20 Paging: Smaller Tables
(Paging: Bảng trang nhỏ hơn)
Chúng ta sẽ giải quyết vấn đề thứ hai mà paging (phân trang) gây ra: page table (bảng trang) quá lớn và tiêu tốn quá nhiều bộ nhớ. Hãy bắt đầu với linear page table (bảng trang tuyến tính). Như bạn có thể nhớ1, linear page table có thể rất lớn. Giả sử một address space (không gian địa chỉ) 32-bit (2^32 byte), với page 4KB (2^12 byte) và mỗi page-table entry (PTE — mục bảng trang) có kích thước 4 byte. Một address space như vậy sẽ có khoảng một triệu virtual pages (trang ảo) (2^32 / 2^12); nhân với kích thước mỗi PTE, ta thấy page table có kích thước 4MB. Cũng cần nhớ: thông thường, mỗi process (tiến trình) trong hệ thống sẽ có một page table riêng! Với 100 process đang hoạt động (không hiếm trong hệ thống hiện đại), chúng ta sẽ phải cấp phát hàng trăm MB bộ nhớ chỉ để lưu page table! Do đó, chúng ta cần tìm các kỹ thuật để giảm gánh nặng này. Có khá nhiều kỹ thuật, vậy hãy bắt đầu. Nhưng trước tiên, là một điểm mấu chốt:
CRUX: HOW TO MAKE PAGE TABLES SMALLER?
(Làm thế nào để làm nhỏ page table?)
Các page table dạng mảng đơn giản (thường gọi là linear page table) quá lớn, chiếm quá nhiều bộ nhớ trong các hệ thống thông thường. Làm thế nào để làm nhỏ page table? Ý tưởng chính là gì? Những sự kém hiệu quả nào sẽ phát sinh từ các cấu trúc dữ liệu mới này?
Hoặc có thể bạn không nhớ; cơ chế paging này đang trở nên khá phức tạp, đúng không? Dù sao, hãy luôn đảm bảo rằng bạn hiểu rõ vấn đề mình đang giải quyết trước khi chuyển sang phần giải pháp; thực tế, nếu bạn hiểu rõ vấn đề, bạn thường có thể tự suy ra giải pháp. Ở đây, vấn đề đã rõ: linear page table đơn giản (dạng mảng) là quá lớn.
20.1 Simple Solution: Bigger Pages
(Giải pháp đơn giản: Page lớn hơn)
Chúng ta có thể giảm kích thước page table theo một cách đơn giản: sử dụng page lớn hơn. Lấy lại ví dụ address space 32-bit, nhưng lần này giả sử page có kích thước 16KB. Khi đó, chúng ta sẽ có VPN (virtual page number) 18-bit và offset 14-bit. Giữ nguyên kích thước mỗi PTE là 4 byte, ta sẽ có 2^18 entry trong linear page table, tức tổng kích thước là 1MB cho mỗi page table — giảm 4 lần so với ban đầu (không ngạc nhiên, mức giảm này phản ánh đúng mức tăng gấp 4 của kích thước page).
ASIDE: MULTIPLE PAGE SIZES
(Nhiều kích thước page)
Nhiều kiến trúc (ví dụ: MIPS, SPARC, x86-64) hiện hỗ trợ nhiều kích thước page. Thông thường, kích thước page nhỏ (4KB hoặc 8KB) được sử dụng. Tuy nhiên, nếu một ứng dụng “thông minh” yêu cầu, một page lớn duy nhất (ví dụ: 4MB) có thể được dùng cho một phần cụ thể của address space, cho phép ứng dụng đặt một data structure (cấu trúc dữ liệu) lớn và thường xuyên được sử dụng vào đó, đồng thời chỉ tiêu tốn một entry trong TLB. Kiểu sử dụng page lớn này phổ biến trong database management systems (hệ quản trị cơ sở dữ liệu) và các ứng dụng thương mại cao cấp khác. Lý do chính của việc hỗ trợ nhiều kích thước page không phải để tiết kiệm không gian page table, mà là để giảm áp lực lên TLB, cho phép chương trình truy cập nhiều hơn vào address space của nó mà không gặp quá nhiều TLB misses. Tuy nhiên, như các nghiên cứu đã chỉ ra [N+02], việc sử dụng nhiều kích thước page khiến virtual memory manager (bộ quản lý bộ nhớ ảo) của OS trở nên phức tạp hơn đáng kể, và do đó page lớn đôi khi dễ sử dụng nhất khi OS cung cấp một giao diện mới để ứng dụng yêu cầu trực tiếp.
