Types of Values
Khi bạn là một chú Gấu với Bộ Não Rất Nhỏ, và bạn Nghĩ Về Những Điều, đôi khi bạn nhận ra rằng một Điều trông rất “ra dáng Điều” bên trong bạn lại hoàn toàn khác khi nó ra ngoài và có người khác nhìn vào.
A. A. Milne, Winnie-the-Pooh
Những chương vừa qua thật đồ sộ, chứa đầy các kỹ thuật phức tạp và hàng trang code. Trong chương này, chỉ có một khái niệm mới để học và một ít code đơn giản. Bạn xứng đáng được nghỉ ngơi đôi chút.
Lox là ngôn ngữ dynamically typed. Một biến duy nhất có thể chứa Boolean, số hoặc chuỗi ở những thời điểm khác nhau. Ít nhất, đó là ý tưởng. Hiện tại, trong clox, tất cả giá trị đều là số. Đến cuối chương này, nó sẽ hỗ trợ thêm Boolean và nil. Dù những thứ này không quá thú vị, chúng buộc chúng ta phải tìm ra cách để cách biểu diễn giá trị (value representation) có thể xử lý động nhiều kiểu dữ liệu khác nhau.
18 . 1Tagged Unions
Điều hay khi lập trình bằng C là chúng ta có thể xây dựng cấu trúc dữ liệu từ những bit thô. Điều dở là chúng ta phải làm vậy. C không cho bạn nhiều thứ “miễn phí” khi biên dịch và còn ít hơn khi chạy. Với C, vũ trụ chỉ là một mảng byte không phân biệt. Chúng ta phải tự quyết định dùng bao nhiêu byte và ý nghĩa của chúng.
Để chọn cách biểu diễn giá trị, ta cần trả lời hai câu hỏi chính:
-
Làm sao để biểu diễn kiểu của một giá trị? Nếu bạn thử nhân một số với
true, ta cần phát hiện lỗi đó khi runtime và báo ra. Để làm được, ta phải biết kiểu của giá trị đó là gì. -
Làm sao để lưu trữ bản thân giá trị? Ta không chỉ cần biết rằng số ba là một số, mà còn phải phân biệt nó với số bốn. Nghe hiển nhiên, đúng không? Nhưng ở mức này, tốt nhất là nói rõ ra.
Vì chúng ta không chỉ thiết kế ngôn ngữ mà còn tự xây dựng nó, khi trả lời hai câu hỏi này ta cũng phải nhớ đến mục tiêu muôn thuở của người cài đặt: làm sao cho hiệu quả.
Các “hacker” ngôn ngữ qua nhiều năm đã nghĩ ra đủ cách thông minh để nhét thông tin trên vào ít bit nhất có thể. Trước mắt, ta sẽ bắt đầu với giải pháp cổ điển, đơn giản nhất: tagged union. Một giá trị gồm hai phần: một “tag” kiểu, và phần payload chứa giá trị thực. Để lưu kiểu của giá trị, ta định nghĩa một enum cho mỗi loại giá trị mà VM hỗ trợ.
#include "common.h"
typedef enum { VAL_BOOL, VAL_NIL, VAL_NUMBER, } ValueType;
typedef double Value;
Hiện tại, ta chỉ có vài case, nhưng danh sách này sẽ tăng khi ta thêm strings, functions và classes vào clox. Ngoài kiểu, ta cũng cần lưu dữ liệu của giá trị — double cho số, true hoặc false cho Boolean. Ta có thể định nghĩa một struct với các field cho mỗi kiểu có thể.

Nhưng như vậy sẽ lãng phí bộ nhớ. Một giá trị không thể đồng thời vừa là số vừa là Boolean. Tại một thời điểm, chỉ một field được dùng. C cho phép tối ưu bằng cách định nghĩa union. Union trông giống struct nhưng tất cả field chồng lên nhau trong bộ nhớ.
