45. Tính toàn vẹn và bảo vệ dữ liệu (Data Integrity and Protection)
Bên cạnh những cải tiến cơ bản đã được tìm thấy trong các file system (hệ thống tệp) mà chúng ta đã nghiên cứu cho đến nay, vẫn còn một số tính năng đáng để tìm hiểu. Trong chương này, chúng ta sẽ một lần nữa tập trung vào độ tin cậy (reliability) (trước đây đã nghiên cứu về độ tin cậy của hệ thống lưu trữ trong chương về RAID). Cụ thể, một file system hoặc hệ thống lưu trữ nên làm gì để đảm bảo dữ liệu được an toàn, xét đến bản chất không đáng tin cậy của các thiết bị lưu trữ hiện đại?
Lĩnh vực tổng quát này được gọi là data integrity (tính toàn vẹn dữ liệu) hoặc data protection (bảo vệ dữ liệu). Do đó, chúng ta sẽ tìm hiểu các kỹ thuật được sử dụng để đảm bảo rằng dữ liệu bạn đưa vào hệ thống lưu trữ sẽ vẫn giữ nguyên khi hệ thống lưu trữ trả lại cho bạn.
THE CRUX: LÀM THẾ NÀO ĐỂ ĐẢM BẢO TÍNH TOÀN VẸN DỮ LIỆU
Hệ thống nên làm gì để đảm bảo dữ liệu được ghi xuống lưu trữ được bảo vệ? Cần những kỹ thuật nào? Làm thế nào để các kỹ thuật này hoạt động hiệu quả, với chi phí về không gian và thời gian thấp?
45.1 Các dạng lỗi của đĩa (Disk Failure Modes)
Như bạn đã học trong chương về RAID, đĩa không hoàn hảo và đôi khi có thể bị hỏng. Trong các hệ thống RAID ban đầu, mô hình lỗi khá đơn giản: hoặc toàn bộ đĩa hoạt động, hoặc nó hỏng hoàn toàn, và việc phát hiện lỗi như vậy là khá đơn giản. Mô hình lỗi fail-stop (ngừng hoạt động hoàn toàn) này khiến việc xây dựng RAID trở nên tương đối dễ dàng [S90].
Điều mà bạn chưa được học là còn nhiều dạng lỗi khác mà các ổ đĩa hiện đại có thể gặp phải. Cụ thể, như Bairavasundaram và cộng sự đã nghiên cứu chi tiết [B+07, B+08], các ổ đĩa hiện đại đôi khi vẫn hoạt động gần như bình thường nhưng lại gặp khó khăn khi truy cập thành công một hoặc nhiều block. Đặc biệt, có hai loại lỗi single-block (trên một block đơn) phổ biến và đáng để xem xét: latent sector errors (LSE – lỗi sector tiềm ẩn) và block corruption (hỏng block). Chúng ta sẽ thảo luận chi tiết từng loại.
...
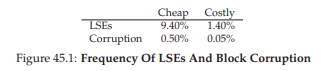
Hình 45.1: Tần suất xuất hiện của LSE và Block Corruption
LSE xảy ra khi một sector (hoặc nhóm sector) của đĩa bị hỏng theo một cách nào đó. Ví dụ, nếu đầu đọc/ghi của đĩa chạm vào bề mặt vì một lý do nào đó (head crash – sự cố đầu đọc, điều vốn không nên xảy ra trong vận hành bình thường), nó có thể làm hỏng bề mặt, khiến các bit không thể đọc được. Tia vũ trụ (cosmic rays) cũng có thể làm lật bit, dẫn đến nội dung sai. May mắn thay, in-disk error correcting codes (ECC – mã sửa lỗi tích hợp trong đĩa) được ổ đĩa sử dụng để xác định liệu các bit trên đĩa trong một block có đúng hay không, và trong một số trường hợp có thể sửa chúng; nếu dữ liệu không đúng và ổ đĩa không có đủ thông tin để sửa lỗi, ổ sẽ trả về lỗi khi có yêu cầu đọc.