Vấn đề lớn của cách tiếp cận này là page lớn dẫn đến lãng phí bên trong mỗi page, gọi là internal fragmentation (phân mảnh bên trong — vì phần lãng phí nằm bên trong đơn vị cấp phát). Ứng dụng có thể cấp phát page nhưng chỉ dùng một phần nhỏ, khiến bộ nhớ nhanh chóng bị lấp đầy bởi các page quá lớn này. Do đó, hầu hết hệ thống sử dụng kích thước page tương đối nhỏ trong trường hợp phổ biến: 4KB (như x86) hoặc 8KB (như SPARCv9). Vậy là vấn đề của chúng ta sẽ không thể giải quyết đơn giản như vậy.
20.2 Hybrid Approach: Paging and Segments
(Cách tiếp cận lai: Paging và Segmentation)
Khi bạn có hai cách tiếp cận hợp lý nhưng khác nhau, bạn nên xem xét việc kết hợp chúng để tận dụng ưu điểm của cả hai. Chúng ta gọi sự kết hợp này là hybrid (lai). Ví dụ, tại sao chỉ ăn sô-cô-la hoặc chỉ bơ đậu phộng khi bạn có thể kết hợp chúng thành một món tuyệt vời như Reese’s Peanut Butter Cup [M28]?
Nhiều năm trước, những người tạo ra hệ thống Multics (đặc biệt là Jack Dennis) đã nảy ra ý tưởng này khi xây dựng hệ thống virtual memory của Multics [M07]. Cụ thể, Dennis đã nghĩ đến việc kết hợp paging và segmentation để giảm chi phí bộ nhớ của page table. Chúng ta có thể thấy tại sao điều này hiệu quả bằng cách xem xét kỹ hơn một linear page table điển hình. Giả sử chúng ta có một address space mà phần heap và stack được sử dụng rất nhỏ. Trong ví dụ này, ta dùng một address space 16KB với page 1KB (Figure 20.1); page table cho address space này được thể hiện trong Figure 20.2.
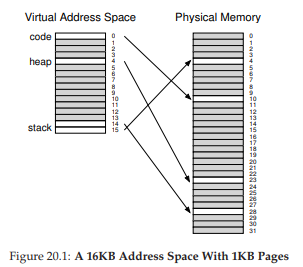
Figure 20.1: A 16KB Address Space With 1KB Pages
(Không gian địa chỉ 16KB với page 1KB)

Figure 20.2: A Page Table For 16KB Address Space
(Page table cho không gian địa chỉ 16KB)
Ví dụ này giả định:
- Page code duy nhất (VPN 0) ánh xạ tới physical page 10
- Page heap duy nhất (VPN 4) ánh xạ tới physical page 23
- Hai page stack ở cuối address space (VPN 14 và 15) ánh xạ tới physical page 28 và 4
Như bạn thấy, phần lớn page table không được sử dụng, đầy các entry invalid. Thật lãng phí! Và đây mới chỉ là address space 16KB. Hãy tưởng tượng page table của address space 32-bit và lượng không gian lãng phí tiềm tàng! Thực ra, đừng tưởng tượng — nó quá khủng khiếp.
Vì vậy, cách tiếp cận hybrid của chúng ta: thay vì có một page table duy nhất cho toàn bộ address space của process, tại sao không có một page table cho mỗi logical segment (đoạn logic)? Trong ví dụ này, ta có thể có ba page table: một cho code, một cho heap, và một cho stack.
Hãy nhớ rằng với segmentation, chúng ta có base register (thanh ghi cơ sở) cho biết mỗi segment nằm ở đâu trong physical memory, và bound/limit register (thanh ghi giới hạn) cho biết kích thước segment. Trong hybrid này, chúng ta vẫn giữ các cấu trúc đó trong MMU; nhưng ở đây, base không trỏ tới segment, mà chứa địa chỉ vật lý của page table của segment đó. Bound register dùng để chỉ điểm kết thúc của page table (tức là số lượng page hợp lệ).
