Hash Tables
Hash, x. Không có định nghĩa nào cho từ này — chẳng ai biết hash là gì.
Ambrose Bierce, The Unabridged Devil’s Dictionary
Trước khi có thể thêm biến vào chiếc máy ảo đang dần hình thành của chúng ta, ta cần một cách để tra cứu giá trị dựa trên tên biến. Sau này, khi thêm class, ta cũng sẽ cần một cách để lưu trữ field trên các instance. Cấu trúc dữ liệu hoàn hảo cho những vấn đề này (và nhiều vấn đề khác) chính là hash table.
Có lẽ bạn đã biết hash table là gì, dù có thể không gọi nó bằng tên đó. Nếu bạn là lập trình viên Java, bạn gọi nó là “HashMap”. Người dùng C# và Python gọi nó là “dictionary”. Trong C++, nó là “unordered map”. “Object” trong JavaScript và “table” trong Lua thực chất là hash table bên dưới, và đó là thứ mang lại sự linh hoạt cho chúng.
Hash table, bất kể ngôn ngữ của bạn gọi nó là gì, sẽ ánh xạ một tập key tới một tập value. Mỗi cặp key/value là một entry trong bảng. Với một key, bạn có thể tra ra value tương ứng. Bạn có thể thêm cặp key/value mới và xóa entry theo key. Nếu bạn thêm một value mới cho một key đã tồn tại, nó sẽ thay thế entry trước đó.
Hash table xuất hiện trong rất nhiều ngôn ngữ vì chúng cực kỳ mạnh mẽ. Phần lớn sức mạnh này đến từ một đặc tính: với một key, hash table trả về value tương ứng trong thời gian hằng, bất kể trong bảng có bao nhiêu key.
Điều này thật đáng kinh ngạc nếu bạn nghĩ kỹ. Hãy tưởng tượng bạn có một chồng danh thiếp lớn và tôi nhờ bạn tìm một người cụ thể. Chồng càng lớn, thời gian tìm càng lâu. Ngay cả khi chồng đó được sắp xếp gọn gàng và bạn đủ khéo léo để tìm kiếm nhị phân bằng tay, bạn vẫn đang nói về O(log n). Nhưng với một hash table, thời gian tìm tấm danh thiếp đó sẽ như nhau dù chồng chỉ có mười tấm hay một triệu tấm.
20 . 1Mảng các bucket (An Array of Buckets)
Một hash table hoàn chỉnh và nhanh có vài thành phần chuyển động. Tôi sẽ giới thiệu từng phần một bằng cách đi qua vài bài toán nhỏ và lời giải của chúng. Cuối cùng, ta sẽ xây dựng được một cấu trúc dữ liệu có thể ánh xạ bất kỳ tập tên nào tới giá trị của chúng.
Trước mắt, hãy tưởng tượng nếu Lox bị hạn chế hơn nhiều về tên biến. Giả sử tên biến chỉ có thể là một chữ cái thường duy nhất. Làm sao ta có thể biểu diễn tập tên biến và giá trị của chúng một cách hiệu quả nhất?
Với chỉ 26 biến khả dĩ (27 nếu bạn tính cả dấu gạch dưới là một “chữ cái”), câu trả lời rất đơn giản. Khai báo một mảng kích thước cố định 26 phần tử. Theo truyền thống, ta gọi mỗi phần tử là một bucket. Mỗi bucket đại diện cho một biến, với a bắt đầu ở chỉ số 0. Nếu có giá trị trong mảng tại chỉ số của một chữ cái nào đó, thì key đó tồn tại với value tương ứng. Ngược lại, bucket đó rỗng và cặp key/value đó không có trong cấu trúc dữ liệu.
Mức sử dụng bộ nhớ rất tốt — chỉ một mảng duy nhất với kích thước hợp lý. Có một chút lãng phí từ các bucket rỗng, nhưng không đáng kể. Không có overhead cho con trỏ node, padding, hay các thứ khác như khi dùng linked list hoặc tree.
Hiệu năng thì còn tốt hơn. Với một tên biến — tức ký tự của nó — bạn chỉ cần trừ đi giá trị ASCII của a và dùng kết quả để truy cập trực tiếp vào mảng. Sau đó, bạn có thể tra giá trị hiện có hoặc lưu giá trị mới trực tiếp vào ô đó. Khó mà nhanh hơn được nữa.
Đây gần như là cấu trúc dữ liệu “lý tưởng” của chúng ta. Nhanh như chớp, cực kỳ đơn giản, và gọn nhẹ trong bộ nhớ. Khi ta thêm hỗ trợ cho key phức tạp hơn, sẽ phải chấp nhận vài nhượng bộ, nhưng đây là mục tiêu hướng tới. Ngay cả khi thêm hàm băm, thay đổi kích thước động, và xử lý va chạm, lõi của mọi hash table vẫn là một mảng bucket liên tiếp mà bạn có thể truy cập trực tiếp.
20 . 1 . 1Load factor & khóa bị “gói” (wrapped keys)
Giới hạn Lox chỉ dùng biến một chữ cái sẽ khiến công việc của chúng ta — những người implement — dễ dàng hơn, nhưng lập trình trong một ngôn ngữ chỉ cho bạn 26 vị trí lưu trữ thì chắc chẳng vui vẻ gì. Vậy nếu ta nới lỏng một chút và cho phép biến dài tối đa tám ký tự thì sao?
Độ dài này đủ nhỏ để ta có thể nhét cả tám ký tự vào một số nguyên 64-bit và dễ dàng biến chuỗi thành một con số. Ta có thể dùng nó làm chỉ số mảng. Hoặc, ít nhất, ta có thể nếu bằng cách nào đó ta cấp phát được một mảng 295.148 petabyte. Bộ nhớ ngày nay rẻ hơn trước, nhưng chưa rẻ đến mức đó. Ngay cả khi có thể tạo một mảng lớn như vậy, thì nó cũng cực kỳ lãng phí. Hầu như mọi bucket sẽ rỗng trừ khi người dùng bắt đầu viết các chương trình Lox lớn hơn nhiều so với dự kiến của chúng ta.
Dù khóa biến của ta bao phủ toàn bộ dải số 64-bit, rõ ràng ta không cần một mảng lớn đến thế. Thay vào đó, ta cấp phát một mảng có sức chứa dư dả cho số entry cần dùng, nhưng không quá lớn. Ta ánh xạ toàn bộ khóa 64-bit xuống phạm vi nhỏ hơn này bằng cách lấy giá trị modulo kích thước mảng. Làm vậy về cơ bản là “gấp” dải số lớn hơn vào chính nó cho đến khi vừa với phạm vi nhỏ hơn của các phần tử mảng.
Ví dụ, giả sử ta muốn lưu "bagel". Ta cấp phát một mảng tám phần tử, dư sức để lưu nó và nhiều thứ khác sau này. Ta coi chuỗi khóa như một số nguyên 64-bit. Trên máy little-endian như Intel, việc đóng gói các ký tự đó vào một từ 64-bit sẽ đặt chữ cái đầu tiên "b" (giá trị ASCII 98) vào byte ít quan trọng nhất. Ta lấy số nguyên đó modulo kích thước mảng (8) để vừa trong phạm vi và được chỉ số bucket là 2. Sau đó ta lưu giá trị vào đó như bình thường.
Dùng kích thước mảng làm số chia modulo cho phép ta ánh xạ dải số của khóa xuống vừa với mảng có kích thước bất kỳ. Nhờ đó, ta có thể kiểm soát số lượng bucket độc lập với dải khóa. Điều này giải quyết vấn đề lãng phí, nhưng lại tạo ra một vấn đề mới. Bất kỳ hai biến nào có số khóa cho cùng một số dư khi chia cho kích thước mảng sẽ rơi vào cùng một bucket. Các khóa có thể xung đột. Ví dụ, nếu ta thêm "jam", nó cũng rơi vào bucket số 2.