Cũng có những trường hợp một block của đĩa bị hỏng theo cách mà chính ổ đĩa không thể phát hiện. Ví dụ, firmware của ổ đĩa bị lỗi có thể ghi một block vào sai vị trí; trong trường hợp này, ECC của ổ đĩa cho biết nội dung block là “tốt”, nhưng từ góc nhìn của client thì block sai sẽ được trả về khi truy cập. Tương tự, một block có thể bị hỏng khi nó được truyền từ host tới ổ đĩa qua một bus bị lỗi; dữ liệu bị hỏng này sẽ được ổ đĩa lưu lại, nhưng không phải là dữ liệu mà client mong muốn. Những loại lỗi này đặc biệt nguy hiểm vì chúng là silent faults (lỗi im lặng); ổ đĩa không đưa ra bất kỳ dấu hiệu nào về vấn đề khi trả về dữ liệu bị lỗi.
Prabhakaran và cộng sự mô tả quan điểm hiện đại hơn về lỗi đĩa này là mô hình lỗi fail-partial (fail-partial disk failure model) [P+05]. Trong mô hình này, đĩa vẫn có thể hỏng hoàn toàn (giống như trong mô hình fail-stop truyền thống); tuy nhiên, đĩa cũng có thể trông như vẫn hoạt động bình thường nhưng lại có một hoặc nhiều block trở nên không thể truy cập được (tức là LSE – latent sector error, lỗi sector tiềm ẩn) hoặc chứa nội dung sai (tức là corruption – hỏng dữ liệu). Do đó, khi truy cập một đĩa có vẻ đang hoạt động, đôi khi nó có thể trả về lỗi khi cố đọc hoặc ghi một block nhất định (non-silent partial fault – lỗi bộ phận không im lặng), và đôi khi nó có thể đơn giản trả về dữ liệu sai (silent partial fault – lỗi bộ phận im lặng).
Cả hai loại lỗi này đều tương đối hiếm, nhưng thực sự hiếm đến mức nào? Hình 45.1 tóm tắt một số phát hiện từ hai nghiên cứu của Bairavasundaram [B+07, B+08].
Hình này cho thấy tỷ lệ phần trăm ổ đĩa xuất hiện ít nhất một LSE hoặc một lỗi hỏng block trong suốt thời gian nghiên cứu (khoảng 3 năm, trên hơn 1,5 triệu ổ đĩa). Hình cũng chia nhỏ kết quả thành hai loại: ổ “rẻ” (thường là ổ SATA) và ổ “đắt” (thường là ổ SCSI hoặc Fibre Channel). Như bạn có thể thấy, mặc dù mua ổ chất lượng cao hơn giúp giảm tần suất của cả hai loại vấn đề (khoảng một bậc độ lớn – order of magnitude), nhưng chúng vẫn xảy ra đủ thường xuyên để bạn cần cân nhắc kỹ cách xử lý trong hệ thống lưu trữ của mình.
Một số phát hiện bổ sung về LSE:
- Ổ đắt tiền có nhiều hơn một LSE có khả năng phát sinh thêm lỗi tương đương với ổ rẻ tiền.
- Đối với hầu hết các ổ, tỷ lệ lỗi hàng năm tăng lên trong năm thứ hai.
- Số lượng LSE tăng theo kích thước đĩa.
- Hầu hết các ổ có LSE đều có ít hơn 50 lỗi.
- Ổ có LSE có khả năng phát sinh thêm LSE cao hơn.
- Tồn tại mức độ đáng kể của spatial locality (tính cục bộ không gian) và temporal locality (tính cục bộ thời gian).
- Disk scrubbing (quét đĩa định kỳ) là hữu ích (hầu hết LSE được phát hiện theo cách này).
Một số phát hiện về corruption (hỏng dữ liệu):
- Xác suất hỏng dữ liệu thay đổi rất nhiều giữa các model ổ khác nhau trong cùng một loại ổ.
- Ảnh hưởng của tuổi thọ khác nhau giữa các model.
- Workload (tải công việc) và kích thước đĩa có ít tác động đến corruption.
- Hầu hết các ổ bị corruption chỉ có một vài lỗi hỏng.
