Strings
“Ồ? Một chút ác cảm với công việc lặt vặt ư?” Vị bác sĩ nhướn mày. “Có thể hiểu được, nhưng lại đặt sai chỗ. Người ta nên trân trọng những công việc tầm thường giữ cho cơ thể bận rộn nhưng để cho tâm trí và trái tim được tự do.”
Tad Williams, The Dragonbone Chair
VM nhỏ bé của chúng ta hiện có thể biểu diễn ba loại giá trị: số, Boolean và nil. Những loại này có hai điểm chung quan trọng: chúng là immutable và nhỏ gọn. Số là loại lớn nhất, nhưng vẫn vừa trong hai từ 64-bit. Đây là một mức chi phí đủ nhỏ để ta có thể chấp nhận cho mọi giá trị, kể cả Boolean và nil vốn không cần nhiều không gian đến vậy.
Tiếc là string thì không nhỏ nhắn như vậy. Không có giới hạn độ dài tối đa cho string. Ngay cả khi ta đặt một giới hạn nhân tạo, ví dụ như 255 ký tự, thì vẫn là quá nhiều bộ nhớ để dành cho mọi giá trị.
Ta cần một cách để hỗ trợ các giá trị có kích thước thay đổi, đôi khi rất lớn. Đây chính xác là điều mà cấp phát động trên heap được thiết kế để làm. Ta có thể cấp phát bao nhiêu byte tùy ý. Ta nhận lại một con trỏ để dùng theo dõi giá trị khi nó di chuyển qua VM.
19 . 1Value & Object
Dùng heap cho các giá trị lớn, kích thước thay đổi và stack cho các giá trị nhỏ, nguyên tử dẫn đến một mô hình biểu diễn hai tầng. Mỗi giá trị Lox mà bạn có thể lưu trong biến hoặc trả về từ một expression sẽ là một Value. Với các loại nhỏ, kích thước cố định như số, payload được lưu trực tiếp bên trong struct Value.
Nếu object lớn hơn, dữ liệu của nó nằm trên heap. Khi đó, payload của Value là một con trỏ tới khối bộ nhớ đó. Cuối cùng, trong clox ta sẽ có một vài loại được cấp phát trên heap: string, instance, function, v.v. Mỗi loại có dữ liệu riêng, nhưng cũng có trạng thái chung mà bộ gom rác tương lai của chúng ta sẽ dùng để quản lý bộ nhớ.
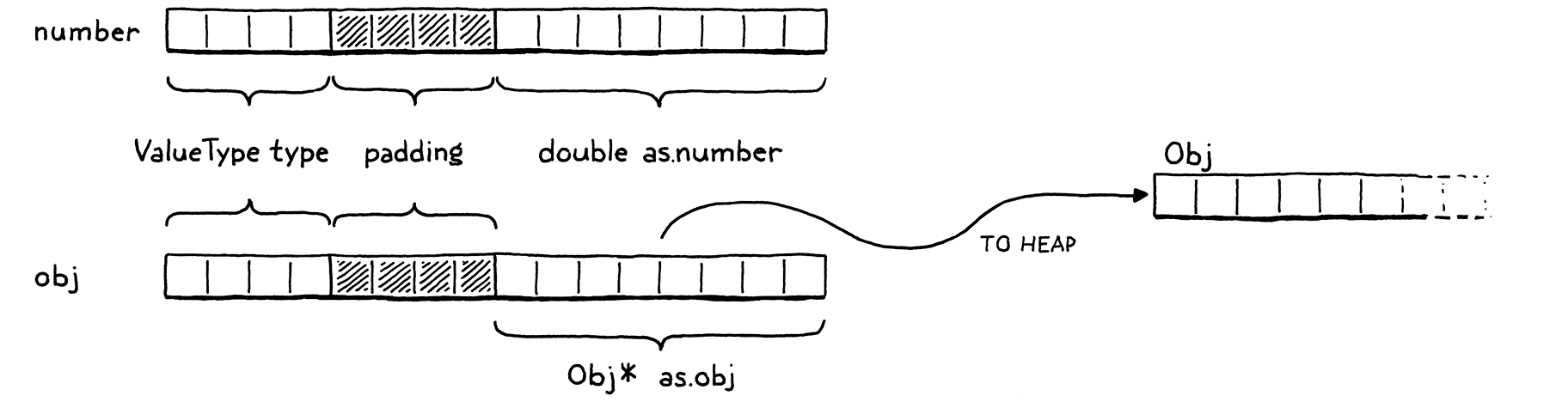
Ta sẽ gọi phần biểu diễn chung này là “Obj”. Mỗi giá trị Lox có trạng thái nằm trên heap là một Obj. Nhờ vậy, ta có thể dùng một trường ValueType mới duy nhất để tham chiếu tới tất cả các loại được cấp phát trên heap.
VAL_NUMBER,
in enum ValueType
VAL_OBJ
} ValueType;
Khi kiểu của Value là VAL_OBJ, payload là một con trỏ tới bộ nhớ trên heap, nên ta thêm một trường nữa vào union cho trường hợp này.
double number;
in struct Value
Obj* obj;
} as;
Giống như với các loại value khác, ta tạo thêm một vài macro tiện lợi để làm việc với Obj value.
