Global Variables
Giá như có một phát minh nào đó có thể đóng chai ký ức, như hương thơm. Và nó sẽ không bao giờ phai, không bao giờ cũ. Rồi khi ta muốn, chỉ cần mở nút chai, và sẽ như được sống lại khoảnh khắc ấy một lần nữa.
Daphne du Maurier, Rebecca
Chương trước là một cuộc khám phá dài về một cấu trúc dữ liệu nền tảng, sâu và lớn trong khoa học máy tính. Nặng về lý thuyết và khái niệm. Có thể đã có đôi chút bàn luận về ký hiệu big-O và thuật toán. Chương này thì ít “trí tuệ” hơn. Không có ý tưởng lớn nào để học. Thay vào đó, chỉ là một vài tác vụ kỹ thuật thẳng thắn. Khi hoàn thành, máy ảo của chúng ta sẽ hỗ trợ biến.
Thực ra, nó sẽ chỉ hỗ trợ biến toàn cục. Biến cục bộ sẽ xuất hiện ở chương sau. Trong jlox, chúng ta gộp cả hai vào một chương vì dùng cùng một kỹ thuật implement cho mọi biến. Ta xây dựng một chuỗi environment, mỗi scope một environment, nối lên tận đỉnh. Đó là một cách đơn giản, gọn gàng để học cách quản lý state.
Nhưng nó cũng chậm. Cấp phát một hash table mới mỗi khi vào một block hoặc gọi một hàm không phải là con đường dẫn đến một VM nhanh. Xét đến việc rất nhiều code liên quan đến việc dùng biến, nếu biến chậm thì mọi thứ đều chậm. Với clox, ta sẽ cải thiện bằng cách dùng chiến lược hiệu quả hơn nhiều cho biến cục bộ, nhưng biến toàn cục thì không dễ tối ưu như vậy.
Một chút nhắc lại về semantics của Lox: Biến toàn cục trong Lox là “late bound”, hay được resolve động. Điều này nghĩa là bạn có thể compile một đoạn code tham chiếu đến biến toàn cục trước khi nó được định nghĩa. Miễn là code đó không execute trước khi định nghĩa xảy ra, thì mọi thứ đều ổn. Trên thực tế, điều này nghĩa là bạn có thể tham chiếu đến các biến được định nghĩa sau trong phần thân của hàm.
fun showVariable() { print global; } var global = "after"; showVariable();
Code như thế này có thể trông lạ, nhưng nó hữu ích khi định nghĩa các hàm đệ quy lẫn nhau. Nó cũng thân thiện hơn với REPL. Bạn có thể viết một hàm nhỏ trong một dòng, rồi định nghĩa biến mà nó dùng ở dòng tiếp theo.
Biến cục bộ hoạt động khác. Vì khai báo biến cục bộ luôn xảy ra trước khi nó được dùng, VM có thể resolve chúng ngay tại compile time, ngay cả trong một compiler một-pass đơn giản. Điều đó sẽ cho phép ta dùng cách biểu diễn thông minh hơn cho biến cục bộ. Nhưng đó là chuyện của chương sau. Giờ hãy chỉ tập trung vào biến toàn cục.
21 . 1Statements
Biến được tạo ra thông qua khai báo biến, nghĩa là giờ cũng là lúc thêm hỗ trợ cho statement vào compiler của chúng ta. Nếu bạn nhớ, Lox chia statement thành hai loại. “Declaration” là những statement gán một tên mới cho một giá trị. Các loại statement khác — control flow, print, v.v. — chỉ được gọi là “statement”. Chúng ta không cho phép khai báo trực tiếp bên trong control flow statement, như thế này:
if (monday) var croissant = "yes"; // Error.
Cho phép điều đó sẽ dẫn đến những câu hỏi khó hiểu về phạm vi của biến. Vì vậy, giống như các ngôn ngữ khác, ta cấm điều đó về mặt cú pháp bằng cách có một grammar rule riêng cho tập con các statement được phép bên trong thân control flow.
statement → exprStmt | forStmt | ifStmt | printStmt | returnStmt | whileStmt | block ;
Sau đó, ta dùng một rule riêng cho cấp cao nhất của script và bên trong block.
declaration → classDecl | funDecl | varDecl | statement ;
Rule declaration chứa các statement khai báo tên, và cũng bao gồm statement để cho phép tất cả các loại statement. Vì block bản thân nó nằm trong statement, bạn có thể đặt khai báo bên trong một control flow construct bằng cách lồng chúng trong một block.