Ví dụ: Giả sử address space 32-bit với page 4KB, chia thành bốn segment. Ta chỉ dùng ba segment: code, heap, stack.
Để xác định một địa chỉ thuộc segment nào, ta dùng 2 bit cao nhất của address space. Giả sử:
00là segment không dùng01cho code10cho heap11cho stack
Khi đó, virtual address sẽ như sau:
31 30 29 ... 12 11 ... 0
Seg VPN Offset
Trong phần cứng, giả sử rằng tồn tại ba cặp base/bounds (địa chỉ cơ sở/giới hạn), mỗi cặp dành riêng cho code, heap và stack. Khi một process (tiến trình) đang chạy, thanh ghi base của mỗi segment (đoạn) sẽ chứa địa chỉ vật lý của một linear page table (bảng trang tuyến tính) dành cho segment đó; do đó, mỗi process trong hệ thống hiện có ba page table liên kết với nó. Khi xảy ra context switch (chuyển ngữ cảnh), các thanh ghi này phải được thay đổi để phản ánh vị trí của các page table thuộc process mới được chuyển sang chạy.
Khi xảy ra TLB miss (trượt TLB – tình huống khi địa chỉ cần tìm không có trong Translation Lookaside Buffer), giả sử đây là hardware-managed TLB (TLB được phần cứng quản lý, tức phần cứng chịu trách nhiệm xử lý TLB miss), phần cứng sẽ sử dụng các bit segment (SN) để xác định cặp base/bounds nào cần dùng. Sau đó, phần cứng lấy địa chỉ vật lý trong thanh ghi base tương ứng và kết hợp nó với VPN (Virtual Page Number – số trang ảo) như sau để tạo ra địa chỉ của page table entry (PTE – mục nhập bảng trang):
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT
VPN = (VirtualAddress & VPN_MASK) >> VPN_SHIFT
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE))
Chuỗi thao tác này có thể trông quen thuộc; nó gần như giống hệt với những gì chúng ta đã thấy trước đây khi làm việc với linear page table. Điểm khác biệt duy nhất, tất nhiên, là việc sử dụng một trong ba thanh ghi base của segment thay vì chỉ một thanh ghi base của page table duy nhất.
TIP: USE HYBRIDS
Khi bạn có hai ý tưởng tốt nhưng dường như đối lập nhau, bạn nên xem xét khả năng kết hợp chúng thành một hybrid (lai ghép) để tận dụng được ưu điểm của cả hai. Ví dụ, các giống ngô lai được biết là khỏe mạnh và bền bỉ hơn bất kỳ giống ngô tự nhiên nào. Tất nhiên, không phải mọi hybrid đều là ý tưởng hay; hãy xem loài Zeedonk (hay Zonkey), là kết quả lai giữa Zebra (ngựa vằn) và Donkey (lừa). Nếu bạn không tin rằng sinh vật này tồn tại, hãy tra cứu và chuẩn bị để ngạc nhiên.
Điểm khác biệt then chốt trong mô hình hybrid (lai) của chúng ta là sự tồn tại của một bounds register (thanh ghi giới hạn) cho mỗi segment (đoạn). Mỗi bounds register lưu giá trị của page (trang) hợp lệ lớn nhất trong segment đó. Ví dụ, nếu code segment (đoạn code) đang sử dụng ba page đầu tiên (0, 1 và 2), thì page table (bảng trang) của code segment sẽ chỉ có ba entry được cấp phát và bounds register sẽ được đặt là 3; mọi truy cập bộ nhớ vượt quá cuối segment sẽ tạo ra một exception (ngoại lệ) và nhiều khả năng dẫn đến việc chấm dứt process (tiến trình). Theo cách này, mô hình hybrid của chúng ta tiết kiệm đáng kể bộ nhớ so với linear page table (bảng trang tuyến tính); các page chưa cấp phát giữa stack và heap sẽ không còn chiếm chỗ trong page table (chỉ để đánh dấu là không hợp lệ).