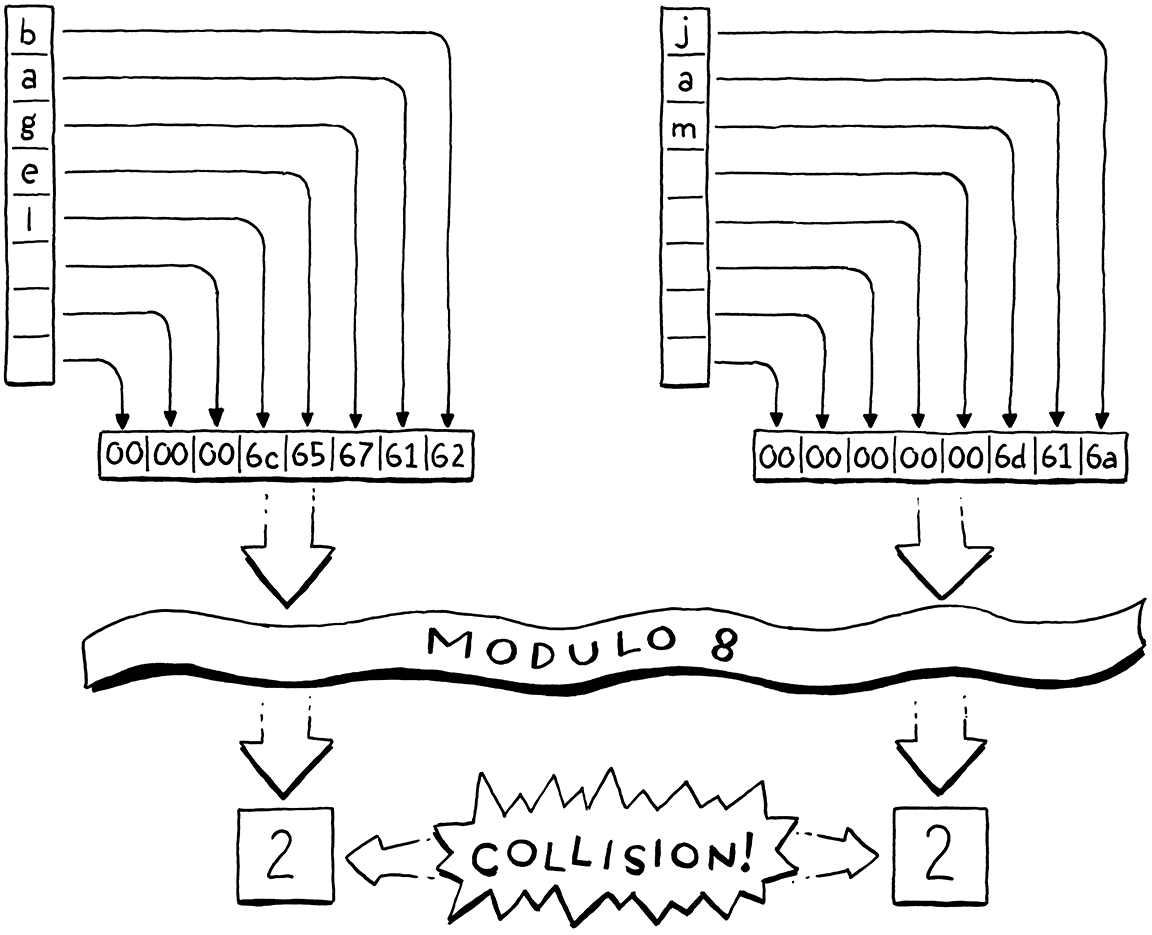
Ta có thể kiểm soát phần nào điều này bằng cách điều chỉnh kích thước mảng. Mảng càng lớn, càng ít chỉ số bị ánh xạ vào cùng một bucket và càng ít khả năng xảy ra xung đột. Người implement hash table theo dõi khả năng xung đột này bằng cách đo load factor của bảng. Nó được định nghĩa là số lượng entry chia cho số lượng bucket. Ví dụ, một hash table có năm entry và mảng 16 phần tử sẽ có load factor là 0.3125. Load factor càng cao, khả năng xung đột càng lớn.
Một cách để giảm xung đột là thay đổi kích thước mảng. Giống như dynamic array mà ta đã implement trước đó, ta sẽ cấp phát lại và tăng kích thước mảng của hash table khi nó đầy dần. Tuy nhiên, khác với dynamic array thông thường, ta sẽ không đợi đến khi mảng đầy. Thay vào đó, ta chọn một load factor mong muốn và tăng kích thước mảng khi nó vượt quá ngưỡng đó.
20 . 2Giải quyết xung đột (Collision Resolution)
Ngay cả với load factor rất thấp, xung đột vẫn có thể xảy ra. Nghịch lý ngày sinh cho ta biết rằng khi số lượng entry trong hash table tăng, khả năng xung đột tăng rất nhanh. Ta có thể chọn kích thước mảng lớn để giảm điều đó, nhưng đây là một cuộc chơi không thể thắng. Giả sử ta muốn lưu 100 phần tử trong hash table. Để giữ khả năng xung đột dưới mức vẫn-khá-cao 10%, ta cần một mảng ít nhất 47.015 phần tử. Để giảm xuống dưới 1% thì cần mảng 492.555 phần tử, tức hơn 4.000 bucket trống cho mỗi bucket được dùng.
Load factor thấp có thể khiến xung đột hiếm hơn, nhưng nguyên lý chuồng bồ câu cho ta biết rằng ta không bao giờ có thể loại bỏ hoàn toàn chúng. Nếu bạn có năm con bồ câu và bốn cái chuồng, ít nhất một chuồng sẽ chứa nhiều hơn một con. Với 18.446.744.073.709.551.616 tên biến khác nhau, bất kỳ mảng có kích thước hợp lý nào cũng có thể chứa nhiều khóa trong cùng một bucket.
Vì vậy, ta vẫn phải xử lý xung đột một cách “êm đẹp” khi chúng xảy ra. Người dùng sẽ không thích nếu ngôn ngữ lập trình của họ chỉ tra cứu biến đúng phần lớn thời gian.
20 . 2 . 1Separate chaining
Các kỹ thuật giải quyết xung đột được chia thành hai nhóm lớn. Nhóm đầu tiên là separate chaining. Thay vì mỗi bucket chỉ chứa một entry, ta cho phép nó chứa một tập hợp entry. Trong cách implement kinh điển, mỗi bucket trỏ tới một linked list các entry. Để tra cứu một entry, bạn tìm bucket của nó rồi duyệt danh sách cho đến khi tìm thấy entry có key khớp.
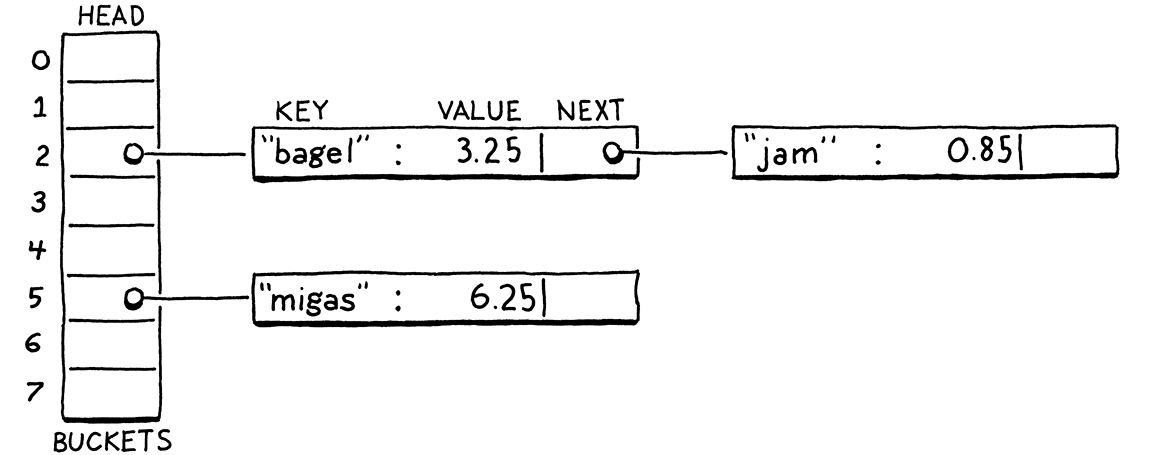
Trong những trường hợp cực kỳ tệ hại khi mọi entry đều xung đột và rơi vào cùng một bucket, cấu trúc dữ liệu sẽ thoái hóa thành một linked list chưa được sắp xếp với thời gian tra cứu O(n). Trên thực tế, rất dễ để tránh điều đó bằng cách kiểm soát load factor và cách phân tán entry vào các bucket. Trong các hash table dùng separate chaining thông thường, hiếm khi một bucket có nhiều hơn một hoặc hai entry.