- Corruption không độc lập trong cùng một ổ hoặc giữa các ổ trong RAID.
- Tồn tại spatial locality và một phần temporal locality.
- Có mối tương quan yếu giữa corruption và LSE.
Để tìm hiểu thêm về các lỗi này, bạn nên đọc các bài báo gốc [B+07, B+08]. Nhưng hy vọng rằng điểm chính đã rõ: nếu bạn thực sự muốn xây dựng một hệ thống lưu trữ đáng tin cậy, bạn phải tích hợp cơ chế để phát hiện và khôi phục cả LSE và block corruption.
45.2 Xử lý lỗi sector tiềm ẩn (Handling Latent Sector Errors)
Với hai dạng lỗi bộ phận (partial disk failure) mới này, chúng ta cần xem có thể làm gì để xử lý chúng. Trước tiên, hãy giải quyết dạng dễ hơn, đó là latent sector errors (LSE – lỗi sector tiềm ẩn).
THE CRUX: CÁCH XỬ LÝ LỖI SECTOR TIỀM ẨN
Hệ thống lưu trữ nên xử lý lỗi sector tiềm ẩn như thế nào? Cần thêm bao nhiêu cơ chế bổ sung để xử lý dạng lỗi bộ phận này?
Thực tế, lỗi LSE khá đơn giản để xử lý, vì chúng (theo định nghĩa) dễ dàng được phát hiện. Khi một hệ thống lưu trữ cố gắng truy cập một block và ổ đĩa trả về lỗi, hệ thống lưu trữ chỉ cần sử dụng bất kỳ cơ chế redundancy (dự phòng) nào mà nó có để trả lại dữ liệu đúng. Ví dụ, trong một hệ thống RAID dạng mirror, hệ thống sẽ truy cập bản sao thay thế; trong hệ thống RAID-4 hoặc RAID-5 dựa trên parity (chẵn lẻ), hệ thống sẽ tái tạo block từ các block khác trong nhóm parity. Do đó, các vấn đề dễ phát hiện như LSE có thể được khôi phục dễ dàng thông qua các cơ chế dự phòng tiêu chuẩn.
Sự gia tăng của LSE theo thời gian đã ảnh hưởng đến thiết kế RAID. Một vấn đề đặc biệt thú vị xuất hiện trong các hệ thống RAID-4/5 khi cả lỗi toàn bộ đĩa (full-disk fault) và LSE xảy ra đồng thời. Cụ thể, khi một ổ đĩa hỏng hoàn toàn, RAID sẽ cố gắng tái tạo ổ đĩa đó (ví dụ, sang một hot spare) bằng cách đọc toàn bộ các ổ còn lại trong nhóm parity và tính toán lại các giá trị bị thiếu. Nếu trong quá trình tái tạo, một LSE được phát hiện trên bất kỳ ổ nào khác, chúng ta sẽ gặp vấn đề: quá trình tái tạo không thể hoàn tất thành công.
Để giải quyết vấn đề này, một số hệ thống bổ sung thêm mức độ dự phòng. Ví dụ, RAID-DP của NetApp có tương đương với hai ổ parity thay vì một [C+04]. Khi một LSE được phát hiện trong quá trình tái tạo, parity bổ sung sẽ giúp tái tạo block bị thiếu. Tất nhiên, điều này có chi phí: duy trì hai block parity cho mỗi stripe tốn kém hơn; tuy nhiên, bản chất log-structured của file system NetApp WAFL giúp giảm chi phí này trong nhiều trường hợp [HLM94]. Chi phí còn lại là dung lượng lưu trữ, dưới dạng một ổ đĩa bổ sung cho block parity thứ hai.
45.3 Phát hiện lỗi hỏng dữ liệu: Checksum (Detecting Corruption: The Checksum)
Bây giờ, hãy giải quyết vấn đề khó hơn: các lỗi im lặng (silent failures) do data corruption (hỏng dữ liệu). Làm thế nào để ngăn người dùng nhận dữ liệu sai khi corruption xảy ra và khiến ổ đĩa trả về dữ liệu không chính xác?