Trong chương này, chúng ta sẽ chỉ đề cập đến một vài statement và một declaration.
statement → exprStmt | printStmt ; declaration → varDecl | statement ;
Cho đến giờ, VM của chúng ta coi một “program” là một expression duy nhất vì đó là tất cả những gì ta có thể parse và compile. Trong một implement Lox đầy đủ, một program là một chuỗi các declaration. Giờ ta đã sẵn sàng hỗ trợ điều đó.
advance();
in compile()
replace 2 lines
while (!match(TOKEN_EOF)) { declaration(); }
endCompiler();
Ta tiếp tục compile các declaration cho đến khi gặp cuối file nguồn. Ta compile một declaration đơn bằng cách này:
add after expression()
static void declaration() { statement(); }
Chúng ta sẽ nói về variable declaration sau trong chương, nên hiện tại, ta chỉ đơn giản chuyển tiếp sang statement().
add after declaration()
static void statement() { if (match(TOKEN_PRINT)) { printStatement(); } }
Block có thể chứa declaration, và control flow statement có thể chứa các statement khác. Điều đó nghĩa là hai hàm này cuối cùng sẽ đệ quy. Ta có thể viết luôn phần forward declaration ngay bây giờ.
static void expression();
add after expression()
static void statement(); static void declaration();
static ParseRule* getRule(TokenType type);
21 . 1 . 1Câu lệnh Print
Trong chương này, chúng ta sẽ hỗ trợ hai loại statement. Hãy bắt đầu với câu lệnh print, vốn tất nhiên bắt đầu bằng token print. Ta phát hiện nó bằng hàm helper sau:
add after consume()
static bool match(TokenType type) { if (!check(type)) return false; advance(); return true; }
Bạn có thể nhận ra nó từ jlox. Nếu token hiện tại có type được chỉ định, ta consume token đó và trả về true. Ngược lại, ta giữ nguyên token và trả về false. Hàm helper này được implement dựa trên một helper khác:
add after consume()
static bool check(TokenType type) { return parser.current.type == type; }
Hàm check() trả về true nếu token hiện tại có type được chỉ định. Có vẻ hơi thừa khi bọc nó trong một hàm, nhưng sau này ta sẽ dùng nó nhiều, và tôi nghĩ những hàm ngắn gọn, đặt tên theo động từ như thế này giúp parser dễ đọc hơn.
Nếu ta match được token print, thì ta compile phần còn lại của statement ở đây:
add after expression()
static void printStatement() { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after value."); emitByte(OP_PRINT); }
Một câu lệnh print sẽ evaluate một expression và in kết quả, nên trước tiên ta parse và compile expression đó. Grammar yêu cầu có dấu chấm phẩy sau đó, nên ta consume nó. Cuối cùng, ta emit một instruction mới để in kết quả.
OP_NEGATE,
in enum OpCode
OP_PRINT,
OP_RETURN,
Khi runtime, ta execute instruction này như sau:
break;
in run()
case OP_PRINT: { printValue(pop()); printf("\n"); break; }
case OP_RETURN: {
Khi interpreter gặp instruction này, nó đã execute xong code cho expression, để lại giá trị kết quả trên đỉnh stack. Giờ ta chỉ cần pop và in nó ra.
Lưu ý rằng ta không push thêm gì sau đó. Đây là một điểm khác biệt quan trọng giữa expression và statement trong VM. Mỗi instruction bytecode đều có một stack effect mô tả cách instruction đó thay đổi stack. Ví dụ, OP_ADD pop hai giá trị và push một, khiến stack giảm đi một phần tử so với trước.
Bạn có thể cộng các stack effect của một chuỗi instruction để ra tổng effect của chúng. Khi cộng stack effect của chuỗi instruction được compile từ bất kỳ expression hoàn chỉnh nào, tổng sẽ là một. Mỗi expression để lại một giá trị kết quả trên stack.
Bytecode cho toàn bộ một statement có tổng stack effect bằng 0. Vì statement không tạo ra giá trị nào, nó cuối cùng sẽ để stack không đổi, dù tất nhiên nó vẫn dùng stack trong quá trình execute. Điều này quan trọng vì khi ta đến phần control flow và vòng lặp, một chương trình có thể execute một chuỗi dài statement. Nếu mỗi statement làm stack tăng hoặc giảm, cuối cùng stack có thể bị tràn hoặc hụt.
Nhân tiện khi đang ở trong vòng lặp interpreter, ta nên xóa một chút code.
case OP_RETURN: {
in run()
replace 2 lines
// Exit interpreter.
return INTERPRET_OK;
Khi VM chỉ compile và evaluate một expression duy nhất, ta có một đoạn code tạm trong OP_RETURN để in giá trị. Giờ khi đã có statement và print, ta không cần nó nữa. Chúng ta đã tiến thêm một bước đến bản implement hoàn chỉnh của clox.