Separate chaining về mặt khái niệm rất đơn giản — đúng nghĩa là một mảng các linked list. Hầu hết các thao tác đều dễ implement, kể cả xóa (mà như ta sẽ thấy, đôi khi khá phiền). Nhưng nó không phù hợp lắm với CPU hiện đại. Nó có nhiều overhead từ con trỏ và có xu hướng rải các node linked list nhỏ khắp bộ nhớ, điều này không tốt cho việc sử dụng cache.
20 . 2 . 2Open addressing
Kỹ thuật còn lại được gọi là open addressing hoặc (gây nhầm lẫn) closed hashing. Với kỹ thuật này, tất cả entry nằm trực tiếp trong mảng bucket, mỗi bucket một entry. Nếu hai entry xung đột và rơi vào cùng một bucket, ta sẽ tìm một bucket trống khác để dùng.
Lưu tất cả entry trong một mảng lớn, liên tiếp rất tốt để giữ cấu trúc bộ nhớ đơn giản và nhanh. Nhưng điều này khiến mọi thao tác trên hash table trở nên phức tạp hơn. Khi chèn một entry, bucket của nó có thể đã đầy, buộc ta phải tìm bucket khác. Bucket đó cũng có thể đã bị chiếm, và cứ thế tiếp tục. Quá trình tìm bucket trống này được gọi là probing, và thứ tự bạn duyệt qua các bucket được gọi là probe sequence.
Có nhiều thuật toán để xác định bucket nào sẽ probe và cách quyết định entry nào sẽ vào bucket nào. Đã có rất nhiều nghiên cứu về chủ đề này vì chỉ cần thay đổi nhỏ cũng có thể ảnh hưởng lớn đến hiệu năng. Và với một cấu trúc dữ liệu được dùng nhiều như hash table, tác động hiệu năng này sẽ ảnh hưởng tới rất nhiều chương trình thực tế trên nhiều loại phần cứng khác nhau.
Như thường lệ trong cuốn sách này, ta sẽ chọn cách đơn giản nhất nhưng vẫn hiệu quả. Đó là linear probing quen thuộc. Khi tìm một entry, ta tra bucket đầu tiên mà key của nó ánh xạ tới. Nếu không có ở đó, ta tra phần tử kế tiếp trong mảng, và cứ thế tiếp tục. Nếu đến cuối mảng, ta quay vòng lại từ đầu.
Điểm tốt của linear probing là nó thân thiện với cache. Vì bạn duyệt mảng theo đúng thứ tự bộ nhớ, nó giữ cho các cache line của CPU luôn đầy và hoạt động hiệu quả. Điểm xấu là nó dễ bị clustering. Nếu bạn có nhiều entry với giá trị key gần nhau về mặt số học, bạn có thể gặp nhiều bucket liền kề bị xung đột và tràn.
So với separate chaining, open addressing có thể khó hình dung hơn. Tôi nghĩ về open addressing như một dạng separate chaining nhưng “danh sách” các node được xâu chuỗi ngay trong mảng bucket. Thay vì lưu liên kết giữa chúng bằng con trỏ, các kết nối được tính ngầm dựa trên thứ tự bạn duyệt qua các bucket.
Điểm khó là có thể có nhiều hơn một “danh sách” ngầm như vậy được xen kẽ với nhau. Hãy cùng đi qua một ví dụ bao quát các trường hợp thú vị. Ta sẽ bỏ qua value và chỉ quan tâm đến tập key. Ta bắt đầu với một mảng 8 bucket rỗng.

Ta quyết định chèn "bagel". Chữ cái đầu "b" (ASCII 98), modulo kích thước mảng (8) đưa nó vào bucket số 2.

Tiếp theo, ta chèn "jam". Nó cũng muốn vào bucket 2 (106 mod 8 = 2), nhưng bucket đó đã bị chiếm. Ta tiếp tục probe sang bucket kế tiếp. Nó trống, nên ta đặt vào đó.
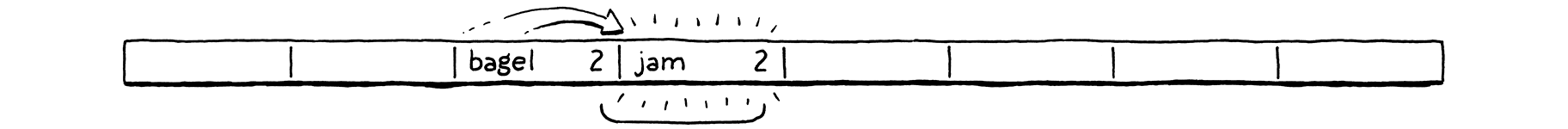
Ta chèn "fruit", và nó vui vẻ rơi vào bucket 6.
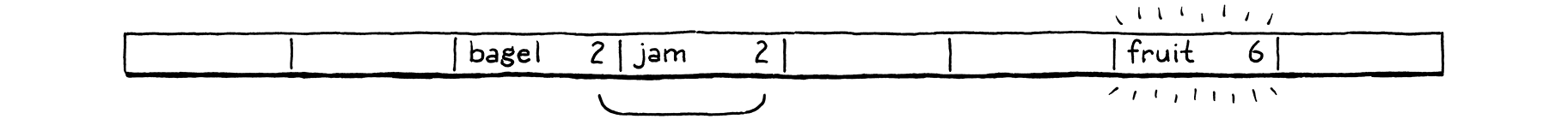
Tương tự, "migas" có thể vào bucket ưa thích của nó là 5.
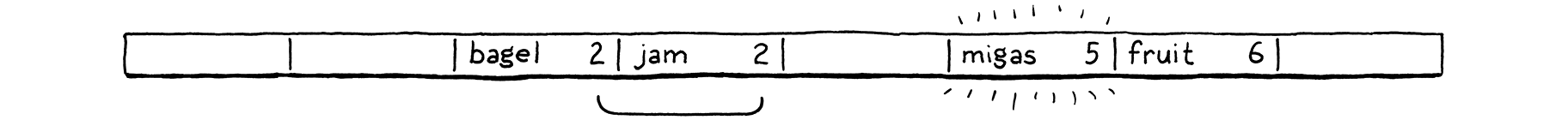
Khi ta thử chèn "eggs", nó cũng muốn vào bucket 5. Bucket đó đầy, nên ta nhảy sang 6. Bucket 6 cũng đầy. Lưu ý rằng entry trong đó không thuộc cùng một probe sequence. "Fruit" đang ở bucket ưa thích của nó, 6. Vậy là các sequence của 5 và 6 đã va chạm và xen kẽ nhau. Ta bỏ qua và cuối cùng đặt "eggs" vào bucket 7.

Ta gặp vấn đề tương tự với "nuts". Nó không thể vào 6 như mong muốn, cũng không thể vào 7. Ta tiếp tục đi. Nhưng đã đến cuối mảng, nên ta quay vòng lại 0 và đặt vào đó.

Trên thực tế, việc xen kẽ này không phải vấn đề lớn. Ngay cả với separate chaining, ta vẫn phải duyệt danh sách để kiểm tra key của từng entry vì nhiều key có thể ánh xạ tới cùng một bucket. Với open addressing, ta cũng cần làm kiểm tra tương tự, và điều đó cũng bao quát cả trường hợp bạn đang bước qua các entry “thuộc” về một bucket gốc khác.
20 . 3Hàm băm (Hash Functions)
Giờ ta đã có thể tự xây dựng một bảng khá hiệu quả để lưu tên biến dài tối đa tám ký tự, nhưng giới hạn đó vẫn khá khó chịu. Để gỡ bỏ rào cản cuối cùng này, ta cần một cách để lấy một chuỗi có độ dài bất kỳ và chuyển nó thành một số nguyên có kích thước cố định.