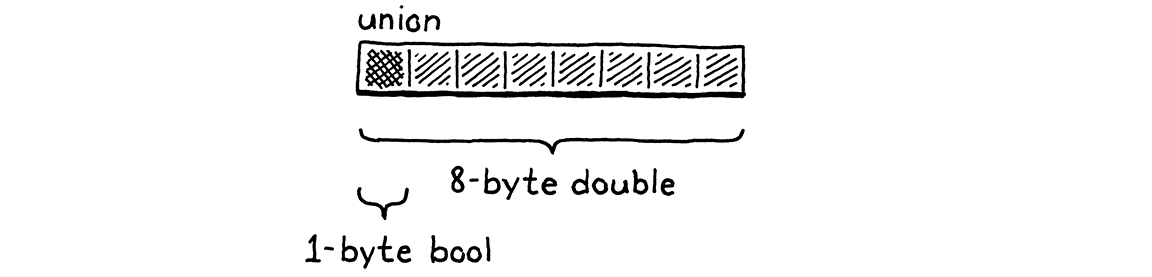
Kích thước của union bằng kích thước field lớn nhất. Vì các field dùng chung bit, bạn phải rất cẩn thận khi làm việc với chúng. Nếu bạn lưu dữ liệu bằng một field rồi truy cập nó bằng field khác, bạn sẽ diễn giải lại ý nghĩa của các bit bên dưới.
Đúng như tên gọi “tagged union”, cách biểu diễn giá trị mới của ta kết hợp hai phần này vào một struct duy nhất.
} ValueType;
add after enum ValueType
replace 1 line
typedef struct { ValueType type; union { bool boolean; double number; } as; } Value;
typedef struct {
Có một field cho type tag, và một field thứ hai chứa union của tất cả các giá trị bên dưới. Trên máy 64-bit với trình biên dịch C thông thường, bố cục trông như sau:
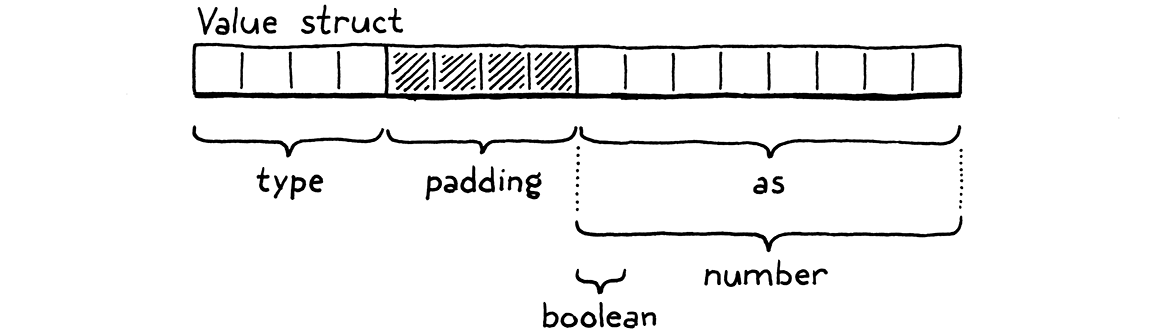
Bốn byte type tag nằm trước, rồi đến union. Hầu hết kiến trúc máy thích các giá trị được căn chỉnh theo kích thước của chúng. Vì field union chứa một double tám byte, trình biên dịch thêm bốn byte padding sau field type để giữ double ở vị trí bội số của tám byte gần nhất. Điều đó nghĩa là ta đang tốn tám byte cho type tag, trong khi nó chỉ cần biểu diễn số từ 0 đến 3. Ta có thể nhét enum vào kích thước nhỏ hơn, nhưng điều đó chỉ làm tăng padding.
Vậy là mỗi Value chiếm 16 byte, có vẻ hơi lớn. Ta sẽ cải thiện sau này. Trong lúc này, chúng vẫn đủ nhỏ để lưu trên stack của C và truyền theo giá trị. Ngữ nghĩa của Lox cho phép điều đó vì các kiểu mà ta hỗ trợ đến giờ đều là immutable. Nếu ta truyền một bản sao của Value chứa số ba vào một hàm, ta không cần lo người gọi sẽ thấy giá trị bị thay đổi. Bạn không thể “sửa” số ba. Nó sẽ luôn là ba.
18 . 2Lox Values & C Values
Đó là cách biểu diễn giá trị mới của chúng ta, nhưng vẫn chưa xong. Hiện tại, phần còn lại của clox giả định rằng Value là một alias cho double. Chúng ta có code thực hiện ép kiểu C trực tiếp từ cái này sang cái kia. Giờ thì toàn bộ đoạn code đó đã hỏng. Thật buồn.
Với cách biểu diễn mới, một Value có thể chứa một double, nhưng nó không tương đương với double. Cần có một bước chuyển đổi bắt buộc để đi từ cái này sang cái kia. Chúng ta cần rà soát code và chèn các bước chuyển đổi đó để clox chạy lại được.