Như thường lệ, một instruction mới cần được hỗ trợ trong disassembler.
return simpleInstruction("OP_NEGATE", offset);
in disassembleInstruction()
case OP_PRINT: return simpleInstruction("OP_PRINT", offset);
case OP_RETURN:
Đó là câu lệnh print của chúng ta. Nếu muốn, bạn có thể thử ngay:
print 1 + 2; print 3 * 4;
Thú vị đấy chứ! OK, có thể chưa đến mức hồi hộp, nhưng giờ ta có thể viết script chứa bao nhiêu statement tùy thích, và đó là một bước tiến.
21 . 1 . 2Expression statements
Chờ đến khi bạn thấy statement tiếp theo. Nếu ta không thấy từ khóa print, thì chắc chắn ta đang nhìn vào một expression statement.
printStatement();
in statement()
} else { expressionStatement();
}
Nó được parse như sau:
add after expression()
static void expressionStatement() { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after expression."); emitByte(OP_POP); }
Một “expression statement” đơn giản là một expression theo sau bởi dấu chấm phẩy. Đây là cách bạn viết một expression trong ngữ cảnh cần một statement. Thường thì điều này để bạn có thể gọi một hàm hoặc evaluate một phép gán nhằm lấy side effect của nó, như thế này:
brunch = "quiche"; eat(brunch);
Về mặt ngữ nghĩa, một expression statement sẽ evaluate expression và bỏ qua kết quả. Compiler encode trực tiếp hành vi đó: nó compile expression, rồi emit một instruction OP_POP.
OP_FALSE,
in enum OpCode
OP_POP,
OP_EQUAL,
Đúng như tên gọi, instruction này pop giá trị trên đỉnh stack và bỏ nó đi.
case OP_FALSE: push(BOOL_VAL(false)); break;
in run()
case OP_POP: pop(); break;
case OP_EQUAL: {
Ta cũng có thể disassemble nó.
return simpleInstruction("OP_FALSE", offset);
in disassembleInstruction()
case OP_POP: return simpleInstruction("OP_POP", offset);
case OP_EQUAL:
Expression statement hiện tại chưa hữu ích lắm vì ta chưa thể tạo ra expression nào có side effect, nhưng chúng sẽ trở nên thiết yếu khi thêm function sau này. Phần lớn statement trong code thực tế của các ngôn ngữ như C là expression statement.
21 . 1 . 3Error synchronization
Khi đang hoàn thiện phần việc ban đầu trong compiler, ta có thể xử lý nốt một đầu mối còn bỏ dở từ vài chương trước. Giống như jlox, clox dùng panic mode error recovery để giảm thiểu số lượng lỗi compile dây chuyền mà nó báo. Compiler sẽ thoát khỏi panic mode khi đến một điểm đồng bộ (synchronization point). Với Lox, ta chọn ranh giới statement làm điểm đó. Giờ khi đã có statement, ta có thể implement việc đồng bộ.
statement();
in declaration()
if (parser.panicMode) synchronize();
}
Nếu gặp lỗi compile khi parse statement trước đó, ta sẽ vào panic mode. Khi điều đó xảy ra, sau statement đó ta bắt đầu đồng bộ.
add after printStatement()
static void synchronize() { parser.panicMode = false; while (parser.current.type != TOKEN_EOF) { if (parser.previous.type == TOKEN_SEMICOLON) return; switch (parser.current.type) { case TOKEN_CLASS: case TOKEN_FUN: case TOKEN_VAR: case TOKEN_FOR: case TOKEN_IF: case TOKEN_WHILE: case TOKEN_PRINT: case TOKEN_RETURN: return; default: ; // Do nothing. } advance(); } }
Ta bỏ qua token một cách “vô tội vạ” cho đến khi gặp thứ trông giống ranh giới statement. Ta nhận diện ranh giới này bằng cách tìm token đứng trước có thể kết thúc một statement, như dấu chấm phẩy. Hoặc ta tìm token tiếp theo bắt đầu một statement, thường là một trong các từ khóa control flow hoặc declaration.
21 . 2Variable Declarations
Chỉ in thôi thì chẳng giúp ngôn ngữ của bạn giành giải gì ở hội chợ ngôn ngữ lập trình, nên hãy chuyển sang thứ tham vọng hơn một chút: biến. Có ba thao tác ta cần hỗ trợ:
- Khai báo một biến mới bằng câu lệnh
var. - Truy cập giá trị của một biến bằng identifier expression.
- Lưu một giá trị mới vào biến hiện có bằng assignment expression.