Cuối cùng thì ta cũng đến phần “hash” trong “hash table”. Hàm băm (hash function) nhận một khối dữ liệu lớn hơn và “băm” nó để tạo ra một số nguyên hash code có kích thước cố định, giá trị của nó phụ thuộc vào tất cả các bit của dữ liệu gốc. Một hàm băm tốt có ba mục tiêu chính:
-
Phải deterministic. Cùng một đầu vào phải luôn băm ra cùng một số. Nếu cùng một biến mà lại rơi vào các bucket khác nhau ở những thời điểm khác nhau, thì việc tìm nó sẽ trở nên cực kỳ khó khăn.
-
Phải uniform. Với một tập đầu vào điển hình, nó nên tạo ra một dải giá trị đầu ra rộng và phân bố đều, càng ít cụm hoặc mẫu lặp càng tốt. Ta muốn nó rải các giá trị khắp toàn bộ dải số để giảm thiểu xung đột và clustering.
-
Phải nhanh. Mọi thao tác trên hash table đều yêu cầu băm key trước. Nếu việc băm chậm, nó có thể triệt tiêu lợi thế tốc độ của việc lưu trữ bằng mảng bên dưới.
Có cả một “núi” hàm băm ngoài kia. Một số thì cũ và được tối ưu cho các kiến trúc mà giờ chẳng ai dùng nữa. Một số được thiết kế để nhanh, số khác thì an toàn về mặt mật mã. Có loại tận dụng tập lệnh vector và kích thước cache cho các chip cụ thể, có loại lại hướng tới khả năng tương thích tối đa.
Có những người mà thiết kế và đánh giá hàm băm là “đam mê” của họ. Tôi rất ngưỡng mộ, nhưng tôi không đủ giỏi toán để trở thành một người như vậy. Thế nên, với clox, tôi chọn một hàm băm đơn giản, lâu đời và đáng tin cậy tên là FNV-1a mà tôi đã dùng nhiều năm nay. Bạn có thể thử các loại khác trong code của mình và xem chúng có tạo ra khác biệt không.
OK, vậy là ta đã lướt qua bucket, load factor, open addressing, giải quyết xung đột và hàm băm. Khá nhiều chữ mà chưa có nhiều code thực tế. Đừng lo nếu mọi thứ vẫn còn mơ hồ. Khi ta code xong, mọi thứ sẽ sáng tỏ.
20 . 4Xây dựng Hash Table
Điều tuyệt vời của hash table so với các kỹ thuật kinh điển khác như balanced search tree là cấu trúc dữ liệu thực tế của nó rất đơn giản. Phần của chúng ta sẽ nằm trong một module mới.
create new file
#ifndef clox_table_h #define clox_table_h #include "common.h" #include "value.h" typedef struct { int count; int capacity; Entry* entries; } Table; #endif
Một hash table là một mảng các entry. Giống như dynamic array trước đây, ta theo dõi cả kích thước mảng đã cấp phát (capacity) và số lượng cặp key/value hiện đang lưu (count). Tỷ lệ giữa count và capacity chính là load factor của hash table.
Mỗi entry là một trong số này:
#include "value.h"
typedef struct { ObjString* key; Value value; } Entry;
typedef struct {
Đó là một cặp key/value đơn giản. Vì key luôn là một string, ta lưu trực tiếp con trỏ ObjString thay vì bọc nó trong Value. Cách này nhanh hơn và nhỏ gọn hơn một chút.
Để tạo một hash table mới, rỗng, ta khai báo một hàm giống như constructor.
} Table;
add after struct Table
void initTable(Table* table);
#endif
Ta cần một file implement mới để định nghĩa hàm đó. Nhân tiện, hãy include tất cả các file cần thiết luôn.
create new file
#include <stdlib.h> #include <string.h> #include "memory.h" #include "object.h" #include "table.h" #include "value.h" void initTable(Table* table) { table->count = 0; table->capacity = 0; table->entries = NULL; }
Giống như dynamic value array, hash table ban đầu có capacity bằng 0 và mảng NULL. Ta không cấp phát gì cho đến khi cần. Giả sử sau này ta có cấp phát, ta cũng cần có khả năng giải phóng nó.
void initTable(Table* table);
add after initTable()
void freeTable(Table* table);
#endif
Và đây là phần implement “hoành tráng”:
add after initTable()
void freeTable(Table* table) { FREE_ARRAY(Entry, table->entries, table->capacity); initTable(table); }
Một lần nữa, nó trông giống hệt dynamic array. Thực tế, bạn có thể coi hash table về cơ bản là một dynamic array với một chính sách chèn phần tử “kỳ quặc”. Ta không cần kiểm tra NULL ở đây vì FREE_ARRAY() đã xử lý trường hợp đó một cách an toàn.
20 . 4 . 1Băm chuỗi (Hashing strings)
Trước khi có thể bắt đầu đưa các entry vào bảng, ta cần — đúng vậy — băm chúng.
Để đảm bảo các entry được phân bố đều khắp mảng, ta cần một hàm băm tốt, xét đến tất cả các bit của chuỗi key. Nếu nó chỉ xét, ví dụ, vài ký tự đầu tiên, thì một loạt chuỗi có cùng tiền tố sẽ rơi vào cùng một bucket.
Mặt khác, việc duyệt toàn bộ chuỗi để tính hash cũng khá chậm. Ta sẽ mất đi một phần lợi thế hiệu năng của hash table nếu phải duyệt chuỗi mỗi lần tìm key trong bảng. Vậy nên ta sẽ làm điều hiển nhiên: cache nó lại.
Bên trong module “object” ở ObjString, ta thêm:
char* chars;
in struct ObjString
uint32_t hash;
};
Mỗi ObjString lưu hash code của chuỗi nó chứa. Vì string trong Lox là immutable, ta có thể tính hash code một lần ngay từ đầu và chắc chắn rằng nó sẽ không bao giờ bị thay đổi. Việc cache sớm như vậy là hợp lý: cấp phát string và sao chép các ký tự của nó vốn đã là một thao tác O(n), nên đây cũng là lúc tốt để thực hiện phép tính O(n) cho hash của chuỗi.
Bất cứ khi nào ta gọi hàm nội bộ để cấp phát string, ta truyền kèm hash code của nó.
function allocateString()
replace 1 line
static ObjString* allocateString(char* chars, int length, uint32_t hash) {
ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING);
Hàm này chỉ đơn giản lưu hash vào struct.
string->chars = chars;
in allocateString()
string->hash = hash;
return string; }
Phần thú vị nằm ở các hàm gọi nó. allocateString() được gọi từ hai nơi: hàm sao chép một string và hàm nhận quyền sở hữu một string đã được cấp phát động. Ta bắt đầu với hàm đầu tiên.
ObjString* copyString(const char* chars, int length) {
in copyString()
uint32_t hash = hashString(chars, length);
char* heapChars = ALLOCATE(char, length + 1);
Không có gì bí ẩn ở đây. Ta tính hash code rồi truyền nó đi.
memcpy(heapChars, chars, length); heapChars[length] = '\0';
in copyString()
replace 1 line
return allocateString(heapChars, length, hash);
}
Hàm string còn lại cũng tương tự.
ObjString* takeString(char* chars, int length) {
in takeString()
replace 1 line
uint32_t hash = hashString(chars, length); return allocateString(chars, length, hash);
}
Phần code thú vị nằm ở đây:
add after allocateString()
static uint32_t hashString(const char* key, int length) { uint32_t hash = 2166136261u; for (int i = 0; i < length; i++) { hash ^= (uint8_t)key[i]; hash *= 16777619; } return hash; }
Đây là “hàm băm” thực sự trong clox. Thuật toán này gọi là “FNV-1a”, và đây là hàm băm ngắn gọn nhất mà tôi biết nhưng vẫn đủ tốt. Sự ngắn gọn chắc chắn là một ưu điểm trong một cuốn sách muốn cho bạn thấy từng dòng code.
Ý tưởng cơ bản khá đơn giản, và nhiều hàm băm khác cũng theo mẫu này. Bạn bắt đầu với một giá trị hash khởi tạo, thường là một hằng số được chọn kỹ lưỡng với các thuộc tính toán học nhất định. Sau đó, bạn duyệt dữ liệu cần băm. Với mỗi byte (hoặc đôi khi là word), bạn trộn các bit của nó vào giá trị hash theo một cách nào đó, rồi xáo trộn các bit kết quả.
Thế nào là “trộn” và “xáo trộn” có thể rất tinh vi. Nhưng mục tiêu cơ bản vẫn là tính đồng đều — ta muốn các giá trị hash kết quả được rải càng rộng khắp dải số càng tốt để tránh xung đột và clustering.
