. Đây là lúc Pratt parser của chúng ta “sống” dậy. Hàm dễ định nghĩa nhất là getRule().
add after parsePrecedence()
static ParseRule* getRule(TokenType type) { return &rules[type]; }
Hàm này đơn giản chỉ trả về rule ở chỉ số được cho. Nó được binary() gọi để tra precedence của toán tử hiện tại. Hàm này tồn tại chỉ để xử lý vòng lặp khai báo (declaration cycle) trong code C. binary() được định nghĩa trước bảng rules để bảng có thể lưu con trỏ tới nó. Điều đó có nghĩa là phần thân của binary() không thể truy cập trực tiếp bảng.
Thay vào đó, chúng ta gói thao tác tra cứu vào một hàm. Cách này cho phép chúng ta forward declare getRule() trước khi định nghĩa binary(), và sau đó định nghĩa getRule() sau bảng. Chúng ta sẽ cần thêm một vài forward declaration khác để xử lý việc grammar của chúng ta là đệ quy, nên hãy làm hết chúng luôn.
emitReturn(); }
add after endCompiler()
static void expression(); static ParseRule* getRule(TokenType type); static void parsePrecedence(Precedence precedence);
static void binary() {
Nếu bạn đang làm theo và tự triển khai clox, hãy chú ý kỹ các ghi chú nhỏ cho biết bạn nên đặt các đoạn code này ở đâu. Nhưng đừng lo, nếu bạn đặt sai, C compiler sẽ vui vẻ báo cho bạn biết.
17 . 6 . 1Parsing với precedence
Giờ thì chúng ta đến phần thú vị đây. “Nhạc trưởng” điều phối tất cả các hàm parsing mà ta đã định nghĩa chính là parsePrecedence(). Hãy bắt đầu với việc parse các biểu thức prefix.
static void parsePrecedence(Precedence precedence) {
in parsePrecedence()
replace 1 line
advance(); ParseFn prefixRule = getRule(parser.previous.type)->prefix; if (prefixRule == NULL) { error("Expect expression."); return; } prefixRule();
}
Chúng ta đọc token tiếp theo và tra ParseRule tương ứng. Nếu không có prefix parser, thì token đó chắc chắn là một lỗi cú pháp. Ta báo lỗi và trả về cho hàm gọi.
Ngược lại, ta gọi hàm prefix parser đó và để nó làm phần việc của mình. Prefix parser sẽ compile phần còn lại của biểu thức prefix, tiêu thụ bất kỳ token nào nó cần, rồi trả về đây. Biểu thức infix mới là nơi mọi thứ trở nên thú vị vì precedence bắt đầu đóng vai trò. Việc triển khai lại cực kỳ đơn giản.
prefixRule();
in parsePrecedence()
while (precedence <= getRule(parser.current.type)->precedence) { advance(); ParseFn infixRule = getRule(parser.previous.type)->infix; infixRule(); }
}
Đó là toàn bộ. Thật đấy. Đây là cách toàn bộ hàm hoạt động: Ở đầu parsePrecedence(), ta tìm prefix parser cho token hiện tại. Theo định nghĩa, token đầu tiên luôn thuộc về một dạng biểu thức prefix nào đó. Nó có thể nằm lồng bên trong như một toán hạng của một hoặc nhiều biểu thức infix, nhưng khi đọc code từ trái sang phải, token đầu tiên bạn gặp luôn thuộc về một biểu thức prefix.
Sau khi parse xong (có thể tiêu thụ thêm nhiều token), biểu thức prefix kết thúc. Giờ ta tìm infix parser cho token tiếp theo. Nếu tìm thấy, điều đó có nghĩa là biểu thức prefix vừa compile có thể là toán hạng của nó. Nhưng chỉ khi lời gọi parsePrecedence() có precedence đủ thấp để cho phép toán tử infix đó.