Tuy nhiên, như bạn có thể nhận thấy, cách tiếp cận này không phải không có vấn đề. Thứ nhất, nó vẫn yêu cầu chúng ta sử dụng segmentation; như đã thảo luận trước đây, segmentation không linh hoạt như mong muốn, vì nó giả định một mô hình sử dụng address space nhất định; nếu chúng ta có một heap lớn nhưng sử dụng thưa thớt, chẳng hạn, ta vẫn có thể gặp nhiều lãng phí trong page table. Thứ hai, mô hình hybrid này khiến external fragmentation (phân mảnh bên ngoài) xuất hiện trở lại. Trong khi phần lớn bộ nhớ được quản lý theo đơn vị kích thước page, thì các page table giờ đây có thể có kích thước tùy ý (theo bội số của PTE). Do đó, việc tìm không gian trống cho chúng trong bộ nhớ trở nên phức tạp hơn. Vì những lý do này, các nhà thiết kế hệ thống tiếp tục tìm kiếm những cách tốt hơn để triển khai các page table nhỏ hơn.
20.3 Multi-level Page Tables
(Bảng trang nhiều cấp)
Một cách tiếp cận khác không dựa vào segmentation nhưng giải quyết cùng vấn đề: làm thế nào để loại bỏ tất cả các vùng invalid (không hợp lệ) trong page table thay vì giữ chúng trong bộ nhớ? Chúng ta gọi cách tiếp cận này là multi-level page table (bảng trang nhiều cấp), vì nó biến linear page table thành một cấu trúc giống như cây. Cách tiếp cận này hiệu quả đến mức nhiều hệ thống hiện đại áp dụng nó (ví dụ: x86 [BOH10]). Sau đây, chúng ta sẽ mô tả chi tiết.
Ý tưởng cơ bản của multi-level page table rất đơn giản. Đầu tiên, chia nhỏ page table thành các đơn vị kích thước bằng một page. Sau đó, nếu toàn bộ một page của các page-table entries (PTE) là invalid, thì không cấp phát page đó trong page table.
Để theo dõi xem một page của page table có hợp lệ hay không (và nếu hợp lệ thì nằm ở đâu trong bộ nhớ), ta sử dụng một cấu trúc mới gọi là page directory (thư mục trang). Page directory có thể cho biết vị trí của một page trong page table, hoặc cho biết toàn bộ page đó không chứa page hợp lệ nào.
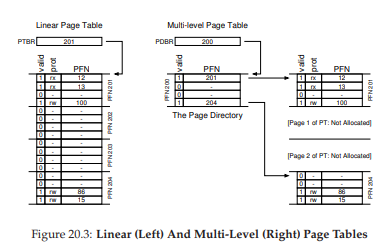 Figure 20.3: Linear (Left) And Multi-Level (Right) Page Tables
Figure 20.3: Linear (Left) And Multi-Level (Right) Page Tables
(Bảng trang tuyến tính — trái, và bảng trang nhiều cấp — phải)
Figure 20.3 minh họa ví dụ:
- Bên trái là linear page table cổ điển; mặc dù phần lớn các vùng ở giữa address space là invalid, ta vẫn phải cấp phát không gian page table cho các vùng này (tức là hai page ở giữa của page table).
- Bên phải là multi-level page table; page directory chỉ đánh dấu hai page của page table là hợp lệ (đầu tiên và cuối cùng), do đó chỉ hai page này tồn tại trong bộ nhớ.
Có thể hình dung multi-level table như một cách “làm biến mất” các phần không cần thiết của linear page table (giải phóng các frame cho mục đích khác), đồng thời theo dõi các page đã được cấp phát bằng page directory.
Trong một bảng hai cấp đơn giản, page directory chứa một entry cho mỗi page của page table. Nó bao gồm nhiều page directory entries (PDE). Một PDE (tối thiểu) có một valid bit và một page frame number (PFN), tương tự như một PTE. Tuy nhiên, ý nghĩa của valid bit ở đây hơi khác: nếu PDE hợp lệ, điều đó có nghĩa là ít nhất một page của page table mà entry này trỏ tới (thông qua PFN) là hợp lệ, tức là trong ít nhất một PTE trên page đó, valid bit được đặt thành 1. Nếu PDE không hợp lệ (bằng 0), phần còn lại của PDE không có ý nghĩa.