#define IS_NUMBER(value) ((value).type == VAL_NUMBER)
add after struct Value
#define IS_OBJ(value) ((value).type == VAL_OBJ)
#define AS_BOOL(value) ((value).as.boolean)
Macro này trả về true nếu Value được truyền vào là một Obj. Nếu đúng, ta có thể dùng macro này:
#define IS_OBJ(value) ((value).type == VAL_OBJ)
#define AS_OBJ(value) ((value).as.obj)
#define AS_BOOL(value) ((value).as.boolean)
Nó trích xuất con trỏ Obj từ value. Ta cũng có thể đi theo hướng ngược lại.
#define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
#define OBJ_VAL(object) ((Value){VAL_OBJ, {.obj = (Obj*)object}})
typedef struct {
Macro này nhận một con trỏ Obj thuần và bọc nó thành một Value đầy đủ.
19 . 2Kế thừa Struct
Mỗi giá trị được cấp phát trên heap là một Obj, nhưng các Obj không phải đều giống nhau. Với string, ta cần mảng ký tự. Khi đến instance, chúng sẽ cần các trường dữ liệu. Một function object sẽ cần chunk bytecode của nó. Làm sao để xử lý các payload và kích thước khác nhau? Ta không thể dùng một union khác như với Value vì kích thước của chúng rất khác nhau.
Thay vào đó, ta sẽ dùng một kỹ thuật khác. Nó đã tồn tại từ lâu, đến mức đặc tả C còn dành riêng hỗ trợ cho nó, nhưng tôi không biết nó có tên gọi chính thức không. Đây là một ví dụ của type punning, nhưng thuật ngữ đó quá rộng. Khi chưa có ý tưởng hay hơn, tôi sẽ gọi nó là struct inheritance (kế thừa struct), vì nó dựa vào struct và gần giống cách kế thừa đơn trạng thái hoạt động trong các ngôn ngữ hướng đối tượng.
Giống như một tagged union, mỗi Obj bắt đầu với một trường tag xác định loại object — string, instance, v.v. Theo sau là các trường payload. Thay vì một union với các case cho từng loại, mỗi loại là một struct riêng biệt. Phần khó là làm sao xử lý các struct này một cách thống nhất vì C không có khái niệm kế thừa hay đa hình. Tôi sẽ giải thích điều đó sớm thôi, nhưng trước hết hãy xử lý phần chuẩn bị.
Tên “Obj” bản thân nó chỉ một struct chứa trạng thái chung cho tất cả các loại object. Nó giống như “lớp cơ sở” cho object. Vì có một số phụ thuộc vòng giữa value và object, ta forward-declare nó trong module “value”.
#include "common.h"
typedef struct Obj Obj;
typedef enum {
Và định nghĩa thực sự nằm trong một module mới.
create new file
#ifndef clox_object_h #define clox_object_h #include "common.h" #include "value.h" struct Obj { ObjType type; }; #endif
Hiện tại, nó chỉ chứa type tag. Chẳng bao lâu nữa, ta sẽ thêm một số thông tin quản lý bộ nhớ khác. Enum type như sau:
#include "value.h"
typedef enum { OBJ_STRING, } ObjType;
struct Obj {
Rõ ràng, enum này sẽ hữu ích hơn ở các chương sau khi ta thêm nhiều loại cấp phát trên heap hơn. Vì ta sẽ truy cập các tag type này thường xuyên, đáng để tạo một macro nhỏ trích xuất tag type của object từ một Value.
#include "value.h"
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
typedef enum {
Đó là nền tảng của ta.
Giờ, hãy xây dựng string dựa trên nó. Payload cho string được định nghĩa trong một struct riêng. Một lần nữa, ta cần forward-declare nó.
typedef struct Obj Obj;
typedef struct ObjString ObjString;
typedef enum {
Định nghĩa nằm cùng với Obj.
};
add after struct Obj
struct ObjString { Obj obj; int length; char* chars; };
#endif
Một string object chứa một mảng ký tự. Chúng được lưu trong một mảng riêng trên heap để ta chỉ dành đúng lượng bộ nhớ cần cho mỗi string. Ta cũng lưu số byte trong mảng. Điều này không hoàn toàn bắt buộc nhưng cho phép ta biết lượng bộ nhớ đã cấp phát cho string mà không cần duyệt mảng ký tự để tìm ký tự null kết thúc.