20 . 4 . 2Chèn entry (Inserting entries)
Giờ các object string đã biết hash code của mình, ta có thể bắt đầu đưa chúng vào hash table.
void freeTable(Table* table);
add after freeTable()
bool tableSet(Table* table, ObjString* key, Value value);
#endif
Hàm này thêm cặp key/value được truyền vào hash table. Nếu một entry cho key đó đã tồn tại, giá trị mới sẽ ghi đè giá trị cũ. Hàm trả về true nếu một entry mới được thêm vào. Đây là phần implement:
add after freeTable()
bool tableSet(Table* table, ObjString* key, Value value) { Entry* entry = findEntry(table->entries, table->capacity, key); bool isNewKey = entry->key == NULL; if (isNewKey) table->count++; entry->key = key; entry->value = value; return isNewKey; }
Phần logic thú vị nhất nằm trong findEntry(), mà ta sẽ nói tới ngay. Nhiệm vụ của hàm đó là nhận một key và xác định bucket nào trong mảng mà nó nên nằm. Nó trả về con trỏ tới bucket đó — tức địa chỉ của Entry trong mảng.
Khi đã có bucket, việc chèn khá đơn giản. Ta cập nhật kích thước của hash table, chú ý không tăng count nếu ta ghi đè giá trị cho một key đã tồn tại. Sau đó, ta sao chép key và value vào các trường tương ứng trong Entry.
Nhưng ở đây vẫn thiếu một chút. Ta chưa thực sự cấp phát mảng Entry. Ối! Trước khi chèn bất cứ thứ gì, ta cần đảm bảo đã có mảng và nó đủ lớn.
bool tableSet(Table* table, ObjString* key, Value value) {
in tableSet()
if (table->count + 1 > table->capacity * TABLE_MAX_LOAD) { int capacity = GROW_CAPACITY(table->capacity); adjustCapacity(table, capacity); }
Entry* entry = findEntry(table->entries, table->capacity, key);
Phần này tương tự code ta đã viết trước đây để mở rộng dynamic array. Nếu không đủ capacity để chèn một phần tử, ta sẽ cấp phát lại và tăng kích thước mảng. Macro GROW_CAPACITY() nhận capacity hiện tại và tăng nó theo một bội số để đảm bảo hiệu năng trung bình vẫn là hằng số qua nhiều lần chèn.
Điểm khác biệt thú vị ở đây là hằng số TABLE_MAX_LOAD.
#include "value.h"
#define TABLE_MAX_LOAD 0.75
void initTable(Table* table) {
Đây là cách ta quản lý load factor của bảng. Ta không đợi đến khi capacity đầy hẳn mới tăng kích thước. Thay vào đó, ta tăng mảng sớm hơn, khi nó đã đầy ít nhất 75%.
Chúng ta sẽ sớm đến phần implement của adjustCapacity(). Trước hết, hãy xem hàm findEntry() mà bạn đang tò mò.
add after freeTable()
static Entry* findEntry(Entry* entries, int capacity, ObjString* key) { uint32_t index = key->hash % capacity; for (;;) { Entry* entry = &entries[index]; if (entry->key == key || entry->key == NULL) { return entry; } index = (index + 1) % capacity; } }
Hàm này chính là lõi thực sự của hash table. Nó chịu trách nhiệm nhận một key và một mảng bucket, rồi xác định bucket nào mà entry thuộc về. Đây cũng là nơi linear probing và xử lý xung đột được áp dụng. Ta sẽ dùng findEntry() cả khi tra cứu entry đã tồn tại trong hash table lẫn khi quyết định chèn entry mới vào đâu.
Thực ra, nó không quá phức tạp. Đầu tiên, ta dùng phép modulo để ánh xạ hash code của key thành một chỉ số trong phạm vi mảng. Điều đó cho ta một chỉ số bucket mà lý tưởng là ta sẽ tìm thấy hoặc đặt entry vào đó.
Có vài trường hợp cần kiểm tra:
-
Nếu key của Entry tại chỉ số mảng đó là
NULL, nghĩa là bucket trống. Nếu ta dùngfindEntry()để tra cứu, điều này có nghĩa là nó không tồn tại. Nếu dùng để chèn, nghĩa là ta đã tìm được chỗ để thêm entry mới. -
Nếu key trong bucket bằng với key ta đang tìm, nghĩa là key đó đã có trong bảng. Nếu đang tra cứu, tốt — ta đã tìm thấy key cần tìm. Nếu đang chèn, điều này nghĩa là ta sẽ thay thế giá trị cho key đó thay vì thêm entry mới.
- Ngược lại, bucket có một entry nhưng với key khác. Đây là xung đột. Khi đó, ta bắt đầu probing. Đó chính là việc vòng lặp
forđang làm. Ta bắt đầu ở bucket mà entry lý tưởng sẽ nằm. Nếu bucket đó trống hoặc có cùng key, ta xong việc. Nếu không, ta chuyển sang phần tử tiếp theo — đây là phần linear trong “linear probing” — và kiểm tra ở đó. Nếu đi quá cuối mảng, phép modulo thứ hai sẽ đưa ta quay lại đầu.
Ta thoát vòng lặp khi tìm thấy một bucket trống hoặc bucket có cùng key với key đang tìm. Bạn có thể lo về vòng lặp vô hạn. Nếu ta xung đột với mọi bucket thì sao? May mắn là điều đó không thể xảy ra nhờ load factor. Vì ta tăng kích thước mảng ngay khi nó gần đầy, ta biết chắc luôn sẽ có bucket trống.
Ta trả về trực tiếp từ trong vòng lặp, đưa ra con trỏ tới Entry tìm được để caller có thể chèn vào đó hoặc đọc từ đó. Quay lại tableSet(), hàm đã khởi động quá trình này, ta lưu entry mới vào bucket trả về và xong việc.
20 . 4 . 3Cấp phát & thay đổi kích thước
Trước khi có thể đặt entry vào hash table, ta cần một nơi để thực sự lưu chúng. Ta cần cấp phát một mảng bucket. Việc này diễn ra trong hàm sau:
add after findEntry()
static void adjustCapacity(Table* table, int capacity) { Entry* entries = ALLOCATE(Entry, capacity); for (int i = 0; i < capacity; i++) { entries[i].key = NULL; entries[i].value = NIL_VAL; } table->entries = entries; table->capacity = capacity; }
Ta tạo một mảng bucket với capacity entry. Sau khi cấp phát mảng, ta khởi tạo mọi phần tử thành bucket trống rồi lưu mảng (và capacity của nó) vào struct chính của hash table. Đoạn code này ổn khi ta chèn entry đầu tiên vào bảng và cần cấp phát mảng lần đầu. Nhưng nếu ta đã có mảng và cần tăng kích thước thì sao?
Khi làm dynamic array trước đây, ta chỉ cần dùng realloc() và để thư viện chuẩn C sao chép mọi thứ. Điều đó không áp dụng cho hash table. Hãy nhớ rằng để chọn bucket cho mỗi entry, ta lấy hash key modulo kích thước mảng. Nghĩa là khi kích thước mảng thay đổi, entry có thể rơi vào bucket khác.
Những bucket mới đó có thể phát sinh xung đột mới cần xử lý. Vậy nên cách đơn giản nhất để đưa mọi entry về đúng chỗ là xây lại bảng từ đầu bằng cách chèn lại từng entry vào mảng trống mới.
entries[i].value = NIL_VAL; }
in adjustCapacity()
for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; if (entry->key == NULL) continue; Entry* dest = findEntry(entries, capacity, entry->key); dest->key = entry->key; dest->value = entry->value; }
table->entries = entries;
Ta duyệt qua mảng cũ từ đầu đến cuối. Mỗi khi gặp bucket không trống, ta chèn entry đó vào mảng mới. Ta dùng findEntry(), truyền vào mảng mới thay vì mảng hiện đang lưu trong Table. (Đây là lý do findEntry() nhận con trỏ trực tiếp tới mảng Entry chứ không phải toàn bộ struct Table. Nhờ vậy, ta có thể truyền mảng và capacity mới trước khi lưu chúng vào struct.)