THE CRUX: CÁCH BẢO TOÀN TÍNH TOÀN VẸN DỮ LIỆU KHI XẢY RA CORRUPTION
Với bản chất im lặng của các lỗi này, hệ thống lưu trữ có thể làm gì để phát hiện khi corruption xảy ra? Cần những kỹ thuật nào? Làm thế nào để triển khai chúng một cách hiệu quả?
Không giống như LSE, việc phát hiện corruption là một vấn đề then chốt. Làm thế nào để client biết rằng một block đã bị hỏng? Khi đã biết block cụ thể bị hỏng, quá trình khôi phục cũng giống như trước: bạn cần có một bản sao khác của block đó (và hy vọng là bản sao này không bị hỏng!). Do đó, ở đây chúng ta tập trung vào các kỹ thuật phát hiện.
Cơ chế chính mà các hệ thống lưu trữ hiện đại sử dụng để bảo toàn data integrity (tính toàn vẹn dữ liệu) được gọi là checksum. Checksum đơn giản là kết quả của một hàm nhận vào một khối dữ liệu (ví dụ: một block 4KB) và tính toán một giá trị dựa trên dữ liệu đó, tạo ra một bản tóm tắt nhỏ về nội dung dữ liệu (ví dụ: 4 hoặc 8 byte). Bản tóm tắt này được gọi là checksum. Mục tiêu của phép tính này là cho phép hệ thống phát hiện nếu dữ liệu bị hỏng hoặc bị thay đổi bằng cách lưu checksum cùng với dữ liệu và sau đó, khi truy cập lại, xác nhận rằng checksum hiện tại của dữ liệu khớp với giá trị checksum ban đầu đã lưu.
TIP: KHÔNG CÓ BỮA TRƯA MIỄN PHÍ
“There’s No Such Thing As A Free Lunch” (TNSTAAFL) là một thành ngữ Mỹ cổ, ngụ ý rằng khi bạn tưởng như đang nhận được thứ gì đó miễn phí, thực tế bạn vẫn phải trả một cái giá nào đó. Thành ngữ này bắt nguồn từ thời các quán ăn quảng cáo bữa trưa miễn phí để thu hút khách; chỉ khi bước vào, bạn mới nhận ra rằng để có được “bữa trưa miễn phí” đó, bạn phải mua một hoặc nhiều đồ uống có cồn. Tất nhiên, điều này có thể không phải là vấn đề, đặc biệt nếu bạn là một người thích uống rượu (hoặc một sinh viên đại học điển hình).
Các hàm Checksum phổ biến (Common Checksum Functions)
Có nhiều hàm khác nhau được sử dụng để tính checksum, và chúng khác nhau về độ mạnh (strength – tức là khả năng bảo vệ tính toàn vẹn dữ liệu tốt đến mức nào) và tốc độ (speed – tức là tốc độ tính toán). Một sự đánh đổi (trade-off) phổ biến trong các hệ thống xuất hiện ở đây: thường thì, càng bảo vệ tốt hơn thì chi phí càng cao. Không có cái gọi là “bữa trưa miễn phí”.
Một hàm checksum đơn giản mà một số hệ thống sử dụng dựa trên phép exclusive or (XOR). Với checksum dựa trên XOR, giá trị checksum được tính bằng cách XOR từng phần (chunk) của block dữ liệu cần tính checksum, từ đó tạo ra một giá trị duy nhất đại diện cho XOR của toàn bộ block.
Để minh họa cụ thể hơn, giả sử chúng ta đang tính một checksum 4 byte cho một block 16 byte (block này tất nhiên là quá nhỏ để thực tế là một sector hoặc block đĩa, nhưng sẽ dùng cho ví dụ). 16 byte dữ liệu, ở dạng hex, như sau:
365e c4cd ba14 8a92 ecef 2c3a 40be f666
Nếu biểu diễn ở dạng nhị phân, ta có:
0011 0110 0101 1110 1100 0100 1100 1101
1011 1010 0001 0100 1000 1010 1001 0010
1110 1100 1110 1111 0010 1100 0011 1010
0100 0000 1011 1110 1111 0110 0110 0110
Vì chúng ta đã sắp xếp dữ liệu thành các nhóm 4 byte mỗi hàng, nên dễ dàng thấy giá trị checksum sẽ là gì: thực hiện phép XOR trên từng cột để có giá trị checksum cuối cùng:
0010 0000 0001 1011 1001 0100 0000 0011
Kết quả, ở dạng hex, là 0x201b9403.