Vì ObjString là một Obj, nó cũng cần trạng thái chung của tất cả Obj. Nó đạt được điều đó bằng cách để trường đầu tiên của nó là một Obj. C quy định rằng các trường trong struct được sắp xếp trong bộ nhớ theo thứ tự khai báo. Ngoài ra, khi bạn lồng struct, các trường của struct bên trong sẽ được “trải” ngay tại chỗ. Vì vậy, bộ nhớ cho Obj và ObjString trông như thế này:
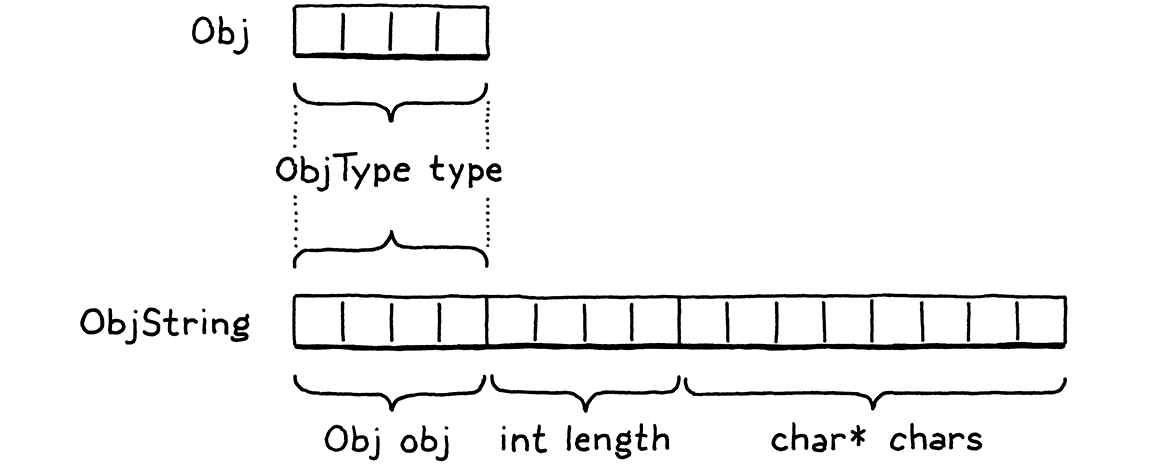
Hãy để ý rằng các byte đầu tiên của ObjString khớp chính xác với Obj. Đây không phải là sự trùng hợp — C quy định điều này. Nó được thiết kế để cho phép một mẫu lập trình thông minh: bạn có thể lấy một con trỏ tới struct và an toàn chuyển đổi nó thành con trỏ tới trường đầu tiên của struct đó và ngược lại.
Với một ObjString*, bạn có thể an toàn cast nó sang Obj* và sau đó truy cập trường type từ đó. Mỗi ObjString “là” một Obj theo nghĩa OOP của từ “là”. Sau này khi ta thêm các loại object khác, mỗi struct sẽ có một Obj làm trường đầu tiên. Bất kỳ code nào muốn làm việc với tất cả object có thể coi chúng như Obj* cơ sở và bỏ qua các trường khác theo sau.
Bạn cũng có thể đi theo hướng ngược lại. Với một Obj*, bạn có thể “downcast” nó thành ObjString*. Tất nhiên, bạn cần đảm bảo rằng con trỏ Obj* bạn có thực sự trỏ tới trường obj của một ObjString hợp lệ. Nếu không, bạn đang diễn giải lại một cách không an toàn những bit bộ nhớ ngẫu nhiên. Để phát hiện việc cast như vậy có an toàn hay không, ta thêm một macro khác.
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
typedef enum {
Macro này nhận một Value, không phải Obj* thuần, vì hầu hết code trong VM làm việc với Value. Nó dựa vào hàm inline sau:
};
add after struct ObjString
static inline bool isObjType(Value value, ObjType type) { return IS_OBJ(value) && AS_OBJ(value)->type == type; }
#endif
Câu đố nhanh: Tại sao không đặt luôn phần thân của hàm này vào macro? Nó khác gì so với các macro khác? Đúng vậy, là vì phần thân dùng value hai lần. Macro được mở rộng bằng cách chèn biểu thức đối số vào mọi chỗ tên tham số xuất hiện trong thân. Nếu một macro dùng tham số nhiều hơn một lần, biểu thức đó sẽ được đánh giá nhiều lần.
Điều này tệ nếu biểu thức có side effect. Nếu ta đặt phần thân của isObjType() vào macro và bạn viết, ví dụ:
IS_STRING(POP())
thì nó sẽ pop hai giá trị khỏi stack! Dùng hàm sẽ khắc phục điều đó.
Miễn là ta đảm bảo gán đúng type tag mỗi khi tạo một Obj thuộc loại nào đó, macro này sẽ cho ta biết khi nào an toàn để cast một value sang một loại object cụ thể. Ta có thể làm điều đó bằng các macro sau:
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_STRING(value) ((ObjString*)AS_OBJ(value)) #define AS_CSTRING(value) (((ObjString*)AS_OBJ(value))->chars)
typedef enum {
Hai macro này nhận một Value được kỳ vọng chứa con trỏ tới một ObjString hợp lệ trên heap. Macro đầu trả về con trỏ ObjString*. Macro thứ hai đi sâu hơn để trả về mảng ký tự bên trong, vì đó thường là thứ ta cần.
19 . 3String
OK, VM của ta giờ có thể biểu diễn giá trị string. Đã đến lúc thêm string vào chính ngôn ngữ. Như thường lệ, ta bắt đầu ở front end. Lexer đã tokenize string literal, nên giờ tới lượt parser.
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
replace 1 line
[TOKEN_STRING] = {string, NULL, PREC_NONE},
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
Khi parser gặp một token string, nó gọi hàm parse này:
add after number()
static void string() { emitConstant(OBJ_VAL(copyString(parser.previous.start + 1, parser.previous.length - 2))); }
Hàm này lấy các ký tự của string trực tiếp từ lexeme. Phần + 1 và - 2 sẽ bỏ dấu ngoặc kép ở đầu và cuối. Sau đó, nó tạo một string object, bọc nó trong một Value và nhét vào constant table.
Để tạo string, ta dùng copyString(), được khai báo trong object.h.