Chúng ta sẽ cài đặt các bước chuyển đổi này dưới dạng một vài macro, mỗi macro cho một kiểu và thao tác. Đầu tiên, để “nâng” một giá trị C gốc thành một Value của clox:
} Value;
add after struct Value
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}}) #define NIL_VAL ((Value){VAL_NIL, {.number = 0}}) #define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
typedef struct {
Mỗi macro nhận một giá trị C thuộc kiểu phù hợp và tạo ra một Value có type tag đúng và chứa giá trị bên trong. Điều này “nâng” các giá trị kiểu tĩnh lên vũ trụ kiểu động của clox. Nhưng để làm được gì đó với một Value, chúng ta cần “mở” nó ra và lấy lại giá trị C bên trong.
} Value;
add after struct Value
#define AS_BOOL(value) ((value).as.boolean) #define AS_NUMBER(value) ((value).as.number)
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}})
Các macro này đi theo hướng ngược lại. Cho một Value thuộc kiểu đúng, chúng “mở” nó ra và trả về giá trị C thô tương ứng. Phần “kiểu đúng” rất quan trọng! Các macro này truy cập trực tiếp vào các field của union. Nếu ta làm gì đó như:
Value value = BOOL_VAL(true); double number = AS_NUMBER(value);
thì ta có thể mở ra một cánh cổng âm ỉ dẫn tới “Shadow Realm”. Không an toàn khi dùng bất kỳ macro AS_ nào trừ khi ta biết chắc Value chứa kiểu phù hợp. Vì vậy, chúng ta định nghĩa thêm một vài macro cuối cùng để kiểm tra kiểu của Value.
} Value;
add after struct Value
#define IS_BOOL(value) ((value).type == VAL_BOOL) #define IS_NIL(value) ((value).type == VAL_NIL) #define IS_NUMBER(value) ((value).type == VAL_NUMBER)
#define AS_BOOL(value) ((value).as.boolean)
Các macro này trả về true nếu Value có kiểu đó. Mỗi khi gọi một macro AS_, ta cần bảo vệ nó bằng cách gọi một trong các macro này trước. Với tám macro này, giờ ta có thể an toàn “chuyển phát” dữ liệu giữa thế giới động của Lox và thế giới tĩnh của C.
18 . 3Dynamically Typed Numbers
Chúng ta đã có cách biểu diễn giá trị và công cụ để chuyển đổi qua lại. Việc còn lại để clox chạy lại là rà soát code và sửa mọi chỗ dữ liệu đi qua ranh giới đó. Đây là một trong những phần của cuốn sách không hẳn gây “nổ não”, nhưng tôi đã hứa sẽ cho bạn thấy từng dòng code, nên chúng ta sẽ làm thôi.
Những giá trị đầu tiên chúng ta tạo ra là các hằng số được generated khi biên dịch number literal. Sau khi chuyển lexeme thành một double của C, ta chỉ cần bọc nó trong một Value trước khi lưu vào bảng hằng số.
double value = strtod(parser.previous.start, NULL);
in number()
replace 1 line
emitConstant(NUMBER_VAL(value));
}
Bên phía runtime, ta có một hàm để in giá trị.
void printValue(Value value) {
in printValue()
replace 1 line
printf("%g", AS_NUMBER(value));
}
Ngay trước khi gửi Value vào printf(), ta “mở” nó ra và lấy giá trị double. Chúng ta sẽ quay lại hàm này sau để thêm các kiểu khác, nhưng trước hết hãy làm cho code hiện tại chạy được.
18 . 3 . 1Unary negation & runtime errors
Thao tác đơn giản tiếp theo là unary negation. Nó lấy một giá trị từ stack, đổi dấu và đẩy kết quả trở lại. Giờ khi ta có nhiều kiểu giá trị khác nhau, ta không thể giả định toán hạng luôn là số. Người dùng hoàn toàn có thể làm:
print -false; // Ờ thì...
Ta cần xử lý trường hợp này một cách “êm đẹp”, nghĩa là đã đến lúc nói về runtime errors. Trước khi thực hiện một thao tác yêu cầu một kiểu nhất định, ta cần chắc chắn Value là kiểu đó.
Với unary negation, phần kiểm tra trông như sau:
case OP_DIVIDE: BINARY_OP(/); break;
in run()
replace 1 line
case OP_NEGATE: if (!IS_NUMBER(peek(0))) { runtimeError("Operand must be a number."); return INTERPRET_RUNTIME_ERROR; } push(NUMBER_VAL(-AS_NUMBER(pop()))); break;
case OP_RETURN: {
Đầu tiên, ta kiểm tra xem Value trên đỉnh stack có phải là số không. Nếu không, ta báo lỗi runtime và dừng interpreter. Nếu có, ta tiếp tục. Chỉ sau khi xác thực xong, ta mới “mở” toán hạng, đổi dấu, bọc kết quả và đẩy nó lên stack.