Nếu token tiếp theo có precedence quá thấp, hoặc không phải toán tử infix, thì xong — ta đã parse được tối đa phần biểu thức có thể. Ngược lại, ta tiêu thụ toán tử và chuyển quyền điều khiển cho infix parser vừa tìm được. Nó sẽ tiêu thụ các token cần thiết khác (thường là toán hạng bên phải) rồi trả về parsePrecedence(). Sau đó, ta lặp lại: kiểm tra xem token tiếp theo có phải là toán tử infix hợp lệ có thể lấy toàn bộ biểu thức trước đó làm toán hạng hay không. Ta cứ lặp như vậy, xử lý các toán tử infix và toán hạng của chúng cho đến khi gặp một token không phải infix hoặc có precedence quá thấp thì dừng.
Nghe thì dài dòng, nhưng nếu bạn thật sự muốn “đồng bộ não” với Vaughan Pratt và hiểu trọn vẹn thuật toán, hãy bước qua parser trong debugger khi nó xử lý một vài biểu thức. Có lẽ một bức hình sẽ giúp. Chỉ có vài hàm thôi, nhưng chúng liên kết với nhau cực kỳ chặt chẽ:
Sau này, chúng ta sẽ cần chỉnh lại code trong chương này để xử lý assignment. Nhưng ngoài ra, những gì ta đã viết đã bao quát toàn bộ nhu cầu compile biểu thức cho phần còn lại của cuốn sách. Khi thêm các loại biểu thức mới, ta sẽ cắm thêm các hàm parsing vào bảng, nhưng parsePrecedence() thì đã hoàn chỉnh.
17 . 7Dumping Chunks
Nhân tiện đang ở phần lõi của compiler, ta nên thêm một chút “đo đạc” (instrumentation). Để giúp debug bytecode được generated, ta sẽ thêm khả năng dump chunk sau khi compiler hoàn tất. Trước đây ta có vài log tạm khi tự viết chunk bằng tay. Giờ ta sẽ thêm code thực sự để có thể bật nó bất cứ khi nào muốn.
Vì đây không phải tính năng cho người dùng cuối, ta ẩn nó sau một flag.
#include <stdint.h>
#define DEBUG_PRINT_CODE
#define DEBUG_TRACE_EXECUTION
Khi flag đó được bật, ta dùng module “debug” sẵn có để in ra bytecode của chunk.
emitReturn();
in endCompiler()
#ifdef DEBUG_PRINT_CODE if (!parser.hadError) { disassembleChunk(currentChunk(), "code"); } #endif
}
Ta chỉ làm điều này nếu code không có lỗi. Sau một lỗi cú pháp, compiler vẫn tiếp tục chạy nhưng ở trạng thái hơi “kỳ quặc” và có thể sinh ra code hỏng. Điều đó không gây hại vì code sẽ không được execute, nhưng nếu ta cố đọc nó thì chỉ tự làm mình rối.
Cuối cùng, để truy cập disassembleChunk(), ta cần include header của nó.
#include "scanner.h"
#ifdef DEBUG_PRINT_CODE #include "debug.h" #endif
typedef struct {
Vậy là xong! Đây là phần lớn cuối cùng cần lắp vào pipeline compile và execute của VM. Interpreter của chúng ta nhìn bề ngoài thì chẳng có gì đặc biệt, nhưng bên trong nó đang scanning, parsing, compile thành bytecode và execute.
Hãy khởi động VM và gõ vào một biểu thức. Nếu mọi thứ đúng, nó sẽ tính toán và in ra kết quả. Giờ ta đã có một “máy tính số học” được thiết kế quá mức cần thiết. Còn rất nhiều tính năng ngôn ngữ sẽ được thêm trong các chương tới, nhưng nền móng đã sẵn sàng.
17 . 8Thử thách
-
Để thật sự hiểu parser, bạn cần thấy luồng execute đi qua các hàm parsing thú vị —
parsePrecedence()và các hàm parser được lưu trong bảng. Hãy lấy ví dụ biểu thức (hơi kỳ lạ) này:(-1 + 2) * 3 - -4
Hãy viết một bản trace cho thấy các hàm đó được gọi như thế nào. Thể hiện thứ tự gọi, hàm nào gọi hàm nào, và các tham số được truyền vào.