};
add after struct ObjString
ObjString* copyString(const char* chars, int length);
static inline bool isObjType(Value value, ObjType type) {
Module compiler cần include file này.
#define clox_compiler_h
#include "object.h"
#include "vm.h"
Module “object” của ta sẽ có một file hiện thực nơi ta định nghĩa hàm mới này.
create new file
#include <stdio.h> #include <string.h> #include "memory.h" #include "object.h" #include "value.h" #include "vm.h" ObjString* copyString(const char* chars, int length) { char* heapChars = ALLOCATE(char, length + 1); memcpy(heapChars, chars, length); heapChars[length] = '\0'; return allocateString(heapChars, length); }
Đầu tiên, ta cấp phát một mảng mới trên heap, vừa đủ cho các ký tự của string và ký tự kết thúc, dùng macro cấp thấp này để cấp phát một mảng với kiểu phần tử và số lượng cho trước:
#include "common.h"
#define ALLOCATE(type, count) \ (type*)reallocate(NULL, 0, sizeof(type) * (count))
#define GROW_CAPACITY(capacity) \
Khi đã có mảng, ta copy các ký tự từ lexeme sang và thêm ký tự kết thúc.
Bạn có thể thắc mắc tại sao ObjString không thể trỏ ngược lại các ký tự gốc trong chuỗi nguồn. Một số ObjString sẽ được tạo động khi runtime do các thao tác string như nối chuỗi. Những string này rõ ràng cần cấp phát động bộ nhớ cho ký tự, đồng nghĩa với việc string cần giải phóng bộ nhớ đó khi không còn dùng.
Nếu ta có một ObjString cho một string literal, và cố giải phóng mảng ký tự của nó vốn trỏ vào chuỗi nguồn gốc, thì sẽ xảy ra lỗi nghiêm trọng. Vì vậy, với literal, ta chủ động copy các ký tự sang heap. Cách này đảm bảo mọi ObjString đều sở hữu mảng ký tự của mình và có thể giải phóng nó.
Phần công việc chính để tạo string object diễn ra trong hàm này:
#include "vm.h"
static ObjString* allocateString(char* chars, int length) { ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING); string->length = length; string->chars = chars; return string; }
Hàm này tạo một ObjString mới trên heap rồi khởi tạo các trường của nó. Nó giống như constructor trong ngôn ngữ OOP. Vì vậy, nó gọi constructor “lớp cơ sở” trước để khởi tạo trạng thái Obj, dùng một macro mới.
#include "vm.h"
#define ALLOCATE_OBJ(type, objectType) \ (type*)allocateObject(sizeof(type), objectType)
static ObjString* allocateString(char* chars, int length) {
Giống macro trước, macro này tồn tại chủ yếu để tránh phải cast void* về kiểu mong muốn một cách lặp lại. Chức năng thực sự nằm ở đây:
#define ALLOCATE_OBJ(type, objectType) \
(type*)allocateObject(sizeof(type), objectType)
static Obj* allocateObject(size_t size, ObjType type) { Obj* object = (Obj*)reallocate(NULL, 0, size); object->type = type; return object; }
static ObjString* allocateString(char* chars, int length) {
Hàm này cấp phát một object với kích thước cho trước trên heap. Lưu ý rằng kích thước này không chỉ là kích thước của riêng Obj. Hàm gọi sẽ truyền vào số byte để có đủ chỗ cho các trường payload bổ sung cần thiết cho loại object cụ thể đang được tạo.
Sau đó, nó khởi tạo trạng thái Obj — hiện tại chỉ là type tag. Hàm này trả về cho allocateString(), hàm sẽ hoàn tất việc khởi tạo các trường của ObjString. Voilà, ta đã có thể biên dịch và execute string literal.
19 . 4Các thao tác trên String
String “xịn” của ta đã có, nhưng chúng chưa làm được gì nhiều. Bước đầu tiên hợp lý là khiến code in hiện tại không bị “nghẹn” khi gặp kiểu giá trị mới.
case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break;
in printValue()
case VAL_OBJ: printObject(value); break;
}
Nếu value là một object được cấp phát trên heap, nó sẽ chuyển tiếp sang một hàm helper trong module “object”.
ObjString* copyString(const char* chars, int length);
add after copyString()
void printObject(Value value);
static inline bool isObjType(Value value, ObjType type) {
Phần hiện thực trông như sau:
add after copyString()
void printObject(Value value) { switch (OBJ_TYPE(value)) { case OBJ_STRING: printf("%s", AS_CSTRING(value)); break; } }
Hiện tại ta mới chỉ có một loại object, nhưng hàm này sẽ mọc thêm nhiều case trong switch ở các chương sau. Với string object, nó đơn giản in mảng ký tự như một chuỗi C.
Các toán tử so sánh bằng cũng cần xử lý string một cách hợp lý. Xem ví dụ:
"string" == "string"
Đây là hai string literal riêng biệt. Compiler sẽ gọi copyString() hai lần, tạo ra hai ObjString khác nhau và lưu chúng thành hai hằng số trong chunk. Chúng là hai object khác nhau trên heap. Nhưng người dùng (và vì thế là chúng ta) mong string so sánh bằng theo giá trị. Biểu thức trên phải trả về true. Điều này cần một chút hỗ trợ đặc biệt.