Để truy cập Value, ta dùng một hàm nhỏ mới.
add after pop()
static Value peek(int distance) { return vm.stackTop[-1 - distance]; }
Hàm này trả về một Value từ stack nhưng không pop nó. Tham số distance cho biết khoảng cách từ đỉnh stack xuống: 0 là đỉnh, 1 là một ô bên dưới, v.v.
Chúng ta báo lỗi runtime bằng một hàm mới mà ta sẽ dùng rất nhiều trong phần còn lại của cuốn sách.
add after resetStack()
static void runtimeError(const char* format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fputs("\n", stderr); size_t instruction = vm.ip - vm.chunk->code - 1; int line = vm.chunk->lines[instruction]; fprintf(stderr, "[line %d] in script\n", line); resetStack(); }
Chắc chắn bạn đã từng gọi hàm variadic — những hàm nhận số lượng tham số thay đổi — trong C rồi: printf() là một ví dụ. Nhưng có thể bạn chưa từng tự định nghĩa hàm như vậy. Cuốn sách này không phải là tutorial về C, nên tôi sẽ lướt qua: về cơ bản, phần ... và va_list cho phép ta truyền một số lượng đối số tùy ý vào runtimeError(). Hàm này chuyển tiếp chúng tới vfprintf(), phiên bản của printf() nhận một va_list rõ ràng.
Người gọi có thể truyền một format string vào runtimeError() kèm theo một số đối số, giống như khi gọi printf() trực tiếp. runtimeError() sẽ định dạng và in các đối số đó. Chúng ta sẽ chưa tận dụng điều này trong chương này, nhưng các chương sau sẽ tạo ra thông báo lỗi runtime có định dạng, chứa thêm dữ liệu khác.
Sau khi hiển thị thông báo lỗi (hy vọng là hữu ích), ta cho người dùng biết dòng code nào của họ đang được execute khi lỗi xảy ra. Vì ta đã bỏ lại các token trong compiler, ta tra cứu dòng trong thông tin debug được biên dịch vào chunk. Nếu compiler làm đúng việc, dòng đó sẽ khớp với dòng code nguồn mà bytecode được biên dịch từ đó.
Ta tra mảng dòng debug của chunk bằng chỉ số lệnh bytecode hiện tại trừ đi một. Đó là vì interpreter di chuyển qua mỗi lệnh trước khi execute nó. Vậy nên, tại thời điểm gọi runtimeError(), lệnh gây lỗi là lệnh trước đó.
Để sử dụng va_list và các macro làm việc với nó, chúng ta cần đưa vào một standard header.
add to top of file
#include <stdarg.h>
#include <stdio.h>
Với điều này, VM của chúng ta không chỉ làm đúng khi đổi dấu số (như trước khi ta “làm hỏng” nó), mà còn xử lý gọn gàng các nỗ lực đổi dấu những kiểu khác (mà hiện tại ta chưa có, nhưng rồi sẽ có).
18 . 3 . 2Binary arithmetic operators
Giờ ta đã có cơ chế báo lỗi runtime, nên việc sửa các toán tử nhị phân sẽ dễ hơn, dù chúng phức tạp hơn. Hiện tại, ta hỗ trợ bốn toán tử nhị phân: +, -, *, và /. Điểm khác biệt duy nhất giữa chúng là toán tử C bên dưới mà chúng dùng. Để giảm bớt code lặp giữa bốn toán tử này, ta gói phần chung vào một macro tiền xử lý lớn, nhận toán tử làm tham số.
Macro đó từng có vẻ hơi “thừa” vài chương trước, nhưng hôm nay ta sẽ thấy lợi ích của nó. Nó cho phép ta thêm kiểm tra kiểu và chuyển đổi cần thiết chỉ ở một chỗ.