Ta chưa thể làm hai thao tác cuối cho đến khi có biến, nên ta bắt đầu với khai báo.
static void declaration() {
in declaration()
replace 1 line
if (match(TOKEN_VAR)) { varDeclaration(); } else { statement(); }
if (parser.panicMode) synchronize();
Hàm parse placeholder mà ta phác thảo cho rule grammar declaration giờ đã có phần xử lý thực sự. Nếu match được token var, ta nhảy đến đây:
add after expression()
static void varDeclaration() { uint8_t global = parseVariable("Expect variable name."); if (match(TOKEN_EQUAL)) { expression(); } else { emitByte(OP_NIL); } consume(TOKEN_SEMICOLON, "Expect ';' after variable declaration."); defineVariable(global); }
Từ khóa này theo sau bởi tên biến. Việc này được compile bởi parseVariable(), mà ta sẽ nói tới ngay sau đây. Sau đó, ta tìm dấu = theo sau bởi một initializer expression. Nếu người dùng không khởi tạo biến, compiler sẽ ngầm định khởi tạo nó thành nil bằng cách emit instruction OP_NIL. Dù theo cách nào, ta cũng mong statement kết thúc bằng dấu chấm phẩy.
Ở đây có hai hàm mới để làm việc với biến và identifier. Đây là hàm đầu tiên:
static void parsePrecedence(Precedence precedence);
add after parsePrecedence()
static uint8_t parseVariable(const char* errorMessage) { consume(TOKEN_IDENTIFIER, errorMessage); return identifierConstant(&parser.previous); }
Hàm này yêu cầu token tiếp theo phải là một identifier, nó sẽ consume token đó và chuyển sang đây:
static void parsePrecedence(Precedence precedence);
add after parsePrecedence()
static uint8_t identifierConstant(Token* name) { return makeConstant(OBJ_VAL(copyString(name->start, name->length))); }
Hàm này nhận token được truyền vào và thêm lexeme của nó vào constant table của chunk dưới dạng string. Sau đó, nó trả về chỉ số của constant đó trong constant table.
Biến toàn cục được tra cứu theo tên ở runtime. Điều đó nghĩa là VM — vòng lặp bytecode interpreter — cần truy cập được tên này. Một string đầy đủ thì quá lớn để nhét trực tiếp vào luồng bytecode như một toán hạng. Thay vào đó, ta lưu string vào constant table và instruction sẽ tham chiếu tới tên bằng chỉ số của nó trong bảng.
Hàm này trả về chỉ số đó cho varDeclaration(), hàm này sau đó chuyển nó tới đây:
add after parseVariable()
static void defineVariable(uint8_t global) { emitBytes(OP_DEFINE_GLOBAL, global); }
Hàm này xuất ra instruction bytecode định nghĩa biến mới và lưu giá trị khởi tạo của nó. Chỉ số của tên biến trong constant table chính là toán hạng của instruction. Như thường lệ trong một stack-based VM, ta emit instruction này sau cùng. Ở runtime, ta execute code cho phần khởi tạo biến trước, để lại giá trị trên stack. Sau đó, instruction này lấy giá trị đó và lưu lại để dùng sau.
Bên phía runtime, ta bắt đầu với instruction mới này:
OP_POP,
in enum OpCode
OP_DEFINE_GLOBAL,
OP_EQUAL,
Nhờ có hash table tiện dụng, phần implement không quá khó.
case OP_POP: pop(); break;
in run()
case OP_DEFINE_GLOBAL: { ObjString* name = READ_STRING(); tableSet(&vm.globals, name, peek(0)); pop(); break; }
case OP_EQUAL: {
Ta lấy tên biến từ constant table. Sau đó, ta lấy giá trị từ đỉnh stack và lưu nó vào hash table với tên đó làm key.
Đoạn code này không kiểm tra xem key đã tồn tại trong bảng chưa. Lox khá “thoáng” với biến toàn cục và cho phép bạn định nghĩa lại chúng mà không báo lỗi. Điều này hữu ích trong phiên REPL, nên VM hỗ trợ bằng cách đơn giản ghi đè giá trị nếu key đã tồn tại trong hash table.
Có thêm một macro helper nhỏ:
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
in run()
#define READ_STRING() AS_STRING(READ_CONSTANT())
#define BINARY_OP(valueType, op) \
Nó đọc một toán hạng một byte từ bytecode chunk. Nó coi đó là chỉ số trong constant table của chunk và trả về string ở chỉ số đó. Nó không kiểm tra giá trị có phải là string hay không — chỉ đơn giản cast nó. Điều này an toàn vì compiler không bao giờ emit instruction tham chiếu tới một constant không phải string.
Vì muốn giữ “vệ sinh” về mặt từ vựng, ta cũng undefine macro này ở cuối hàm interpret.
#undef READ_CONSTANT
in run()
#undef READ_STRING
#undef BINARY_OP
Tôi cứ nói “hash table” nhưng thực ra ta chưa có cái nào. Ta cần một nơi để lưu các biến toàn cục này. Vì muốn chúng tồn tại suốt thời gian clox chạy, ta lưu chúng ngay trong VM.