Ưu điểm của multi-level page table so với các cách tiếp cận trước:
- Chỉ cấp phát không gian page table tỷ lệ thuận với lượng address space đang sử dụng → gọn nhẹ và hỗ trợ tốt sparse address space (không gian địa chỉ thưa).
- Nếu được thiết kế cẩn thận, mỗi phần của page table vừa khít trong một page, giúp quản lý bộ nhớ dễ dàng hơn; OS chỉ cần lấy page trống tiếp theo khi cần cấp phát hoặc mở rộng page table.
TIP: UNDERSTAND TIME-SPACE TRADE-OFFS
(Hiểu sự đánh đổi giữa thời gian và không gian)
Khi xây dựng một cấu trúc dữ liệu, luôn cần cân nhắc sự đánh đổi giữa thời gian và không gian. Thông thường, nếu muốn truy cập nhanh hơn, bạn sẽ phải trả giá bằng việc sử dụng nhiều bộ nhớ hơn.
So sánh với linear page table đơn giản (không phân trang) 2, vốn chỉ là một mảng PTE được đánh chỉ số bởi VPN: với cấu trúc này, toàn bộ linear page table phải nằm liên tục trong physical memory. Với một page table lớn (ví dụ 4MB), việc tìm một khối bộ nhớ vật lý trống liên tục lớn như vậy là một thách thức. Với cấu trúc nhiều cấp, ta thêm một mức gián tiếp thông qua page directory, trỏ tới các phần của page table; mức gián tiếp này cho phép đặt các page của page table ở bất kỳ đâu trong physical memory.
Tuy nhiên, multi-level table cũng có chi phí: khi xảy ra TLB miss, cần hai lần tải dữ liệu từ bộ nhớ để lấy thông tin dịch địa chỉ (một lần cho page directory, một lần cho PTE), so với chỉ một lần ở linear page table. Đây là ví dụ nhỏ về time-space trade-off: chúng ta muốn bảng nhỏ hơn (và đã đạt được), nhưng không miễn phí; mặc dù trong trường hợp phổ biến (TLB hit) hiệu năng là như nhau, nhưng khi TLB miss, chi phí cao hơn.
Một nhược điểm khác là độ phức tạp: dù phần cứng hay OS xử lý tra cứu page table (khi TLB miss), thì việc này chắc chắn phức tạp hơn so với linear page table. Thường thì chúng ta chấp nhận tăng độ phức tạp để cải thiện hiệu năng hoặc giảm chi phí; với multi-level table, chúng ta làm tra cứu page table phức tạp hơn để tiết kiệm bộ nhớ quý giá.
Ở đây, chúng ta giả định rằng tất cả page table đều nằm hoàn toàn trong physical memory (tức là không bị swap ra đĩa); giả định này sẽ được nới lỏng ở phần sau.
A Detailed Multi-Level Example
(Một ví dụ chi tiết về bảng trang nhiều cấp)
Để hiểu rõ hơn ý tưởng của multi-level page table, hãy xét một ví dụ:
- Address space nhỏ 16KB
- Page 64 byte
Như vậy, ta có virtual address 14-bit, với 8 bit cho VPN và 6 bit cho offset. Linear page table sẽ có 2^8 (256) entry, ngay cả khi chỉ một phần nhỏ address space được sử dụng. Figure 20.4 minh họa một ví dụ như vậy.
 Figure 20.4: A 16KB Address Space With 64-byte Pages
Figure 20.4: A 16KB Address Space With 64-byte Pages
(Không gian địa chỉ 16KB với page 64 byte)
Trong ví dụ này:
- Virtual pages 0 và 1 dành cho code
- Virtual pages 4 và 5 dành cho heap
- Virtual pages 254 và 255 dành cho stack
- Các page còn lại không dùng.
Để xây dựng two-level page table (bảng trang hai cấp) cho address space này, ta bắt đầu với linear page table đầy đủ và chia nó thành các đơn vị kích thước page.
- Page table đầy đủ có 256 entry
- Mỗi PTE = 4 byte → page table = 1KB (256 × 4 byte)
- Với page 64 byte, page table 1KB được chia thành 16 page
Chỉ số page-table index (viết tắt là PTIndex) này có thể được dùng để đánh chỉ số vào chính page table, từ đó cho chúng ta địa chỉ của PTE (page-table entry — mục bảng trang):
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
Lưu ý rằng page-frame number (PFN — số khung trang vật lý) lấy từ page-directory entry (PDE — mục thư mục trang) phải được dịch trái (left-shift) vào đúng vị trí trước khi kết hợp với chỉ số page table để tạo thành địa chỉ của PTE.