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
in run()
replace 6 lines
#define BINARY_OP(valueType, op) \ do { \ if (!IS_NUMBER(peek(0)) || !IS_NUMBER(peek(1))) { \ runtimeError("Operands must be numbers."); \ return INTERPRET_RUNTIME_ERROR; \ } \ double b = AS_NUMBER(pop()); \ double a = AS_NUMBER(pop()); \ push(valueType(a op b)); \ } while (false)
for (;;) {
Vâng, tôi biết đây là một macro “quái vật”. Bình thường tôi sẽ không coi đó là thực hành C tốt, nhưng cứ tạm dùng. Các thay đổi tương tự như với unary negate. Đầu tiên, ta kiểm tra cả hai toán hạng đều là số. Nếu một trong hai không phải, ta báo lỗi runtime và “giật cần” ghế phóng.
Nếu toán hạng hợp lệ, ta pop cả hai và “mở” chúng ra. Sau đó áp dụng toán tử đã cho, bọc kết quả lại và push lên stack. Lưu ý rằng ta không bọc kết quả trực tiếp bằng NUMBER_VAL(). Thay vào đó, macro bọc được truyền vào như một tham số. Với các toán tử số học hiện tại, kết quả là số, nên ta truyền vào macro NUMBER_VAL.
}
in run()
replace 4 lines
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break; case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break; case OP_MULTIPLY: BINARY_OP(NUMBER_VAL, *); break; case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
case OP_NEGATE:
Chẳng bao lâu nữa, tôi sẽ cho bạn thấy lý do tại sao ta lại truyền macro bọc dưới dạng tham số.
18 . 4Two New Types
Toàn bộ code clox hiện tại đã chạy lại được. Cuối cùng, đã đến lúc thêm một số kiểu mới. Chúng ta đang có một máy tính số học chạy được, giờ lại thực hiện hàng loạt kiểm tra kiểu runtime “thừa thãi” nhưng an toàn. Ta có thể biểu diễn các kiểu khác bên trong, nhưng chưa có cách nào để chương trình của người dùng tạo ra một Value thuộc các kiểu đó.
Cho đến bây giờ. Ta sẽ bắt đầu bằng cách thêm hỗ trợ ở compiler cho ba literal mới: true, false, và nil. Chúng đều khá đơn giản, nên ta sẽ làm cả ba trong một lượt.
Với number literal, ta phải xử lý việc có hàng tỷ giá trị số có thể. Ta giải quyết bằng cách lưu giá trị literal vào bảng hằng số của chunk và phát sinh một lệnh bytecode chỉ việc nạp hằng đó. Ta có thể làm tương tự với các kiểu mới này: lưu true vào bảng hằng số, rồi dùng OP_CONSTANT để đọc ra.
Nhưng vì thực tế (heh) chỉ có đúng ba giá trị cần quan tâm, nên việc tốn một lệnh hai byte và một mục trong bảng hằng số cho chúng là quá phí — và chậm!. Thay vào đó, ta sẽ định nghĩa ba lệnh riêng để push từng literal này lên stack.
OP_CONSTANT,
in enum OpCode
OP_NIL, OP_TRUE, OP_FALSE,
OP_ADD,
Scanner của ta đã coi true, false, và nil là keyword, nên ta có thể bỏ qua bước đó và sang parser. Với Pratt parser dựa trên bảng, ta chỉ cần gán hàm parser vào các hàng tương ứng với các token type keyword đó. Ta sẽ dùng cùng một hàm cho cả ba. Đây:
[TOKEN_ELSE] = {NULL, NULL, PREC_NONE},
replace 1 line
[TOKEN_FALSE] = {literal, NULL, PREC_NONE},
[TOKEN_FOR] = {NULL, NULL, PREC_NONE},
Đây:
[TOKEN_THIS] = {NULL, NULL, PREC_NONE},
replace 1 line
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
[TOKEN_VAR] = {NULL, NULL, PREC_NONE},
Và đây:
[TOKEN_IF] = {NULL, NULL, PREC_NONE},
replace 1 line
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
[TOKEN_OR] = {NULL, NULL, PREC_NONE},
Khi parser gặp false, nil, hoặc true ở vị trí prefix, nó gọi hàm parser mới này:
add after binary()
static void literal() { switch (parser.previous.type) { case TOKEN_FALSE: emitByte(OP_FALSE); break; case TOKEN_NIL: emitByte(OP_NIL); break; case TOKEN_TRUE: emitByte(OP_TRUE); break; default: return; // Unreachable. } }
Vì parsePrecedence() đã đọc token keyword, ta chỉ cần xuất lệnh phù hợp. Ta xác định lệnh dựa trên loại token đã parse. Front end của ta giờ có thể biên dịch Boolean và nil literal thành bytecode. Tiếp tục xuống pipeline execute, ta đến interpreter.