Value* stackTop;
in struct VM
Table globals;
Table strings;
Giống như với string table, ta cần khởi tạo hash table về trạng thái hợp lệ khi VM khởi động.
vm.objects = NULL;
in initVM()
initTable(&vm.globals);
initTable(&vm.strings);
Và ta giải phóng nó khi thoát.
void freeVM() {
in freeVM()
freeTable(&vm.globals);
freeTable(&vm.strings);
Như thường lệ, ta cũng muốn có thể disassemble instruction mới này.
return simpleInstruction("OP_POP", offset);
in disassembleInstruction()
case OP_DEFINE_GLOBAL: return constantInstruction("OP_DEFINE_GLOBAL", chunk, offset);
case OP_EQUAL:
Và với điều đó, ta đã có thể định nghĩa biến toàn cục. Tất nhiên, người dùng chưa nhận ra là họ đã làm vậy, vì họ chưa thể dùng chúng. Vậy nên, hãy sửa điều đó ở bước tiếp theo.
21 . 3Đọc giá trị biến (Reading Variables)
Giống như trong mọi ngôn ngữ lập trình, ta truy cập giá trị của một biến thông qua tên của nó. Ta kết nối các identifier token với expression parser tại đây:
[TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
replace 1 line
[TOKEN_IDENTIFIER] = {variable, NULL, PREC_NONE},
[TOKEN_STRING] = {string, NULL, PREC_NONE},
Điều này gọi tới hàm parser mới:
add after string()
static void variable() { namedVariable(parser.previous); }
Giống như với khai báo biến, ở đây cũng có một vài hàm helper nhỏ trông có vẻ vô nghĩa lúc này nhưng sẽ hữu ích hơn ở các chương sau. Tôi hứa đấy.
add after string()
static void namedVariable(Token name) { uint8_t arg = identifierConstant(&name); emitBytes(OP_GET_GLOBAL, arg); }
Hàm này gọi lại identifierConstant() như trước để lấy identifier token được truyền vào và thêm lexeme của nó vào constant table của chunk dưới dạng string. Việc còn lại là emit một instruction để load biến toàn cục có tên đó. Đây là instruction đó:
OP_POP,
in enum OpCode
OP_GET_GLOBAL,
OP_DEFINE_GLOBAL,
Bên phía interpreter, phần implement phản chiếu OP_DEFINE_GLOBAL.
case OP_POP: pop(); break;
in run()
case OP_GET_GLOBAL: { ObjString* name = READ_STRING(); Value value; if (!tableGet(&vm.globals, name, &value)) { runtimeError("Undefined variable '%s'.", name->chars); return INTERPRET_RUNTIME_ERROR; } push(value); break; }
case OP_DEFINE_GLOBAL: {
Ta lấy chỉ số trong constant table từ toán hạng của instruction và lấy tên biến. Sau đó, ta dùng tên này làm key để tra giá trị của biến trong globals hash table.
Nếu key không tồn tại trong hash table, nghĩa là biến toàn cục đó chưa bao giờ được định nghĩa. Đây là lỗi runtime trong Lox, nên ta báo lỗi và thoát khỏi vòng lặp interpreter nếu điều đó xảy ra. Ngược lại, ta lấy giá trị và push nó lên stack.
return simpleInstruction("OP_POP", offset);
in disassembleInstruction()
case OP_GET_GLOBAL: return constantInstruction("OP_GET_GLOBAL", chunk, offset);
case OP_DEFINE_GLOBAL:
Thêm một chút disassemble nữa là xong. Interpreter của chúng ta giờ có thể chạy code như thế này:
var beverage = "cafe au lait"; var breakfast = "beignets with " + beverage; print breakfast;
Giờ chỉ còn một thao tác nữa.
21 . 4Gán giá trị (Assignment)
Xuyên suốt cuốn sách này, tôi đã cố gắng giữ cho bạn đi trên một con đường khá an toàn và dễ dàng. Tôi không né tránh các vấn đề khó, nhưng tôi cố không làm cho giải pháp phức tạp hơn mức cần thiết. Tiếc là, một số lựa chọn thiết kế khác trong bytecode compiler của chúng ta khiến việc implement assignment trở nên phiền phức.
Bytecode VM của chúng ta dùng compiler một-pass. Nó parse và sinh bytecode ngay lập tức mà không qua bất kỳ AST trung gian nào. Ngay khi nhận ra một phần cú pháp, nó sẽ emit code cho phần đó. Assignment thì không tự nhiên phù hợp với cách này. Xem ví dụ:
menu.brunch(sunday).beverage = "mimosa";
Trong đoạn code này, parser không nhận ra menu.brunch(sunday).beverage là mục tiêu của một phép gán (assignment target) chứ không phải một expression thông thường cho đến khi gặp dấu =, tức là nhiều token sau menu. Lúc đó, compiler đã emit bytecode cho toàn bộ phần đó rồi.