Sau khi xong, ta có thể giải phóng bộ nhớ của mảng cũ.
dest->value = entry->value; }
in adjustCapacity()
FREE_ARRAY(Entry, table->entries, table->capacity);
table->entries = entries;
Với điều đó, ta có một hash table mà ta có thể nhét bao nhiêu entry tùy thích. Nó xử lý việc ghi đè key đã tồn tại và tự tăng kích thước khi cần để duy trì load capacity mong muốn.
Nhân tiện, ta cũng định nghĩa một hàm helper để sao chép tất cả entry từ một hash table sang một hash table khác.
bool tableSet(Table* table, ObjString* key, Value value);
add after tableSet()
void tableAddAll(Table* from, Table* to);
#endif
Ta sẽ không cần hàm này cho đến tận sau này khi hỗ trợ kế thừa method, nhưng ta có thể implement luôn khi mọi thứ về hash table vẫn còn mới trong đầu.
add after tableSet()
void tableAddAll(Table* from, Table* to) { for (int i = 0; i < from->capacity; i++) { Entry* entry = &from->entries[i]; if (entry->key != NULL) { tableSet(to, entry->key, entry->value); } } }
Không có gì nhiều để nói ở đây. Nó duyệt mảng bucket của hash table nguồn. Mỗi khi gặp bucket không trống, nó thêm entry đó vào hash table đích bằng cách dùng hàm tableSet() mà ta vừa định nghĩa.
20 . 4 . 4Truy xuất giá trị (Retrieving values)
Giờ hash table của chúng ta đã có dữ liệu, hãy bắt đầu lấy chúng ra. Với một key, ta có thể tra giá trị tương ứng (nếu có) bằng hàm sau:
void freeTable(Table* table);
add after freeTable()
bool tableGet(Table* table, ObjString* key, Value* value);
bool tableSet(Table* table, ObjString* key, Value value);
Bạn truyền vào một table và một key. Nếu tìm thấy entry với key đó, hàm trả về true, ngược lại trả về false. Nếu entry tồn tại, tham số output value sẽ trỏ tới giá trị tìm được.
Vì findEntry() đã làm phần việc khó khăn, phần implement khá đơn giản.
add after findEntry()
bool tableGet(Table* table, ObjString* key, Value* value) { if (table->count == 0) return false; Entry* entry = findEntry(table->entries, table->capacity, key); if (entry->key == NULL) return false; *value = entry->value; return true; }
Nếu table hoàn toàn rỗng, chắc chắn ta sẽ không tìm thấy entry, nên ta kiểm tra điều đó trước. Đây không chỉ là tối ưu hóa — nó còn đảm bảo ta không truy cập mảng bucket khi mảng là NULL. Ngược lại, ta để findEntry() làm nhiệm vụ của nó. Hàm này trả về con trỏ tới một bucket. Nếu bucket trống (phát hiện bằng cách kiểm tra key có phải NULL hay không), nghĩa là không tìm thấy Entry với key của ta. Nếu findEntry() trả về một Entry không trống, thì đó chính là kết quả. Ta lấy giá trị của Entry và sao chép vào tham số output để caller nhận được. Quá đơn giản.
20 . 4 . 5Xóa entry (Deleting entries)
Có một thao tác cơ bản nữa mà một hash table đầy đủ tính năng cần hỗ trợ: xóa một entry. Nghe có vẻ hiển nhiên — nếu bạn có thể thêm dữ liệu, bạn cũng nên có thể gỡ nó đi, đúng không? Nhưng bạn sẽ ngạc nhiên khi thấy nhiều hướng dẫn về hash table bỏ qua phần này.
Tôi cũng có thể đã bỏ qua. Thực tế, trong clox, ta chỉ dùng xóa trong một trường hợp rất nhỏ ở VM. Nhưng nếu bạn muốn thực sự hiểu cách implement hoàn chỉnh một hash table, thì đây là phần quan trọng. Tôi hiểu lý do họ muốn bỏ qua — như ta sẽ thấy, xóa trong hash table dùng open addressing khá phức tạp.
Ít nhất thì phần khai báo cũng đơn giản.
bool tableSet(Table* table, ObjString* key, Value value);
add after tableSet()
bool tableDelete(Table* table, ObjString* key);
void tableAddAll(Table* from, Table* to);
Cách tiếp cận hiển nhiên là làm ngược lại với chèn: dùng findEntry() để tìm bucket của entry, rồi xóa bucket đó. Xong!
Trong trường hợp không có xung đột, cách này hoạt động tốt. Nhưng nếu có xung đột, bucket chứa entry đó có thể là một phần của một hoặc nhiều probe sequence ngầm. Ví dụ, đây là một hash table chứa ba key đều có bucket ưa thích là 2:
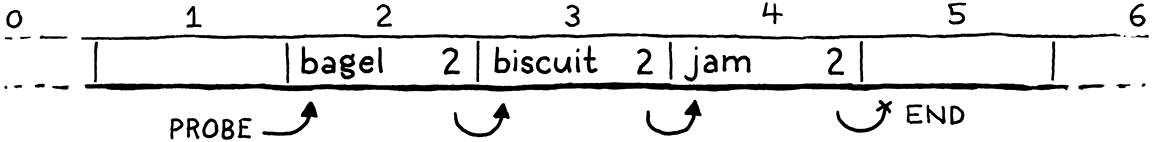
Hãy nhớ rằng khi ta duyệt một probe sequence để tìm entry, ta biết đã đến cuối sequence và entry không tồn tại khi gặp một bucket trống. Giống như một danh sách entry mà một entry trống sẽ kết thúc danh sách đó.
Nếu ta xóa "biscuit" bằng cách đơn giản là xóa Entry, ta sẽ cắt đứt probe sequence ở giữa, khiến các entry phía sau bị “mồ côi” và không thể truy cập. Giống như gỡ một node khỏi linked list mà không nối lại con trỏ từ node trước sang node sau.
Nếu sau đó ta tìm "jam", ta sẽ bắt đầu ở "bagel", dừng lại ở Entry trống tiếp theo và không bao giờ tìm thấy nó.

Để giải quyết, hầu hết các implement dùng một mẹo gọi là tombstone. Thay vì xóa sạch entry, ta thay nó bằng một entry đặc biệt gọi là “tombstone”. Khi duyệt một probe sequence để tra cứu, nếu gặp tombstone, ta không coi nó như một slot trống và dừng lại. Thay vào đó, ta tiếp tục, để việc xóa không phá vỡ chuỗi xung đột ngầm và ta vẫn có thể tìm thấy các entry phía sau.

Code như sau:
add after tableSet()
bool tableDelete(Table* table, ObjString* key) { if (table->count == 0) return false; // Find the entry. Entry* entry = findEntry(table->entries, table->capacity, key); if (entry->key == NULL) return false; // Place a tombstone in the entry. entry->key = NULL; entry->value = BOOL_VAL(true); return true; }
Đầu tiên, ta tìm bucket chứa entry cần xóa. (Nếu không tìm thấy, không có gì để xóa, nên thoát luôn.) Ta thay entry đó bằng một tombstone. Trong clox, ta dùng key NULL và value true để biểu diễn, nhưng bất kỳ cách biểu diễn nào không thể nhầm với bucket trống hoặc entry hợp lệ đều được.
Vậy là xong việc xóa một entry. Đơn giản và nhanh. Nhưng tất cả thao tác khác cũng cần xử lý tombstone đúng cách. Tombstone là một dạng entry “nửa vời”: nó có một số đặc điểm của entry tồn tại, và một số đặc điểm của entry trống.
Khi duyệt một probe sequence để tra cứu, nếu gặp tombstone, ta ghi nhận và tiếp tục.
for (;;) {
Entry* entry = &entries[index];
in findEntry()
replace 3 lines
if (entry->key == NULL) { if (IS_NIL(entry->value)) { // Empty entry. return tombstone != NULL ? tombstone : entry; } else { // We found a tombstone. if (tombstone == NULL) tombstone = entry; } } else if (entry->key == key) { // We found the key. return entry; }
index = (index + 1) % capacity;
Lần đầu gặp tombstone, ta lưu nó vào biến local này:
uint32_t index = key->hash % capacity;
in findEntry()
Entry* tombstone = NULL;
for (;;) {
Nếu gặp một entry thực sự trống, nghĩa là key không tồn tại. Trong trường hợp đó, nếu đã gặp tombstone, ta trả về bucket của nó thay vì bucket trống sau đó. Nếu ta gọi findEntry() để chèn một node, điều này cho phép ta coi bucket tombstone như trống và tái sử dụng cho entry mới.