Để xem toàn bộ quá trình này có hợp lý không, chúng ta sẽ điền một số giá trị thực tế vào multi-level page table (bảng trang nhiều cấp) và dịch một địa chỉ ảo cụ thể. Hãy bắt đầu với page directory (thư mục trang) cho ví dụ này (bên trái Figure 20.5).
 Figure 20.5: A Page Directory, And Pieces Of Page Table
Figure 20.5: A Page Directory, And Pieces Of Page Table
(Một thư mục trang và các phần của bảng trang)
Trong hình, bạn có thể thấy mỗi PDE mô tả thông tin về một page của page table trong address space. Trong ví dụ này, chúng ta có hai vùng hợp lệ trong address space (ở đầu và cuối), và một số lượng lớn ánh xạ không hợp lệ ở giữa.
Trong physical page 100 (PFN của page 0 trong page table), chúng ta có page đầu tiên chứa 16 PTE cho 16 VPN đầu tiên trong address space. Xem phần giữa của Figure 20.5 để biết nội dung của phần này trong page table.
Page này của page table chứa ánh xạ cho 16 VPN đầu tiên; trong ví dụ, VPN 0 và 1 là hợp lệ (code segment), cũng như VPN 4 và 5 (heap). Do đó, bảng có thông tin ánh xạ cho từng page này. Các entry còn lại được đánh dấu invalid (không hợp lệ).
Page hợp lệ còn lại của page table nằm trong PFN 101. Page này chứa ánh xạ cho 16 VPN cuối cùng của address space; xem phần bên phải của Figure 20.5 để biết chi tiết.
Trong ví dụ, VPN 254 và 255 (stack) có ánh xạ hợp lệ. Hy vọng từ ví dụ này, chúng ta có thể thấy lượng bộ nhớ tiết kiệm được khi dùng cấu trúc đánh chỉ số nhiều cấp. Trong ví dụ này, thay vì cấp phát đủ 16 page cho một linear page table, chúng ta chỉ cấp phát 3 page: một cho page directory, và hai cho các phần của page table có ánh xạ hợp lệ. Với address space lớn (32-bit hoặc 64-bit), mức tiết kiệm sẽ còn lớn hơn nhiều.
TIP: BE WARY OF COMPLEXITY
(Cẩn trọng với độ phức tạp)
Các nhà thiết kế hệ thống nên thận trọng khi thêm độ phức tạp vào hệ thống. Một kỹ sư hệ thống giỏi sẽ triển khai hệ thống ít phức tạp nhất nhưng vẫn hoàn thành nhiệm vụ. Ví dụ, nếu dung lượng đĩa dồi dào, bạn không nên thiết kế một hệ thống file cố gắng tiết kiệm từng byte; tương tự, nếu bộ xử lý nhanh, tốt hơn là viết một module trong OS rõ ràng, dễ hiểu thay vì tối ưu CPU đến mức cực đoan bằng mã hợp ngữ khó bảo trì. Hãy cảnh giác với sự phức tạp không cần thiết, trong mã tối ưu sớm hoặc các hình thức khác; những cách tiếp cận như vậy khiến hệ thống khó hiểu, khó bảo trì và khó gỡ lỗi. Như Antoine de Saint-Exupery từng viết: “Sự hoàn hảo đạt được không phải khi không còn gì để thêm vào, mà là khi không còn gì để bớt đi.” Điều ông không viết: “Nói về sự hoàn hảo thì dễ hơn nhiều so với việc đạt được nó.”
Cuối cùng, hãy sử dụng thông tin này để thực hiện một phép dịch địa chỉ. Đây là một địa chỉ tham chiếu tới byte thứ 0 của VPN 254: 0x3F80, hay ở dạng nhị phân là 11 1111 1000 0000.