Tuy nhiên, vấn đề không nghiêm trọng như có vẻ. Hãy xem parser nhìn ví dụ này thế nào:

Mặc dù phần .beverage không được compile như một get expression, mọi thứ bên trái dấu . vẫn là một expression, với semantics thông thường. Phần menu.brunch(sunday) có thể compile và execute như bình thường.
May mắn cho chúng ta, sự khác biệt về semantics ở phía bên trái của một assignment chỉ xuất hiện ở phần cuối cùng của chuỗi token, ngay trước dấu =. Dù receiver của một setter có thể là một expression dài tùy ý, phần có hành vi khác với get expression chỉ là identifier ở cuối, ngay trước dấu =. Ta không cần lookahead nhiều để nhận ra beverage nên được compile như một set expression thay vì getter.
Với biến thì còn dễ hơn, vì chúng chỉ là một identifier đơn lẻ trước dấu =. Ý tưởng là ngay trước khi compile một expression có thể được dùng làm assignment target, ta sẽ kiểm tra xem token tiếp theo có phải là = không. Nếu có, ta compile nó như một assignment hoặc setter thay vì variable access hoặc getter.
Hiện tại ta chưa có setter để lo, nên tất cả những gì cần xử lý chỉ là biến.
uint8_t arg = identifierConstant(&name);
in namedVariable()
replace 1 line
if (match(TOKEN_EQUAL)) { expression(); emitBytes(OP_SET_GLOBAL, arg); } else { emitBytes(OP_GET_GLOBAL, arg); }
}
Trong hàm parse cho identifier expression, ta tìm dấu bằng sau identifier. Nếu tìm thấy, thay vì emit code cho variable access, ta compile giá trị được gán và sau đó emit một assignment instruction.
Đây là instruction cuối cùng cần thêm trong chương này.
OP_DEFINE_GLOBAL,
in enum OpCode
OP_SET_GLOBAL,
OP_EQUAL,
Như bạn mong đợi, hành vi runtime của nó tương tự như khi định nghĩa biến mới.
}
in run()
case OP_SET_GLOBAL: { ObjString* name = READ_STRING(); if (tableSet(&vm.globals, name, peek(0))) { tableDelete(&vm.globals, name); runtimeError("Undefined variable '%s'.", name->chars); return INTERPRET_RUNTIME_ERROR; } break; }
case OP_EQUAL: {
Điểm khác biệt chính là điều gì xảy ra khi key chưa tồn tại trong globals hash table. Nếu biến chưa được định nghĩa, việc gán giá trị cho nó là lỗi runtime. Lox không cho phép khai báo biến ngầm định.
Điểm khác biệt còn lại là việc gán giá trị cho một biến không pop giá trị đó khỏi stack. Hãy nhớ rằng, assignment là một expression, nên nó cần để lại giá trị đó trên stack trong trường hợp phép gán này được lồng bên trong một expression lớn hơn.
Thêm một chút phần disassembly:
return constantInstruction("OP_DEFINE_GLOBAL", chunk,
offset);
in disassembleInstruction()
case OP_SET_GLOBAL: return constantInstruction("OP_SET_GLOBAL", chunk, offset);
case OP_EQUAL:
Vậy là xong rồi, đúng không? Ừm… chưa hẳn. Chúng ta đã mắc một lỗi! Hãy xem thử:
a * b = c + d;
Theo grammar của Lox, = có độ ưu tiên thấp nhất, nên đoạn này sẽ được parse đại khái như:
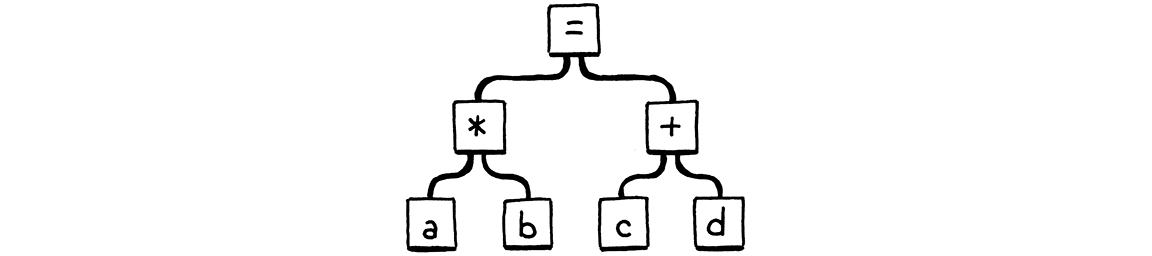
Rõ ràng, a * b không phải là một assignment target hợp lệ, nên đây phải là lỗi cú pháp. Nhưng parser của chúng ta lại làm như sau:
- Đầu tiên,
parsePrecedence()parseabằng prefix parservariable(). - Sau đó, nó bước vào vòng lặp parse infix.