Tự động tái sử dụng slot tombstone như vậy giúp giảm số lượng tombstone chiếm chỗ trong mảng bucket. Trong các trường hợp sử dụng điển hình có xen kẽ chèn và xóa, số lượng tombstone sẽ tăng một thời gian rồi ổn định.
Dù vậy, không có gì đảm bảo rằng nhiều lần xóa sẽ không khiến mảng đầy tombstone. Trong trường hợp xấu nhất, ta có thể không còn bất kỳ bucket trống nào. Điều đó sẽ rất tệ vì, hãy nhớ, điều duy nhất ngăn vòng lặp vô hạn trong findEntry() là giả định rằng ta sẽ gặp một bucket trống.
Vì vậy, ta cần cân nhắc kỹ cách tombstone tương tác với load factor và việc thay đổi kích thước bảng. Câu hỏi then chốt là: khi tính load factor, ta nên coi tombstone là bucket đầy hay bucket trống?
20 . 4 . 6Đếm tombstone (Counting tombstones)
Nếu ta coi tombstone như bucket đầy, thì có thể sẽ phải dùng một mảng lớn hơn mức cần thiết vì nó làm load factor bị “thổi phồng” giả tạo. Có những tombstone ta có thể tái sử dụng, nhưng vì không coi chúng là bucket trống nên ta sẽ tăng kích thước mảng sớm hơn cần thiết.
Nhưng nếu ta coi tombstone như bucket trống và không tính chúng vào load factor, thì lại có nguy cơ không còn bất kỳ bucket trống thực sự nào để kết thúc quá trình tra cứu. Vòng lặp vô hạn là vấn đề nghiêm trọng hơn nhiều so với việc tốn thêm vài slot mảng, nên khi tính load factor, ta sẽ coi tombstone là bucket đầy.
Đó là lý do tại sao trong đoạn code trước, khi xóa một entry, ta không giảm biến đếm count. Lúc này, count không còn là số lượng entry trong hash table nữa, mà là số entry cộng với số tombstone. Điều này cũng có nghĩa là ta chỉ tăng count khi chèn nếu entry mới được đặt vào một bucket hoàn toàn trống.
bool isNewKey = entry->key == NULL;
in tableSet()
replace 1 line
if (isNewKey && IS_NIL(entry->value)) table->count++;
entry->key = key;
Nếu ta thay thế một tombstone bằng entry mới, bucket đó đã được tính vào count từ trước nên giá trị này không thay đổi.
Khi thay đổi kích thước mảng, ta sẽ cấp phát một mảng mới và chèn lại tất cả entry hiện có vào đó. Trong quá trình này, ta không sao chép các tombstone sang. Chúng không mang lại giá trị gì vì ta đang xây lại toàn bộ probe sequence, và nếu giữ lại chỉ làm chậm tra cứu. Điều này đồng nghĩa ta cần tính lại count vì nó có thể thay đổi khi resize. Vậy nên ta đặt lại nó về 0:
}
in adjustCapacity()
table->count = 0;
for (int i = 0; i < table->capacity; i++) {
Sau đó, mỗi khi gặp một entry không phải tombstone, ta sẽ tăng count.
dest->value = entry->value;
in adjustCapacity()
table->count++;
}
Điều này có nghĩa là khi tăng capacity, ta có thể sẽ có ít entry hơn trong mảng mới vì tất cả tombstone bị loại bỏ. Đây là một chút lãng phí, nhưng không phải vấn đề lớn trong thực tế.
Tôi thấy thú vị ở chỗ phần lớn công việc để hỗ trợ xóa entry lại nằm trong findEntry() và adjustCapacity(). Logic xóa thực tế thì rất đơn giản và nhanh. Trên thực tế, thao tác xóa thường hiếm, nên bạn có thể nghĩ rằng hash table sẽ cố gắng làm nhiều việc nhất có thể trong hàm xóa và để các hàm khác không bị ảnh hưởng để giữ tốc độ. Với cách tiếp cận tombstone, thao tác xóa nhanh, nhưng tra cứu lại bị chậm đi.
Tôi đã thử benchmark trong vài kịch bản xóa khác nhau. Thật bất ngờ, cách dùng tombstone lại nhanh hơn tổng thể so với việc làm toàn bộ công việc tái chèn entry bị ảnh hưởng ngay trong lúc xóa.
Nhưng nếu nghĩ kỹ, cách tombstone không hẳn là “đẩy” công việc xóa hoàn toàn sang các thao tác khác, mà đúng hơn là biến việc xóa thành lười biếng. Ban đầu, nó chỉ làm tối thiểu để biến entry thành tombstone. Điều này có thể gây chậm khi tra cứu sau đó phải bỏ qua nó. Nhưng nó cũng cho phép bucket tombstone được tái sử dụng khi chèn mới. Việc tái sử dụng này là một cách rất hiệu quả để tránh chi phí sắp xếp lại tất cả entry bị ảnh hưởng phía sau. Bạn có thể coi như đang “tái chế” một node trong chuỗi các entry bị probe. Khá là hay.
20 . 5String Interning
Giờ ta đã có một hash table hoạt động khá ổn, dù vẫn có một lỗi nghiêm trọng ở lõi. Hơn nữa, ta vẫn chưa dùng nó cho việc gì. Đã đến lúc xử lý cả hai vấn đề này và, trong quá trình đó, học một kỹ thuật kinh điển mà các interpreter thường dùng.
Nguyên nhân khiến hash table chưa hoạt động hoàn hảo là khi findEntry() kiểm tra xem một key hiện có có khớp với key đang tìm hay không, nó dùng == để so sánh hai string. Điều này chỉ trả về true nếu hai key là cùng một string trong bộ nhớ. Hai string riêng biệt nhưng có cùng ký tự lẽ ra phải được coi là bằng nhau, nhưng lại không.
Hãy nhớ, khi thêm string ở chương trước, ta đã thêm hỗ trợ so sánh từng ký tự của string để có được so sánh giá trị thực sự. Ta có thể làm điều đó trong findEntry(), nhưng như đã nói, nó chậm.
Thay vào đó, ta sẽ dùng một kỹ thuật gọi là string interning. Vấn đề cốt lõi là có thể tồn tại nhiều string khác nhau trong bộ nhớ nhưng có cùng ký tự. Chúng cần được xử lý như các giá trị tương đương dù là object khác nhau. Về bản chất, chúng là bản sao, và ta phải so sánh toàn bộ byte của chúng để phát hiện.
String interning là quá trình loại bỏ trùng lặp. Ta tạo một tập hợp các string “interned”. Bất kỳ string nào trong tập hợp này đều được đảm bảo là khác biệt về mặt nội dung so với tất cả string khác. Khi bạn intern một string, bạn tìm một string khớp trong tập hợp. Nếu tìm thấy, bạn dùng lại string gốc đó. Nếu không, string bạn có là duy nhất, nên bạn thêm nó vào tập hợp.
Bằng cách này, bạn biết rằng mỗi chuỗi ký tự chỉ được biểu diễn bởi một string duy nhất trong bộ nhớ. Điều này khiến việc so sánh bằng giá trị trở nên cực kỳ đơn giản. Nếu hai string trỏ tới cùng một địa chỉ trong bộ nhớ, rõ ràng chúng là cùng một string và chắc chắn bằng nhau. Và vì ta biết string là duy nhất, nếu hai string trỏ tới các địa chỉ khác nhau, chúng chắc chắn là hai string khác nhau.
Do đó, so sánh bằng con trỏ sẽ khớp chính xác với so sánh bằng giá trị. Điều này đồng nghĩa toán tử == hiện tại trong findEntry() đang làm đúng việc. Hoặc ít nhất, nó sẽ đúng khi ta đã intern toàn bộ string. Để có thể loại bỏ trùng lặp tất cả string một cách đáng tin cậy, VM cần có khả năng tìm thấy mọi string được tạo ra. Ta làm điều đó bằng cách cung cấp cho nó một hash table để lưu tất cả chúng.