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
push(constant);
break;
}
in run()
case OP_NIL: push(NIL_VAL); break; case OP_TRUE: push(BOOL_VAL(true)); break; case OP_FALSE: push(BOOL_VAL(false)); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
Phần này khá rõ ràng. Mỗi lệnh tạo ra giá trị tương ứng và push nó lên stack. Ta cũng không nên quên disassembler.
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
in disassembleInstruction()
case OP_NIL: return simpleInstruction("OP_NIL", offset); case OP_TRUE: return simpleInstruction("OP_TRUE", offset); case OP_FALSE: return simpleInstruction("OP_FALSE", offset);
case OP_ADD:
Với phần này, ta có thể chạy chương trình “động trời” sau:
true
Ngoại trừ việc khi interpreter cố in kết quả, nó sẽ “nổ tung”. Ta cần mở rộng printValue() để xử lý các kiểu mới:
void printValue(Value value) {
in printValue()
replace 1 line
switch (value.type) { case VAL_BOOL: printf(AS_BOOL(value) ? "true" : "false"); break; case VAL_NIL: printf("nil"); break; case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break; }
}
Xong! Giờ ta đã có một số kiểu mới. Chúng vẫn chưa hữu ích lắm. Ngoài các literal, bạn chưa thể làm gì với chúng. Sẽ còn một thời gian nữa trước khi nil thực sự được dùng, nhưng ta có thể bắt đầu cho Boolean “ra trận” trong các toán tử logic.
18 . 4 . 1Logical not & falsiness
Toán tử logic đơn giản nhất là người bạn cũ đầy cảm thán — unary not.
print !true; // "false"
Thao tác mới này sẽ có một instruction mới.
OP_DIVIDE,
in enum OpCode
OP_NOT,
OP_NEGATE,
Chúng ta có thể tái sử dụng hàm parser unary() đã viết cho unary negation để biên dịch một biểu thức not. Chỉ cần gán nó vào bảng phân tích cú pháp.
[TOKEN_STAR] = {NULL, binary, PREC_FACTOR},
replace 1 line
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
[TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE},
Vì tôi đã biết trước sẽ làm điều này, hàm unary() vốn đã có một switch trên token type để xác định instruction bytecode cần xuất ra. Ta chỉ việc thêm một case mới.
switch (operatorType) {
in unary()
case TOKEN_BANG: emitByte(OP_NOT); break;
case TOKEN_MINUS: emitByte(OP_NEGATE); break;
default: return; // Unreachable.
}
Vậy là xong phần front end. Giờ sang VM để “gọi hồn” instruction này.
case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
in run()
case OP_NOT: push(BOOL_VAL(isFalsey(pop()))); break;
case OP_NEGATE:
Giống như toán tử unary trước, nó pop một toán hạng, thực hiện phép toán và push kết quả. Và, như trước, ta phải lưu ý đến dynamic typing. Lấy phủ định logic của true thì dễ, nhưng chẳng có gì ngăn một lập trình viên “nghịch ngợm” viết như sau:
print !nil;
Với unary minus, ta coi là lỗi nếu đổi dấu thứ không phải là số. Nhưng Lox, giống hầu hết các ngôn ngữ scripting, dễ dãi hơn với ! và các ngữ cảnh khác nơi Boolean được mong đợi. Quy tắc xử lý các kiểu khác được gọi là “falsiness”, và ta cài đặt nó ở đây:
add after peek()
static bool isFalsey(Value value) { return IS_NIL(value) || (IS_BOOL(value) && !AS_BOOL(value)); }
Lox theo Ruby ở chỗ nil và false là falsey, còn mọi giá trị khác thì coi như true. Ta đã có một instruction mới để sinh ra, nên cũng cần có cách bỏ sinh nó trong disassembler.
case OP_DIVIDE:
return simpleInstruction("OP_DIVIDE", offset);
in disassembleInstruction()
case OP_NOT: return simpleInstruction("OP_NOT", offset);
case OP_NEGATE:
18 . 4 . 2Equality & comparison operators
Không tệ lắm. Hãy giữ đà này và xử lý luôn các toán tử so sánh và bằng nhau: ==, !=, <, >, <=, và >=. Như vậy là bao quát hết các toán tử trả về Boolean trừ and và or. Vì chúng cần short-circuit (tức là làm một chút control flow) nên ta chưa sẵn sàng cho chúng.