XOR là một checksum hợp lý nhưng có hạn chế. Ví dụ, nếu hai bit ở cùng một vị trí trong mỗi đơn vị được tính checksum thay đổi, checksum sẽ không phát hiện ra lỗi. Vì lý do này, người ta đã nghiên cứu các hàm checksum khác.
Một hàm checksum cơ bản khác là cộng (addition). Cách tiếp cận này có ưu điểm là nhanh; việc tính toán chỉ yêu cầu thực hiện phép cộng bù 2 (2’s-complement addition) trên từng phần dữ liệu, bỏ qua tràn số (overflow). Nó có thể phát hiện nhiều thay đổi trong dữ liệu, nhưng không tốt nếu dữ liệu, chẳng hạn, bị dịch chuyển.
Một thuật toán phức tạp hơn một chút được gọi là Fletcher checksum, đặt theo tên của nhà phát minh John G. Fletcher [F82]. Nó khá đơn giản để tính toán và bao gồm việc tính hai byte kiểm tra, s1 và s2. Cụ thể, giả sử một block D gồm các byte d1 ... dn; s1 được định nghĩa như sau:
s1 = (s1 + di) mod 255 (tính trên tất cả di);
s2 lần lượt là:
s2 = (s2 + s1) mod 255 (cũng tính trên tất cả di) [F04].
Fletcher checksum gần mạnh như CRC (xem bên dưới), phát hiện tất cả lỗi 1 bit, 2 bit, và nhiều lỗi dạng burst [F04].
Một checksum phổ biến khác là cyclic redundancy check (CRC). Giả sử bạn muốn tính checksum cho một block dữ liệu D. Tất cả những gì bạn làm là coi D như một số nhị phân lớn (thực chất nó chỉ là một chuỗi bit) và chia nó cho một giá trị k đã được thống nhất. Phần dư của phép chia này chính là giá trị CRC. Thực tế, phép chia modulo nhị phân này có thể được triển khai khá hiệu quả, và đó là lý do CRC cũng rất phổ biến trong mạng máy tính. Xem thêm chi tiết ở [M13].
Dù sử dụng phương pháp nào, rõ ràng là không có checksum nào hoàn hảo: có thể tồn tại hai block dữ liệu với nội dung khác nhau nhưng có cùng checksum, hiện tượng này gọi là collision (xung đột). Điều này là trực quan: sau cùng, tính checksum là lấy một thứ lớn (ví dụ: 4KB) và tạo ra một bản tóm tắt nhỏ hơn nhiều (ví dụ: 4 hoặc 8 byte). Khi chọn một hàm checksum tốt, chúng ta cố gắng tìm một hàm giảm thiểu khả năng xảy ra collision trong khi vẫn dễ tính toán.
Bố trí Checksum (Checksum Layout)
Bây giờ bạn đã hiểu phần nào cách tính checksum, hãy phân tích cách sử dụng checksum trong một hệ thống lưu trữ. Câu hỏi đầu tiên cần giải quyết là bố trí checksum – tức là checksum nên được lưu trên đĩa như thế nào?
Cách cơ bản nhất là lưu một checksum cùng với mỗi sector (hoặc block) của đĩa. Cho một block dữ liệu D, gọi checksum của dữ liệu đó là C(D). Như vậy, nếu không có checksum, bố cục đĩa sẽ như sau:
...
Với checksum, bố cục sẽ thêm một checksum cho mỗi block:
...
Vì checksum thường nhỏ (ví dụ: 8 byte), và đĩa chỉ có thể ghi theo đơn vị sector (512 byte) hoặc bội số của nó, một vấn đề phát sinh là làm thế nào để đạt được bố cục trên. Một giải pháp mà các nhà sản xuất ổ đĩa áp dụng là định dạng ổ với sector 520 byte; thêm 8 byte mỗi sector để lưu checksum.