Value* stackTop;
in struct VM
Table strings;
Obj* objects;
Như thường lệ, ta cần thêm một include.
#include "chunk.h"
#include "table.h"
#include "value.h"
Khi khởi tạo một VM mới, bảng string sẽ rỗng.
vm.objects = NULL;
in initVM()
initTable(&vm.strings);
}
Và khi tắt VM, ta dọn dẹp mọi tài nguyên mà bảng đã dùng.
void freeVM() {
in freeVM()
freeTable(&vm.strings);
freeObjects();
Một số ngôn ngữ có kiểu dữ liệu riêng hoặc bước rõ ràng để intern một string. Với clox, ta sẽ tự động intern tất cả. Điều đó nghĩa là bất cứ khi nào ta tạo một string mới và duy nhất, ta sẽ thêm nó vào bảng.
string->hash = hash;
in allocateString()
tableSet(&vm.strings, string, NIL_VAL);
return string;
Ta đang dùng bảng này giống như một hash set hơn là hash table. Key chính là các string và đó là tất cả những gì ta quan tâm, nên ta chỉ dùng nil cho value.
Điều này sẽ đưa một string vào bảng với giả định nó là duy nhất, nhưng ta cần kiểm tra trùng lặp trước khi đến bước này. Ta làm điều đó trong hai hàm cấp cao hơn gọi allocateString(). Đây là một trong số đó:
uint32_t hash = hashString(chars, length);
in copyString()
ObjString* interned = tableFindString(&vm.strings, chars, length, hash); if (interned != NULL) return interned;
char* heapChars = ALLOCATE(char, length + 1);
Khi sao chép một string thành một LoxString mới, ta tra cứu nó trong bảng string trước. Nếu tìm thấy, thay vì “sao chép”, ta chỉ trả về tham chiếu tới string đó. Nếu không, ta tiếp tục cấp phát string mới và lưu nó vào bảng string.
Việc nhận quyền sở hữu một string thì hơi khác một chút.
uint32_t hash = hashString(chars, length);
in takeString()
ObjString* interned = tableFindString(&vm.strings, chars, length, hash); if (interned != NULL) { FREE_ARRAY(char, chars, length + 1); return interned; }
return allocateString(chars, length, hash);
Một lần nữa, ta tra cứu string trong bảng string trước. Nếu tìm thấy, trước khi trả về, ta giải phóng bộ nhớ của string được truyền vào. Vì quyền sở hữu đã được chuyển cho hàm này và ta không còn cần bản sao string nữa, nên việc giải phóng là trách nhiệm của ta.
Trước khi đến hàm mới cần viết, ta cần thêm một include nữa.
#include "object.h"
#include "table.h"
#include "value.h"
Để tìm một string trong bảng, ta không thể dùng hàm tableGet() thông thường vì nó gọi findEntry(), vốn đang gặp đúng vấn đề trùng lặp string mà ta đang cố sửa. Thay vào đó, ta dùng hàm mới này:
void tableAddAll(Table* from, Table* to);
add after tableAddAll()
ObjString* tableFindString(Table* table, const char* chars, int length, uint32_t hash);
#endif
Phần implement như sau:
add after tableAddAll()
ObjString* tableFindString(Table* table, const char* chars, int length, uint32_t hash) { if (table->count == 0) return NULL; uint32_t index = hash % table->capacity; for (;;) { Entry* entry = &table->entries[index]; if (entry->key == NULL) { // Stop if we find an empty non-tombstone entry. if (IS_NIL(entry->value)) return NULL; } else if (entry->key->length == length && entry->key->hash == hash && memcmp(entry->key->chars, chars, length) == 0) { // We found it. return entry->key; } index = (index + 1) % table->capacity; } }
Có vẻ như ta đã copy-paste findEntry(). Có khá nhiều phần trùng lặp, nhưng cũng có vài điểm khác biệt quan trọng. Thứ nhất, ta truyền vào mảng ký tự thô của key cần tìm thay vì một ObjString. Tại thời điểm gọi hàm này, ta vẫn chưa tạo ObjString.
Thứ hai, khi kiểm tra xem có tìm thấy key hay không, ta so sánh trực tiếp nội dung string. Đầu tiên, ta kiểm tra xem chúng có cùng độ dài và hash hay không. Đây là những phép kiểm tra nhanh, và nếu không bằng nhau thì chắc chắn string không giống nhau.
Nếu có va chạm hash, ta sẽ so sánh từng ký tự một. Đây là nơi duy nhất trong VM mà ta thực sự kiểm tra string theo nội dung. Ta làm điều này ở đây để loại bỏ trùng lặp string, và sau đó phần còn lại của VM có thể mặc định rằng bất kỳ hai string ở các địa chỉ khác nhau trong bộ nhớ đều có nội dung khác nhau.
Thực tế, giờ khi ta đã intern toàn bộ string, ta có thể tận dụng điều này trong bytecode interpreter. Khi người dùng dùng == trên hai object là string, ta không cần so sánh ký tự nữa.
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
in valuesEqual()
replace 7 lines
case VAL_OBJ: return AS_OBJ(a) == AS_OBJ(b);
default: return false; // Unreachable.
Ta đã thêm một chút overhead khi tạo string để intern chúng. Nhưng đổi lại, ở runtime, toán tử so sánh bằng trên string sẽ nhanh hơn nhiều. Với điều đó, ta đã có một hash table đầy đủ tính năng, sẵn sàng để dùng cho việc theo dõi biến, instance, hoặc bất kỳ cặp key-value nào khác.
Ta cũng đã tăng tốc việc so sánh string. Điều này rất hữu ích khi người dùng dùng == trên string. Nhưng nó còn quan trọng hơn trong một ngôn ngữ động như Lox, nơi các lời gọi method và field của instance được tra cứu theo tên ở runtime. Nếu việc so sánh string chậm, thì việc tra cứu method theo tên cũng chậm. Và nếu điều đó chậm trong ngôn ngữ hướng đối tượng của bạn, thì mọi thứ đều chậm.
20 . 6Thử thách
-
Trong clox, ta chỉ cần key là string, nên hash table ta xây dựng được “cứng mã” cho kiểu key này. Nếu ta cung cấp hash table cho người dùng Lox như một collection hạng nhất, sẽ hữu ích nếu hỗ trợ nhiều loại key khác.
Hãy thêm hỗ trợ cho key thuộc các kiểu nguyên thủy khác: number, Boolean, và
nil. Sau này, clox sẽ hỗ trợ class do người dùng định nghĩa. Nếu muốn hỗ trợ key là instance của các class đó, điều này sẽ làm tăng độ phức tạp thế nào? -
Hash table có rất nhiều tham số có thể tinh chỉnh ảnh hưởng đến hiệu năng. Bạn có thể chọn dùng separate chaining hoặc open addressing. Tùy vào lựa chọn, bạn có thể tinh chỉnh số lượng entry lưu trong mỗi node, hoặc chiến lược probing. Bạn kiểm soát hàm băm, load factor, và tốc độ tăng trưởng.
Tất cả sự đa dạng này không chỉ được tạo ra để cho các nghiên cứu sinh ngành khoa học máy tính có cái để công bố luận án: mỗi lựa chọn đều có tác dụng trong nhiều lĩnh vực và kịch bản phần cứng khác nhau nơi hashing được áp dụng. Hãy tìm hiểu một vài implement hash table trong các hệ thống mã nguồn mở khác nhau, nghiên cứu các lựa chọn họ đã thực hiện, và thử tìm lý do tại sao họ làm như vậy.
-
Việc benchmark hash table nổi tiếng là khó. Một implement hash table có thể hoạt động tốt với một số tập key nhưng kém với tập khác. Nó có thể hoạt động tốt ở kích thước nhỏ nhưng giảm hiệu năng khi lớn lên, hoặc ngược lại. Nó có thể gặp vấn đề khi xóa thường xuyên, nhưng lại rất nhanh khi không xóa. Việc tạo benchmark phản ánh chính xác cách người dùng sẽ sử dụng hash table là một thách thức.
Hãy viết một vài chương trình benchmark khác nhau để kiểm tra implement hash table của chúng ta. Hiệu năng thay đổi thế nào giữa các bài test? Tại sao bạn lại chọn các trường hợp kiểm tra đó?