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
in valuesEqual()
case VAL_OBJ: { ObjString* aString = AS_STRING(a); ObjString* bString = AS_STRING(b); return aString->length == bString->length && memcmp(aString->chars, bString->chars, aString->length) == 0; }
default: return false; // Unreachable.
Nếu cả hai value đều là string, thì chúng bằng nhau nếu mảng ký tự của chúng chứa cùng một chuỗi ký tự, bất kể chúng là hai object khác nhau hay cùng một object. Điều này đồng nghĩa so sánh string sẽ chậm hơn so với các loại khác vì phải duyệt toàn bộ chuỗi. Ta sẽ cải thiện điều đó sau này, nhưng hiện tại cách này cho ta ngữ nghĩa đúng.
Cuối cùng, để dùng memcmp() và các phần mới trong module “object”, ta cần thêm một vài include. Ở đây:
#include <stdio.h>
#include <string.h>
#include "memory.h"
Và ở đây:
#include <string.h>
#include "object.h"
#include "memory.h"
19 . 4 . 1Nối chuỗi (Concatenation)
Các ngôn ngữ hoàn chỉnh cung cấp rất nhiều thao tác với string — truy cập ký tự riêng lẻ, lấy độ dài, đổi chữ hoa/thường, tách, nối, tìm kiếm, v.v. Khi bạn hiện thực ngôn ngữ của mình, có thể bạn sẽ muốn tất cả những thứ đó. Nhưng trong cuốn sách này, ta sẽ giữ mọi thứ rất tối giản.
Thao tác thú vị duy nhất ta hỗ trợ trên string là +. Nếu bạn dùng toán tử này trên hai string object, nó sẽ tạo ra một string mới là kết quả nối của hai toán hạng. Vì Lox là ngôn ngữ kiểu động, ta không thể biết hành vi nào cần dùng ở compile time vì chưa biết kiểu của toán hạng cho tới khi runtime. Do đó, lệnh OP_ADD sẽ kiểm tra kiểu toán hạng khi chạy và chọn thao tác phù hợp.
case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
in run()
replace 1 line
case OP_ADD: { if (IS_STRING(peek(0)) && IS_STRING(peek(1))) { concatenate(); } else if (IS_NUMBER(peek(0)) && IS_NUMBER(peek(1))) { double b = AS_NUMBER(pop()); double a = AS_NUMBER(pop()); push(NUMBER_VAL(a + b)); } else { runtimeError( "Operands must be two numbers or two strings."); return INTERPRET_RUNTIME_ERROR; } break; }
case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break;
Nếu cả hai toán hạng là string, nó sẽ nối chúng. Nếu cả hai là số, nó sẽ cộng. Bất kỳ kết hợp kiểu nào khác sẽ là lỗi runtime.
Để nối string, ta định nghĩa một hàm mới.
add after isFalsey()
static void concatenate() { ObjString* b = AS_STRING(pop()); ObjString* a = AS_STRING(pop()); int length = a->length + b->length; char* chars = ALLOCATE(char, length + 1); memcpy(chars, a->chars, a->length); memcpy(chars + a->length, b->chars, b->length); chars[length] = '\0'; ObjString* result = takeString(chars, length); push(OBJ_VAL(result)); }
Hàm này khá dài dòng, như thường thấy với code C làm việc với string. Đầu tiên, ta tính độ dài của string kết quả dựa trên độ dài của các toán hạng. Ta cấp phát một mảng ký tự cho kết quả rồi copy hai phần vào. Như mọi khi, ta đảm bảo chuỗi được kết thúc đúng cách.
Để gọi memcpy(), VM cần include này:
#include <stdio.h>
#include <string.h>
#include "common.h"
Cuối cùng, ta tạo một ObjString để chứa các ký tự đó. Lần này ta dùng một hàm mới, takeString().
};
add after struct ObjString
ObjString* takeString(char* chars, int length);
ObjString* copyString(const char* chars, int length);
Phần hiện thực trông như sau:
add after allocateString()
ObjString* takeString(char* chars, int length) { return allocateString(chars, length); }
Hàm copyString() trước đây giả định rằng nó không thể nhận quyền sở hữu mảng ký tự bạn truyền vào. Thay vào đó, nó sẽ tạo một bản copy trên heap để ObjString sở hữu. Đây là cách đúng cho string literal, nơi mảng ký tự truyền vào nằm giữa chuỗi nguồn.
Nhưng với nối chuỗi, ta đã cấp phát động một mảng ký tự trên heap. Tạo thêm một bản copy nữa sẽ thừa (và buộc concatenate() phải nhớ giải phóng bản copy của nó). Thay vào đó, hàm này sẽ nhận quyền sở hữu chuỗi bạn đưa vào.
Như thường lệ, để ghép nối các chức năng này, ta cần thêm một vài include.