Trong các ổ đĩa không có chức năng này, file system phải tìm cách lưu checksum được đóng gói vào các block 512 byte. Một khả năng như sau:
...
Trong sơ đồ này, n checksum được lưu cùng nhau trong một sector, tiếp theo là n block dữ liệu, tiếp theo là một sector checksum khác cho n block tiếp theo, và cứ thế tiếp diễn. Cách tiếp cận này có ưu điểm là hoạt động trên mọi loại đĩa, nhưng có thể kém hiệu quả hơn; nếu file system, chẳng hạn, muốn ghi đè block D1, nó phải đọc sector checksum chứa C(D1), cập nhật C(D1) trong đó, rồi ghi lại sector checksum và block dữ liệu mới D1 (tức là một lần đọc và hai lần ghi). Cách tiếp cận trước đó (một checksum cho mỗi sector) chỉ cần thực hiện một lần ghi.
45.4 Sử dụng Checksum (Using Checksums)
Khi đã quyết định được bố trí checksum (checksum layout), chúng ta có thể tiến hành tìm hiểu cách sử dụng checksum trong thực tế. Khi đọc một block D, client (tức là file system hoặc bộ điều khiển lưu trữ – storage controller) cũng sẽ đọc checksum của block đó từ đĩa, ký hiệu là ( C_s(D) ), gọi là stored checksum (checksum đã lưu – do đó có chỉ số dưới ( C_s )).
Client sau đó tính toán checksum trên block D vừa đọc được, gọi là computed checksum ( C_c(D) ). Tại thời điểm này, client so sánh checksum đã lưu và checksum vừa tính:
- Nếu chúng bằng nhau (tức là ( C_s(D) == C_c(D) )), dữ liệu nhiều khả năng chưa bị hỏng và có thể an toàn trả về cho người dùng.
- Nếu chúng không bằng nhau (tức là ( C_s(D) \neq C_c(D) )), điều này ngụ ý dữ liệu đã thay đổi kể từ thời điểm lưu trữ (vì checksum đã lưu phản ánh giá trị dữ liệu tại thời điểm đó). Trong trường hợp này, chúng ta đã phát hiện ra corruption (hỏng dữ liệu) nhờ checksum.
Khi phát hiện corruption, câu hỏi tự nhiên là: chúng ta nên làm gì?
- Nếu hệ thống lưu trữ có một bản sao dự phòng (redundant copy), câu trả lời rất đơn giản: hãy thử sử dụng bản sao đó.
- Nếu hệ thống lưu trữ không có bản sao dự phòng, khả năng cao là phải trả về lỗi.
Dù trong trường hợp nào, cần nhận thức rằng việc phát hiện corruption không phải là “viên đạn bạc” (magic bullet); nếu không có cách nào khác để lấy dữ liệu không bị hỏng, thì đơn giản là bạn đã hết cách.
45.5 Một vấn đề mới: Misdirected Writes (Ghi sai hướng)
Cơ chế cơ bản được mô tả ở trên hoạt động tốt trong hầu hết các trường hợp block bị hỏng. Tuy nhiên, các ổ đĩa hiện đại có một số dạng lỗi bất thường cần giải pháp khác.
Dạng lỗi đầu tiên đáng chú ý được gọi là misdirected write (ghi sai hướng). Lỗi này xảy ra trong ổ đĩa hoặc bộ điều khiển RAID, khi dữ liệu được ghi xuống đĩa đúng về nội dung nhưng sai vị trí.
- Trong hệ thống một ổ đĩa, điều này có nghĩa là ổ đĩa ghi block ( D_x ) không vào địa chỉ x (như mong muốn) mà lại vào địa chỉ y (do đó “làm hỏng” ( D_y )).
- Trong hệ thống nhiều ổ đĩa, bộ điều khiển có thể ghi ( D_{i,x} ) không vào địa chỉ x của ổ i mà lại vào một ổ khác j.