Đây là các instruction mới cho những toán tử đó:
OP_FALSE,
in enum OpCode
OP_EQUAL, OP_GREATER, OP_LESS,
OP_ADD,
Khoan, chỉ có ba thôi à? Thế !=, <=, và >= đâu? Ta cũng có thể tạo instruction cho chúng. Thực tế, VM sẽ chạy nhanh hơn nếu làm vậy, nên nếu mục tiêu là hiệu năng thì nên làm.
Nhưng mục tiêu chính của tôi là dạy bạn về bytecode compiler. Tôi muốn bạn bắt đầu “ngấm” ý tưởng rằng bytecode instruction không cần bám sát code nguồn của người dùng. VM hoàn toàn tự do dùng bất kỳ tập lệnh và chuỗi lệnh nào miễn là hành vi với người dùng là đúng.
Biểu thức a != b có cùng ngữ nghĩa với !(a == b), nên compiler có thể biên dịch cái trước như cái sau. Thay vì một instruction OP_NOT_EQUAL riêng, nó có thể xuất OP_EQUAL rồi OP_NOT. Tương tự, a <= b giống !(a > b) và a >= b là !(a < b). Vậy ta chỉ cần ba instruction mới.
Bên parser, ta có sáu toán tử mới để gán vào bảng parse. Ta dùng lại hàm parser binary() từ trước. Đây là hàng cho !=:
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
replace 1 line
[TOKEN_BANG_EQUAL] = {NULL, binary, PREC_EQUALITY},
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
Năm toán tử còn lại nằm thấp hơn một chút trong bảng.
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
replace 5 lines
[TOKEN_EQUAL_EQUAL] = {NULL, binary, PREC_EQUALITY}, [TOKEN_GREATER] = {NULL, binary, PREC_COMPARISON}, [TOKEN_GREATER_EQUAL] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
Bên trong binary() ta đã có một switch để sinh bytecode phù hợp cho từng token type. Ta thêm case cho sáu toán tử mới.
switch (operatorType) {
in binary()
case TOKEN_BANG_EQUAL: emitBytes(OP_EQUAL, OP_NOT); break; case TOKEN_EQUAL_EQUAL: emitByte(OP_EQUAL); break; case TOKEN_GREATER: emitByte(OP_GREATER); break; case TOKEN_GREATER_EQUAL: emitBytes(OP_LESS, OP_NOT); break; case TOKEN_LESS: emitByte(OP_LESS); break; case TOKEN_LESS_EQUAL: emitBytes(OP_GREATER, OP_NOT); break;
case TOKEN_PLUS: emitByte(OP_ADD); break;
Các toán tử ==, <, và > xuất một instruction duy nhất. Các toán tử còn lại xuất một cặp instruction: một để tính toán phép so sánh ngược, rồi OP_NOT để đảo kết quả. Sáu toán tử với giá của ba instruction!
Điều đó nghĩa là bên VM, công việc của ta đơn giản hơn. Equality là phép tổng quát nhất.
case OP_FALSE: push(BOOL_VAL(false)); break;
in run()
case OP_EQUAL: { Value b = pop(); Value a = pop(); push(BOOL_VAL(valuesEqual(a, b))); break; }
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
Bạn có thể so sánh == trên bất kỳ cặp object nào, kể cả khác kiểu. Có đủ độ phức tạp để đáng tách logic này sang một hàm riêng. Hàm này luôn trả về một bool của C, nên ta có thể bọc kết quả trong BOOL_VAL một cách an toàn. Hàm này liên quan đến Value, nên nó nằm trong module “value”.
} ValueArray;
add after struct ValueArray
bool valuesEqual(Value a, Value b);
void initValueArray(ValueArray* array);
Và đây là phần cài đặt:
add after printValue()
bool valuesEqual(Value a, Value b) { if (a.type != b.type) return false; switch (a.type) { case VAL_BOOL: return AS_BOOL(a) == AS_BOOL(b); case VAL_NIL: return true; case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b); default: return false; // Unreachable. } }
Đầu tiên, ta kiểm tra kiểu. Nếu các Value có kiểu khác nhau, chắc chắn chúng không bằng nhau. Ngược lại, ta “mở” hai Value và so sánh trực tiếp.
Với mỗi kiểu giá trị, chúng ta có một case riêng để xử lý so sánh bản thân giá trị đó. Với việc các case này khá giống nhau, bạn có thể thắc mắc tại sao ta không đơn giản memcmp() hai struct Value cho xong. Vấn đề là do padding và các field union có kích thước khác nhau, một Value chứa cả những bit không dùng. C không đảm bảo nội dung của những bit này, nên hoàn toàn có thể xảy ra trường hợp hai Value bằng nhau nhưng khác nhau ở phần bộ nhớ không dùng đến.