- Nó gặp
*và gọibinary(). - Hàm này đệ quy gọi
parsePrecedence()để parse toán hạng bên phải. - Lần này,
variable()lại được gọi để parseb. - Bên trong lời gọi
variable()này, nó tìm dấu=ở phía sau. Nó thấy một dấu và parse phần còn lại của dòng như một assignment.
Nói cách khác, parser nhìn đoạn code trên như:
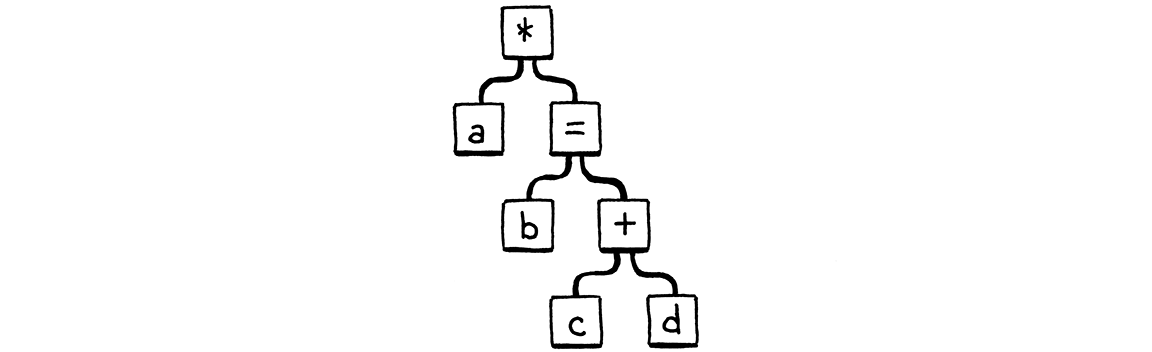
Chúng ta đã làm hỏng phần xử lý precedence vì variable() không xét đến độ ưu tiên của expression bao quanh biến đó. Nếu biến này tình cờ nằm ở phía bên phải của một toán tử infix, hoặc là toán hạng của một toán tử unary, thì expression bao quanh đó có precedence quá cao để cho phép dấu =.
Để sửa, variable() chỉ nên tìm và consume dấu = nếu nó đang ở trong ngữ cảnh của một expression có precedence thấp. Phần code biết precedence hiện tại, hợp lý thay, là parsePrecedence(). Hàm variable() không cần biết chính xác cấp độ precedence, nó chỉ cần biết precedence đủ thấp để cho phép assignment, nên ta truyền thông tin đó vào dưới dạng một giá trị Boolean.
error("Expect expression.");
return;
}
in parsePrecedence()
replace 1 line
bool canAssign = precedence <= PREC_ASSIGNMENT; prefixRule(canAssign);
while (precedence <= getRule(parser.current.type)->precedence) {
Vì assignment là expression có precedence thấp nhất, thời điểm duy nhất ta cho phép assignment là khi đang parse một assignment expression hoặc một top-level expression như trong expression statement. Cờ này được truyền tới hàm parser ở đây:
function variable()
replace 3 lines
static void variable(bool canAssign) { namedVariable(parser.previous, canAssign); }
Hàm này truyền nó qua một tham số mới:
function namedVariable()
replace 1 line
static void namedVariable(Token name, bool canAssign) {
uint8_t arg = identifierConstant(&name);
Và cuối cùng sử dụng nó ở đây:
uint8_t arg = identifierConstant(&name);
in namedVariable()
replace 1 line
if (canAssign && match(TOKEN_EQUAL)) {
expression();
Khá nhiều “đường ống” chỉ để đưa đúng một bit dữ liệu tới đúng chỗ trong compiler, nhưng cuối cùng nó cũng tới. Nếu biến nằm bên trong một expression có precedence cao hơn, canAssign sẽ là false và đoạn code này sẽ bỏ qua dấu = ngay cả khi nó có ở đó. Sau đó namedVariable() trả về, và luồng execute cuối cùng quay lại parsePrecedence().
Rồi sao nữa? Compiler sẽ làm gì với ví dụ hỏng trước đó? Lúc này, variable() sẽ không consume dấu =, nên nó sẽ là token hiện tại. Compiler quay lại parsePrecedence() từ prefix parser variable() và sau đó cố gắng bước vào vòng lặp parse infix. Không có hàm parse nào gắn với =, nên nó bỏ qua vòng lặp đó.