Nhớ rằng chúng ta sẽ dùng 4 bit cao nhất của VPN để đánh chỉ số vào page directory. Do đó, 1111 sẽ chọn entry cuối cùng (thứ 15, nếu bắt đầu từ 0) của page directory ở trên. Entry này trỏ tới một page hợp lệ của page table nằm tại địa chỉ PFN 101. Sau đó, chúng ta dùng 4 bit tiếp theo của VPN (1110) để đánh chỉ số vào page này của page table và tìm PTE mong muốn. 1110 là entry áp chót (thứ 14) trên page, và cho biết page 254 của address space được ánh xạ tới physical page 55. Bằng cách ghép PFN=55 (hex 0x37) với offset=000000, chúng ta có thể tạo ra physical address mong muốn và gửi yêu cầu tới hệ thống bộ nhớ:
PhysAddr = (PTE.PFN << SHIFT) + offset
= 00 1101 1100 0000
= 0x0DC0
Bây giờ, bạn đã có ý tưởng về cách xây dựng một two-level page table (bảng trang hai cấp), sử dụng page directory trỏ tới các page của page table. Tuy nhiên, công việc của chúng ta chưa kết thúc. Như sẽ thảo luận ngay sau đây, đôi khi hai cấp page table là chưa đủ.
More Than Two Levels
(Hơn hai cấp)
Trong ví dụ trên, chúng ta giả định multi-level page table chỉ có hai cấp: một page directory và các phần của page table. Trong một số trường hợp, một cây sâu hơn là khả thi (và thực sự cần thiết).
Hãy lấy một ví dụ đơn giản để thấy tại sao multi-level table sâu hơn lại hữu ích. Trong ví dụ này, giả sử chúng ta có virtual address space 30-bit, và page nhỏ (512 byte). Khi đó, virtual address có thành phần virtual page number (VPN) 21-bit và offset 9-bit.
Hãy nhớ mục tiêu khi xây dựng multi-level page table: làm cho mỗi phần của page table vừa trong một page. Cho đến giờ, chúng ta mới chỉ xét bản thân page table; nhưng nếu page directory trở nên quá lớn thì sao?
Để xác định cần bao nhiêu cấp trong multi-level table để tất cả các phần của page table vừa trong một page, ta bắt đầu bằng việc xác định số lượng PTE có thể chứa trong một page. Với kích thước page 512 byte và giả sử mỗi PTE là 4 byte, ta có thể chứa 128 PTE trên một page. Khi đánh chỉ số vào một page của page table, ta sẽ cần 7 bit ít quan trọng nhất (log₂ 128) của VPN làm chỉ số:
Bây giờ, khi đánh chỉ số vào upper-level page directory (thư mục trang cấp cao), chúng ta sử dụng các bit cao nhất của virtual address (PD Index 0 trong sơ đồ); chỉ số này được dùng để lấy page-directory entry (PDE — mục thư mục trang) từ page directory cấp cao nhất. Nếu hợp lệ, cấp thứ hai của page directory sẽ được tra cứu bằng cách kết hợp physical frame number (PFN — số khung trang vật lý) từ PDE cấp cao nhất với phần tiếp theo của VPN (PD Index 1). Cuối cùng, nếu hợp lệ, địa chỉ của PTE (page-table entry — mục bảng trang) có thể được hình thành bằng cách sử dụng page-table index kết hợp với địa chỉ từ PDE cấp thứ hai. Ồ! Khá nhiều bước chỉ để tra cứu một mục trong multi-level table (bảng nhiều cấp).
The Translation Process: Remember the TLB
(Quy trình dịch địa chỉ: Đừng quên TLB)
Để tóm tắt toàn bộ quá trình dịch địa chỉ sử dụng two-level page table (bảng trang hai cấp), chúng ta một lần nữa trình bày luồng điều khiển dưới dạng thuật toán (Figure 20.6). Hình này cho thấy điều gì xảy ra trong phần cứng (giả sử hardware-managed TLB — TLB do phần cứng quản lý) khi có mỗi lần tham chiếu bộ nhớ.