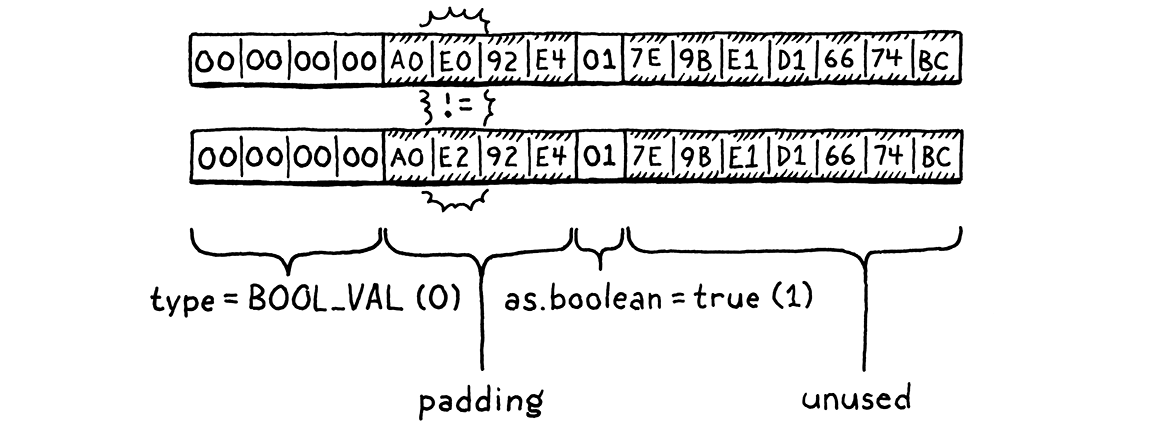
(Bạn sẽ không tin tôi đã phải chịu bao nhiêu đau đớn trước khi biết sự thật này đâu.)
Dù sao thì, khi ta thêm nhiều kiểu hơn vào clox, hàm này sẽ có thêm các case mới. Hiện tại, ba kiểu này là đủ. Các toán tử so sánh khác thì dễ hơn vì chúng chỉ hoạt động trên số.
push(BOOL_VAL(valuesEqual(a, b)));
break;
}
in run()
case OP_GREATER: BINARY_OP(BOOL_VAL, >); break; case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
Chúng ta đã mở rộng macro BINARY_OP để xử lý các toán tử trả về kiểu không phải số. Giờ là lúc dùng nó. Ta truyền vào BOOL_VAL vì kiểu giá trị kết quả là Boolean. Ngoài ra, nó không khác gì cộng hay trừ.
Như thường lệ, phần “coda” cho bản aria hôm nay là disassemble các instruction mới.
case OP_FALSE:
return simpleInstruction("OP_FALSE", offset);
in disassembleInstruction()
case OP_EQUAL: return simpleInstruction("OP_EQUAL", offset); case OP_GREATER: return simpleInstruction("OP_GREATER", offset); case OP_LESS: return simpleInstruction("OP_LESS", offset);
case OP_ADD:
Vậy là chiếc “máy tính số học” của chúng ta đã trở thành một thứ gần giống bộ đánh giá biểu thức tổng quát hơn. Khởi động clox và gõ:
!(5 - 4 > 3 * 2 == !nil)
Được rồi, tôi thừa nhận đây có thể không phải là biểu thức hữu ích nhất, nhưng chúng ta đang tiến bộ. Giờ chỉ còn thiếu một kiểu built-in với literal riêng: strings. Chúng phức tạp hơn nhiều vì string có thể thay đổi kích thước. Sự khác biệt nhỏ này lại kéo theo những hệ quả đủ lớn để chúng tôi dành hẳn một chương riêng cho strings.
18 . 5Thử thách
-
Chúng ta có thể giảm số lượng toán tử nhị phân xuống nữa so với hiện tại. Bạn có thể loại bỏ thêm những instruction nào, và compiler sẽ xử lý thế nào khi thiếu chúng?
-
Ngược lại, ta có thể cải thiện tốc độ của bytecode VM bằng cách thêm nhiều instruction chuyên biệt hơn, tương ứng với các thao tác cấp cao. Bạn sẽ định nghĩa những instruction nào để tăng tốc cho loại code người dùng mà chúng ta đã hỗ trợ trong chương này?