-
Hàng ParseRule cho
TOKEN_MINUScó cả con trỏ hàm prefix và infix. Đó là vì-vừa là toán tử prefix (phủ định đơn ngôi) vừa là toán tử infix (phép trừ).Trong ngôn ngữ Lox đầy đủ, còn token nào có thể được dùng ở cả vị trí prefix và infix? Còn trong C hoặc một ngôn ngữ khác mà bạn chọn thì sao?
-
Bạn có thể đang thắc mắc về các biểu thức “mixfix” phức tạp có nhiều hơn hai toán hạng được ngăn cách bởi các token. Toán tử điều kiện hay “ternary” của C,
?:, là một ví dụ nổi tiếng.Hãy thêm hỗ trợ cho toán tử đó vào compiler. Bạn không cần sinh ra bytecode, chỉ cần cho thấy cách bạn sẽ kết nối nó vào parser và xử lý các toán hạng.
17 . 9Ghi chú thiết kế: Chỉ là Parsing thôi mà
Tôi sắp đưa ra một nhận định mà có thể sẽ không được lòng một số người làm compiler và ngôn ngữ. Không sao nếu bạn không đồng ý. Cá nhân tôi học được nhiều hơn từ những ý kiến mạnh mẽ mà tôi không đồng tình so với việc đọc vài trang toàn là điều kiện và rào đón. Nhận định của tôi là parsing không quan trọng.
Nhiều năm qua, nhiều người làm ngôn ngữ lập trình, đặc biệt trong giới học thuật, đã rất mê mẩn parser và coi nó cực kỳ nghiêm túc. Ban đầu, đó là những người làm compiler đắm chìm trong compiler-compilers, LALR, và các thứ tương tự. Nửa đầu của cuốn dragon book là một bức thư tình dài gửi đến vẻ đẹp của các parser generator.
Sau đó, dân lập trình hàm (functional programming) lại mê parser combinator, packrat parser, và các kiểu khác. Vì rõ ràng, nếu bạn đưa cho một lập trình viên hàm một vấn đề, việc đầu tiên họ làm là rút ra một túi đầy các hàm bậc cao.
Bên lĩnh vực toán và phân tích thuật toán, có cả một di sản nghiên cứu lâu dài về việc chứng minh thời gian và bộ nhớ sử dụng cho các kỹ thuật parsing khác nhau, biến đổi bài toán parsing thành các bài toán khác và ngược lại, và gán các lớp độ phức tạp cho các grammar khác nhau.
Ở một mức độ nào đó, những thứ này là quan trọng. Nếu bạn đang triển khai một ngôn ngữ, bạn muốn chắc chắn parser của mình sẽ không rơi vào độ phức tạp hàm mũ và mất 7.000 năm để parse một trường hợp biên kỳ quặc nào đó trong grammar. Lý thuyết parser cho bạn giới hạn đó. Và như một bài tập trí tuệ, học về các kỹ thuật parsing cũng thú vị và bổ ích.
Nhưng nếu mục tiêu của bạn chỉ là triển khai một ngôn ngữ và đưa nó đến tay người dùng, thì gần như tất cả những thứ đó không quan trọng. Rất dễ bị cuốn theo sự hào hứng của những người thật sự mê nó và nghĩ rằng front end của bạn cần một thứ gì đó hoành tráng kiểu combinator-parser-factory sinh tự động. Tôi đã thấy nhiều người tốn vô số thời gian viết đi viết lại parser của họ bằng bất kỳ thư viện hay kỹ thuật “hot” nào của ngày hôm đó.
Đó là khoảng thời gian không mang lại giá trị gì cho người dùng của bạn. Nếu bạn chỉ muốn parser của mình chạy được, hãy chọn một trong những kỹ thuật tiêu chuẩn, dùng nó, và tiếp tục. Recursive descent, Pratt parsing, và các parser generator phổ biến như ANTLR hoặc Bison đều ổn cả.
Hãy dùng khoảng thời gian bạn tiết kiệm được nhờ không viết lại code parser để cải thiện thông báo lỗi compile mà compiler của bạn hiển thị cho người dùng. Xử lý và báo lỗi tốt có giá trị với người dùng hơn gần như bất kỳ thứ gì khác mà bạn có thể đầu tư thời gian vào ở phần front end.