#include "debug.h"
#include "object.h" #include "memory.h"
#include "vm.h"
19 . 5Giải phóng Object
Hãy xem biểu thức tưởng chừng vô hại này:
"st" + "ri" + "ng"
Khi compiler xử lý đoạn này, nó sẽ cấp phát một ObjString cho từng string literal trong ba cái trên, lưu chúng vào constant table của chunk và sinh ra bytecode như sau:
0000 OP_CONSTANT 0 "st" 0002 OP_CONSTANT 1 "ri" 0004 OP_ADD 0005 OP_CONSTANT 2 "ng" 0007 OP_ADD 0008 OP_RETURN
Hai lệnh đầu đẩy "st" và "ri" lên stack. Sau đó, OP_ADD pop hai giá trị này và nối chúng lại. Việc này cấp phát động một string "stri" mới trên heap. VM đẩy string đó lên stack rồi đẩy tiếp hằng "ng". Lệnh OP_ADD cuối cùng pop "stri" và "ng", nối chúng lại và đẩy kết quả "string". Hoàn hảo, đúng như mong đợi.
Nhưng, khoan đã. "stri" kia đâu rồi? Ta đã cấp phát động nó, rồi VM loại bỏ nó sau khi nối với "ng". Ta pop nó khỏi stack và không còn tham chiếu nào tới nó nữa, nhưng lại chưa bao giờ giải phóng bộ nhớ của nó. Đây chính là một ví dụ kinh điển của memory leak.
Tất nhiên, với chương trình Lox, việc “quên” các string trung gian và không bận tâm giải phóng chúng là hoàn toàn ổn. Lox tự động quản lý bộ nhớ thay người dùng. Nhưng trách nhiệm quản lý bộ nhớ không biến mất, mà rơi vào tay chúng ta — những người hiện thực VM.
Giải pháp đầy đủ là một garbage collector thu hồi bộ nhớ không dùng tới khi chương trình đang chạy. Nhưng ta còn vài thứ khác cần chuẩn bị trước khi bắt tay vào dự án đó. Cho tới lúc đó, ta đang “sống nhờ” thời gian vay mượn. Càng để lâu mới thêm GC, việc tích hợp sẽ càng khó.
Hôm nay, ta ít nhất nên làm điều tối thiểu: tránh rò rỉ bộ nhớ bằng cách đảm bảo VM vẫn có thể tìm thấy mọi object đã cấp phát, ngay cả khi bản thân chương trình Lox không còn tham chiếu tới chúng. Có nhiều kỹ thuật tinh vi mà các bộ quản lý bộ nhớ tiên tiến dùng để cấp phát và theo dõi object. Ta sẽ chọn cách đơn giản và thực tế nhất.
Ta sẽ tạo một linked list lưu mọi Obj. VM có thể duyệt danh sách này để tìm tất cả object đã được cấp phát trên heap, bất kể chương trình người dùng hay stack của VM còn giữ tham chiếu tới chúng hay không.
Ta có thể định nghĩa một struct node linked list riêng, nhưng như vậy lại phải cấp phát thêm. Thay vào đó, ta sẽ dùng intrusive list — chính struct Obj sẽ đóng vai trò node của linked list. Mỗi Obj có một con trỏ tới Obj tiếp theo trong chuỗi.
struct Obj {
ObjType type;
in struct Obj
struct Obj* next;
};
VM lưu một con trỏ tới head của danh sách.
Value* stackTop;
in struct VM
Obj* objects;
} VM;
Khi khởi tạo VM, chưa có object nào được cấp phát.
resetStack();
in initVM()
vm.objects = NULL;
}
Mỗi khi cấp phát một Obj, ta chèn nó vào danh sách.
object->type = type;
in allocateObject()
object->next = vm.objects; vm.objects = object;
return object;
Vì đây là singly linked list, chèn vào đầu là dễ nhất. Như vậy, ta không cần lưu thêm con trỏ tới tail và cập nhật nó.
Module “object” đang dùng trực tiếp biến toàn cục vm từ module “vm”, nên ta cần export nó ra ngoài.
} InterpretResult;
add after enum InterpretResult
extern VM vm;
void initVM();
Cuối cùng, GC sẽ giải phóng bộ nhớ khi VM vẫn đang chạy. Nhưng ngay cả khi đó, thường vẫn còn những object không dùng nữa nằm lại trong bộ nhớ khi chương trình người dùng kết thúc. VM cũng nên giải phóng chúng.
Không cần logic phức tạp cho việc này. Khi chương trình kết thúc, ta có thể giải phóng mọi object. Ta có thể và nên hiện thực điều đó ngay bây giờ.
void freeVM() {
in freeVM()
freeObjects();
}
Hàm trống mà ta định nghĩa từ trước giờ cuối cùng cũng có việc! Nó gọi hàm này:
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
add after reallocate()
void freeObjects();
#endif
Cách ta giải phóng object như sau:
add after reallocate()
void freeObjects() { Obj* object = vm.objects; while (object != NULL) { Obj* next = object->next; freeObject(object); object = next; } }
Đây là hiện thực “sách giáo khoa” của CS 101 về việc duyệt linked list và giải phóng các node. Với mỗi node, ta gọi:
add after reallocate()
static void freeObject(Obj* object) { switch (object->type) { case OBJ_STRING: { ObjString* string = (ObjString*)object; FREE_ARRAY(char, string->chars, string->length + 1); FREE(ObjString, object); break; } } }
Ta không chỉ giải phóng bản thân Obj. Vì một số loại object cũng cấp phát bộ nhớ khác mà chúng sở hữu, ta cần thêm chút code đặc thù cho từng loại để xử lý nhu cầu riêng. Ở đây, điều đó nghĩa là ta giải phóng mảng ký tự rồi mới giải phóng ObjString. Cả hai đều dùng một macro quản lý bộ nhớ cuối cùng.