Rồi parsePrecedence() lặng lẽ trả về cho caller. Điều này cũng không đúng. Nếu dấu = không được consume như một phần của expression, sẽ không có gì khác consume nó. Đây là một lỗi và ta nên báo lỗi.
infixRule(); }
in parsePrecedence()
if (canAssign && match(TOKEN_EQUAL)) { error("Invalid assignment target."); }
}
Với thay đổi này, chương trình sai trước đó sẽ nhận lỗi compile đúng như mong đợi. OK, giờ thì xong chưa? Vẫn chưa hẳn. Bạn thấy đấy, ta đang truyền một tham số vào một trong các hàm parse. Nhưng các hàm này được lưu trong một bảng con trỏ hàm, nên tất cả các hàm parse đều phải có cùng kiểu. Dù hầu hết các hàm parse không hỗ trợ việc được dùng làm assignment target — setter là trường hợp duy nhất khác — nhưng C compiler “thân thiện” của chúng ta yêu cầu tất cả chúng đều phải nhận tham số này.
Vậy là chúng ta sẽ kết thúc chương này với một chút “việc tay chân”. Đầu tiên, hãy truyền flag này vào các hàm parse infix.
ParseFn infixRule = getRule(parser.previous.type)->infix;
in parsePrecedence()
replace 1 line
infixRule(canAssign);
}
Rồi sau này ta sẽ cần nó cho setter. Tiếp theo, ta sửa typedef cho kiểu hàm.
} Precedence;
add after enum Precedence
replace 1 line
typedef void (*ParseFn)(bool canAssign);
typedef struct {
Và thêm một loạt code khá nhàm chán để chấp nhận tham số này trong tất cả các hàm parse hiện có. Ở đây:
function binary()
replace 1 line
static void binary(bool canAssign) {
TokenType operatorType = parser.previous.type;
Và ở đây:
function literal()
replace 1 line
static void literal(bool canAssign) {
switch (parser.previous.type) {
Và ở đây:
function grouping()
replace 1 line
static void grouping(bool canAssign) {
expression();
Và ở đây:
function number()
replace 1 line
static void number(bool canAssign) {
double value = strtod(parser.previous.start, NULL);
Và cả ở đây nữa:
function string()
replace 1 line
static void string(bool canAssign) {
emitConstant(OBJ_VAL(copyString(parser.previous.start + 1,
Và cuối cùng:
function unary()
replace 1 line
static void unary(bool canAssign) {
TokenType operatorType = parser.previous.type;
Phù! Giờ ta lại có một chương trình C có thể compile. Chạy nó lên và bạn có thể execute đoạn này:
var breakfast = "beignets"; var beverage = "cafe au lait"; breakfast = "beignets with " + beverage; print breakfast;
Nó bắt đầu trông giống code thật của một ngôn ngữ lập trình thực thụ rồi đấy!
21 . 5Thử thách
-
Compiler thêm tên biến toàn cục vào constant table dưới dạng string mỗi khi gặp một identifier. Nó tạo một constant mới mỗi lần, ngay cả khi tên biến đó đã tồn tại ở một slot trước đó trong constant table. Điều này lãng phí trong trường hợp cùng một biến được tham chiếu nhiều lần bởi cùng một hàm. Điều đó cũng làm tăng khả năng lấp đầy constant table và hết slot, vì ta chỉ cho phép tối đa 256 constant trong một chunk.
Hãy tối ưu điều này. Việc tối ưu của bạn ảnh hưởng thế nào đến hiệu năng của compiler so với runtime? Đây có phải là sự đánh đổi hợp lý không?
-
Việc tra cứu biến toàn cục theo tên trong hash table mỗi lần sử dụng khá chậm, ngay cả với một hash table tốt. Bạn có thể nghĩ ra cách nào hiệu quả hơn để lưu trữ và truy cập biến toàn cục mà không thay đổi semantics không?
-
Khi chạy trong REPL, người dùng có thể viết một hàm tham chiếu tới một biến toàn cục chưa biết. Sau đó, ở dòng tiếp theo, họ khai báo biến đó. Lox nên xử lý trường hợp này một cách “êm” bằng cách không báo lỗi compile “unknown variable” khi hàm vừa được định nghĩa.
Nhưng khi người dùng chạy một script Lox, compiler có quyền truy cập toàn bộ nội dung chương trình trước khi bất kỳ code nào được chạy. Xem chương trình này:
fun useVar() { print oops; } var ooops = "too many o's!";
Ở đây, ta có thể biết một cách tĩnh rằng
oopssẽ không được định nghĩa vì không có khai báo nào của biến toàn cục đó trong chương trình. Lưu ý rằnguseVar()cũng không bao giờ được gọi, nên dù biến không được định nghĩa, cũng sẽ không có lỗi runtime vì nó cũng không bao giờ được dùng.Ta có thể báo những lỗi như thế này ngay tại compile time, ít nhất là khi chạy từ script. Bạn có nghĩ ta nên làm vậy không? Hãy giải thích lý do. Các ngôn ngữ scripting khác mà bạn biết xử lý thế nào?