 Figure 20.6: Multi-level Page Table Control Flow
Figure 20.6: Multi-level Page Table Control Flow
(Luồng điều khiển bảng trang nhiều cấp)
Như bạn thấy trong hình, trước khi bất kỳ truy cập phức tạp nào tới multi-level page table diễn ra, phần cứng sẽ kiểm tra TLB trước; nếu hit, physical address (địa chỉ vật lý) sẽ được tạo trực tiếp mà không cần truy cập page table, giống như trước đây. Chỉ khi TLB miss xảy ra, phần cứng mới cần thực hiện toàn bộ quá trình tra cứu nhiều cấp. Trên đường này, bạn có thể thấy chi phí của two-level page table truyền thống: cần thêm hai lần truy cập bộ nhớ để tìm một bản dịch hợp lệ.
20.4 Inverted Page Tables
(Bảng trang đảo)
Một cách tiết kiệm không gian cực đoan hơn trong thế giới page table là inverted page table (bảng trang đảo). Ở đây, thay vì có nhiều page table (một cho mỗi process trong hệ thống), chúng ta giữ một page table duy nhất, trong đó mỗi entry tương ứng với một physical page (trang vật lý) của hệ thống. Entry này cho biết process nào đang sử dụng page đó, và virtual page (trang ảo) nào của process đó được ánh xạ tới page vật lý này.
Việc tìm entry đúng bây giờ là vấn đề tìm kiếm trong cấu trúc dữ liệu này. Quét tuyến tính sẽ tốn kém, do đó thường xây dựng một hash table (bảng băm) trên cấu trúc cơ sở để tăng tốc tra cứu. PowerPC là một ví dụ về kiến trúc sử dụng cách này [JM98].
Nói chung hơn, inverted page table minh họa cho điều chúng ta đã nói từ đầu: page table chỉ là data structure (cấu trúc dữ liệu). Bạn có thể làm nhiều điều “điên rồ” với cấu trúc dữ liệu — làm chúng nhỏ hơn hoặc lớn hơn, chậm hơn hoặc nhanh hơn. Multi-level và inverted page table chỉ là hai ví dụ trong số rất nhiều cách có thể áp dụng.
20.5 Swapping the Page Tables to Disk
(Đưa page table ra đĩa)
Cuối cùng, chúng ta bàn về việc nới lỏng một giả định cuối cùng. Cho đến nay, chúng ta giả định rằng page table nằm trong kernel-owned physical memory (bộ nhớ vật lý thuộc quyền quản lý của kernel). Ngay cả với nhiều thủ thuật để giảm kích thước page table, vẫn có khả năng chúng quá lớn để vừa trong bộ nhớ cùng lúc. Do đó, một số hệ thống đặt page table trong kernel virtual memory (bộ nhớ ảo của kernel), cho phép hệ thống swap (hoán đổi) một số page table này ra đĩa khi bộ nhớ bị áp lực. Chúng ta sẽ nói kỹ hơn về điều này trong một chương sau (cụ thể là nghiên cứu tình huống về VAX/VMS), khi đã hiểu rõ hơn cách di chuyển các page vào và ra khỏi bộ nhớ.
20.6 Summary
(Tóm tắt)
Chúng ta đã thấy cách các page table thực tế được xây dựng; không nhất thiết chỉ là mảng tuyến tính mà có thể là các data structure phức tạp hơn. Sự đánh đổi (trade-off) mà các bảng này đưa ra là giữa time (thời gian) và space (không gian) — bảng càng lớn, thời gian xử lý một TLB miss càng nhanh, và ngược lại — do đó, lựa chọn cấu trúc phù hợp phụ thuộc mạnh mẽ vào các ràng buộc của môi trường cụ thể.
Trong một hệ thống bị giới hạn bộ nhớ (như nhiều hệ thống cũ), các cấu trúc nhỏ là hợp lý; trong một hệ thống có lượng bộ nhớ hợp lý và với workload (khối lượng công việc) sử dụng tích cực nhiều page, một bảng lớn hơn để tăng tốc xử lý TLB miss có thể là lựa chọn đúng. Với software-managed TLBs (TLB do phần mềm quản lý), toàn bộ không gian thiết kế cấu trúc dữ liệu được mở ra cho các nhà sáng tạo hệ điều hành (ám chỉ: chính bạn). Bạn có thể nghĩ ra những cấu trúc mới nào? Chúng giải quyết vấn đề gì? Hãy suy nghĩ về những câu hỏi này khi bạn đi ngủ, và mơ những giấc mơ lớn mà chỉ các nhà phát triển hệ điều hành mới có thể mơ.