(type*)reallocate(NULL, 0, sizeof(type) * (count))
#define FREE(type, pointer) reallocate(pointer, sizeof(type), 0)
#define GROW_CAPACITY(capacity) \
Đây là một wrapper nhỏ quanh reallocate() để “resize” một vùng nhớ xuống 0 byte.
Như thường lệ, ta cần một include để kết nối mọi thứ lại.
#include "common.h"
#include "object.h"
#define ALLOCATE(type, count) \
Sau đó, trong file hiện thực:
#include "memory.h"
#include "vm.h"
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
Với điều này, VM của ta sẽ không còn rò rỉ bộ nhớ nữa. Giống như một chương trình C tốt, nó sẽ dọn dẹp “mớ hỗn độn” của mình trước khi thoát. Nhưng nó sẽ không giải phóng bất kỳ object nào khi VM đang chạy. Sau này, khi có thể viết các chương trình Lox chạy lâu hơn, VM sẽ tiêu tốn ngày càng nhiều bộ nhớ mà không trả lại một byte nào cho tới khi toàn bộ chương trình kết thúc.
Ta sẽ chưa xử lý điều đó cho tới khi thêm một garbage collector thực sự, nhưng đây là một bước tiến lớn. Giờ ta đã có hạ tầng để hỗ trợ nhiều loại object được cấp phát động khác nhau. Và ta đã dùng nó để thêm string vào clox — một trong những kiểu được sử dụng nhiều nhất trong hầu hết các ngôn ngữ lập trình. String lại mở đường cho ta xây dựng một kiểu dữ liệu nền tảng khác, đặc biệt trong các ngôn ngữ động: hash table “lão làng”. Nhưng đó sẽ là chuyện của chương sau…
19 . 6Thử thách
-
Mỗi string hiện cần hai lần cấp phát động riêng biệt — một cho ObjString và một cho mảng ký tự. Việc truy cập ký tự từ một value cần hai lần gián tiếp qua con trỏ, điều này có thể gây ảnh hưởng tới hiệu năng. Một giải pháp hiệu quả hơn dựa trên kỹ thuật gọi là flexible array members. Hãy dùng kỹ thuật này để lưu ObjString và mảng ký tự của nó trong cùng một vùng cấp phát liên tục.
-
Khi ta tạo ObjString cho mỗi string literal, ta copy các ký tự lên heap. Cách này đảm bảo rằng khi string được giải phóng sau này, ta biết chắc là an toàn để giải phóng cả mảng ký tự.
Đây là cách tiếp cận đơn giản hơn nhưng lãng phí một chút bộ nhớ, điều này có thể là vấn đề trên các thiết bị bị giới hạn tài nguyên. Thay vào đó, ta có thể theo dõi xem ObjString nào sở hữu mảng ký tự của nó và ObjString nào là “constant string” chỉ trỏ ngược lại chuỗi nguồn gốc hoặc một vị trí khác không được phép giải phóng. Hãy thêm hỗ trợ cho điều này.
-
Nếu Lox là ngôn ngữ của bạn, bạn muốn nó làm gì khi người dùng thử dùng
+với một toán hạng là string và toán hạng còn lại là kiểu khác? Hãy giải thích lựa chọn của bạn. Các ngôn ngữ khác làm gì trong trường hợp này?
19 . 7Ghi chú thiết kế: Mã hóa chuỗi (String Encoding)
Trong cuốn sách này, tôi cố gắng không né tránh những vấn đề rắc rối mà bạn sẽ gặp phải khi hiện thực một ngôn ngữ thực thụ. Chúng ta có thể không phải lúc nào cũng dùng giải pháp tinh vi nhất — dù sao đây cũng là sách nhập môn — nhưng tôi không nghĩ là trung thực nếu giả vờ như vấn đề đó không tồn tại. Tuy nhiên, tôi đã lướt qua một nan đề thực sự khó nhằn: quyết định cách biểu diễn chuỗi.
Có hai khía cạnh trong việc mã hóa chuỗi:
-
Thế nào là một “ký tự” trong chuỗi? Có bao nhiêu giá trị khác nhau và chúng biểu diễn điều gì? Câu trả lời tiêu chuẩn đầu tiên được chấp nhận rộng rãi là ASCII. Nó cho bạn 127 giá trị ký tự khác nhau và quy định rõ chúng là gì. Rất tuyệt… nếu bạn chỉ quan tâm đến tiếng Anh. Dù có những ký tự kỳ lạ, hầu như đã bị lãng quên như “record separator” hay “synchronous idle”, nó lại không có nổi một ký tự umlaut, acute hay grave nào. Nó không thể biểu diễn “jalapeño”, “naïve”, “Gruyère”, hay “Mötley Crüe”.
Tiếp theo là Unicode. Ban đầu, nó hỗ trợ 16.384 ký tự khác nhau (code point), vừa khít trong 16 bit và vẫn dư vài bit. Sau đó con số này tăng dần, và giờ đã có hơn 100.000 code point khác nhau, bao gồm cả những “công cụ” giao tiếp thiết yếu của loài người như 💩 (Unicode Character ‘PILE OF POO’,
U+1F4A9).Ngay cả danh sách dài code point đó cũng chưa đủ để biểu diễn mọi glyph hiển thị mà một ngôn ngữ có thể hỗ trợ. Để xử lý điều này, Unicode còn có combining character để biến đổi code point đứng trước. Ví dụ, “a” theo sau bởi combining character “¨” sẽ thành “ä”. (Để mọi thứ rối hơn, Unicode cũng có một code point đơn lẻ trông giống hệt “ä”.)
Nếu người dùng truy cập “ký tự” thứ tư trong “naïve”, họ mong nhận về “v” hay “¨”? Trường hợp đầu nghĩa là họ coi mỗi code point và combining character của nó là một đơn vị duy nhất — thứ mà Unicode gọi là extended grapheme cluster — trường hợp sau nghĩa là họ đang nghĩ theo từng code point riêng lẻ. Người dùng của bạn sẽ mong điều gì?
-
Một đơn vị được biểu diễn trong bộ nhớ như thế nào? Hầu hết các hệ thống dùng ASCII cấp một byte cho mỗi ký tự và bỏ trống bit cao. Unicode có một vài cách mã hóa phổ biến. UTF-16 nhét hầu hết code point vào 16 bit. Điều này rất ổn khi mọi code point đều vừa trong kích thước đó. Khi vượt quá, họ thêm surrogate pair dùng nhiều đơn vị 16-bit để biểu diễn một code point. UTF-32 là bước tiến tiếp theo của UTF-16 — cấp hẳn 32 bit cho từng code point.
UTF-8 phức tạp hơn cả hai. Nó dùng số byte biến đổi để mã hóa một code point. Code point có giá trị nhỏ hơn thì dùng ít byte hơn. Vì mỗi ký tự có thể chiếm số byte khác nhau, bạn không thể truy cập trực tiếp vào một vị trí trong chuỗi để tìm code point cụ thể. Nếu muốn lấy code point thứ 10, bạn sẽ không biết nó nằm ở byte thứ bao nhiêu nếu không duyệt và giải mã tất cả các code point trước đó.
Việc chọn cách biểu diễn ký tự và mã hóa liên quan đến những đánh đổi cơ bản. Giống như nhiều thứ trong kỹ thuật, không có giải pháp hoàn hảo:
-
ASCII tiết kiệm bộ nhớ và nhanh, nhưng bỏ rơi các ngôn ngữ phi Latin.
-
UTF-32 nhanh và hỗ trợ toàn bộ dải Unicode, nhưng lãng phí nhiều bộ nhớ vì hầu hết code point nằm ở vùng giá trị thấp, nơi không cần tới 32 bit đầy đủ.
-
UTF-8 tiết kiệm bộ nhớ và hỗ trợ toàn bộ dải Unicode, nhưng mã hóa độ dài biến đổi khiến việc truy cập ngẫu nhiên code point chậm.
-
UTF-16 tệ hơn tất cả — một hệ quả xấu xí của việc Unicode vượt quá phạm vi 16-bit ban đầu. Nó kém hiệu quả về bộ nhớ hơn UTF-8 nhưng vẫn là mã hóa độ dài biến đổi do có surrogate pair. Tránh nó nếu có thể. Tiếc là nếu ngôn ngữ của bạn cần chạy trên hoặc tương tác với trình duyệt, JVM, hoặc CLR, bạn có thể sẽ phải dùng nó, vì tất cả những nền tảng đó dùng UTF-16 cho string và bạn sẽ không muốn phải chuyển đổi mỗi khi truyền string xuống hệ thống bên dưới.
Một lựa chọn là tiếp cận tối đa và làm “đúng” nhất. Hỗ trợ toàn bộ code point Unicode. Nội bộ, chọn mã hóa cho từng chuỗi dựa trên nội dung của nó — dùng ASCII nếu mọi code point vừa trong một byte, UTF-16 nếu không có surrogate pair, v.v. Cung cấp API cho phép người dùng duyệt cả code point và extended grapheme cluster.
Cách này bao quát mọi trường hợp nhưng rất phức tạp. Rất nhiều việc để hiện thực, debug và tối ưu. Khi tuần tự hóa chuỗi hoặc tương tác với hệ thống khác, bạn phải xử lý tất cả các dạng mã hóa. Người dùng cần hiểu cả hai API duyệt và biết khi nào dùng cái nào. Đây là cách mà các ngôn ngữ mới, lớn thường chọn — như Raku và Swift.
Một thỏa hiệp đơn giản hơn là luôn mã hóa bằng UTF-8 và chỉ cung cấp API làm việc với code point. Với người dùng muốn làm việc với grapheme cluster, hãy để họ dùng thư viện bên thứ ba. Cách này ít thiên vị Latin hơn ASCII nhưng không phức tạp hơn nhiều. Bạn mất khả năng truy cập trực tiếp nhanh theo code point, nhưng thường có thể sống mà không cần hoặc chấp nhận độ phức tạp O(n) thay vì O(1).
Nếu tôi thiết kế một ngôn ngữ “trâu cày” lớn cho những người viết ứng dụng quy mô lớn, có lẽ tôi sẽ chọn cách tiếp cận tối đa. Với ngôn ngữ script nhúng nhỏ Wren của mình, tôi chọn UTF-8 và code point.