Do đó, câu hỏi đặt ra là:
THE CRUX: CÁCH XỬ LÝ MISDIRECTED WRITES
Hệ thống lưu trữ hoặc bộ điều khiển đĩa nên phát hiện misdirected writes như thế nào? Checksum cần bổ sung thêm tính năng gì?
Câu trả lời, không có gì ngạc nhiên, là khá đơn giản: thêm một chút thông tin vào mỗi checksum. Trong trường hợp này, việc thêm physical identifier (ID vật lý) là rất hữu ích.
Ví dụ: nếu thông tin được lưu trữ hiện tại bao gồm cả checksum ( C(D) ) và số hiệu ổ đĩa cùng số sector của block, thì client có thể dễ dàng xác định liệu dữ liệu đúng có đang nằm ở đúng vị trí hay không.
Cụ thể, nếu client đang đọc block 4 trên ổ 10 (( D_{10,4} )), thông tin đã lưu nên bao gồm số hiệu ổ đĩa và offset sector, như minh họa bên dưới. Nếu thông tin này không khớp, tức là đã xảy ra misdirected write, và corruption được phát hiện.
Dưới đây là ví dụ về thông tin bổ sung này trong một hệ thống hai ổ đĩa. Lưu ý rằng hình minh họa này, giống như các hình trước, không theo tỷ lệ (not to scale), vì checksum thường rất nhỏ (ví dụ: 8 byte) trong khi block dữ liệu lớn hơn nhiều (ví dụ: 4 KB hoặc hơn).
Từ định dạng trên đĩa (on-disk format), bạn có thể thấy hiện tại có một lượng đáng kể thông tin dư thừa (redundancy) trên đĩa:
- Với mỗi block, số hiệu ổ đĩa được lặp lại bên trong block đó.
- Offset của block cũng được lưu ngay bên cạnh block.
Sự hiện diện của thông tin dư thừa này không có gì bất ngờ; redundancy chính là chìa khóa để phát hiện lỗi (trong trường hợp này) và khôi phục (trong các trường hợp khác). Một chút thông tin bổ sung, dù không thực sự cần thiết với các ổ đĩa “hoàn hảo”, vẫn có thể giúp ích rất nhiều trong việc phát hiện các tình huống sự cố nếu chúng xảy ra.
45.6 Một vấn đề cuối cùng: Lost Writes (Ghi bị mất)
Thật không may, misdirected writes (ghi sai hướng) không phải là vấn đề cuối cùng mà chúng ta cần đề cập. Cụ thể, một số thiết bị lưu trữ hiện đại còn gặp một vấn đề gọi là lost write (ghi bị mất), xảy ra khi thiết bị thông báo cho tầng trên rằng một thao tác ghi đã hoàn tất, nhưng trên thực tế dữ liệu đó không được lưu bền vững; do đó, những gì còn lại trên block là nội dung cũ thay vì nội dung mới đã được cập nhật.
Câu hỏi hiển nhiên ở đây là: liệu bất kỳ chiến lược checksumming (tính checksum) nào ở trên (ví dụ: checksum cơ bản, hoặc physical identity – định danh vật lý) có giúp phát hiện lost write hay không?
Đáng tiếc, câu trả lời là không: block cũ nhiều khả năng vẫn có checksum khớp, và physical ID được sử dụng ở trên (số hiệu ổ đĩa và offset block) cũng sẽ đúng. Do đó, chúng ta có vấn đề cuối cùng:
THE CRUX: CÁCH XỬ LÝ LOST WRITES
Hệ thống lưu trữ hoặc bộ điều khiển đĩa nên phát hiện lost write như thế nào? Checksum cần bổ sung thêm tính năng gì?
Có một số giải pháp khả thi có thể giúp [K+08]. Một cách tiếp cận kinh điển [BS04] là thực hiện write verify hoặc read-after-write; bằng cách đọc lại ngay dữ liệu sau khi ghi, hệ thống có thể đảm bảo rằng dữ liệu thực sự đã được ghi xuống bề mặt đĩa. Tuy nhiên, cách tiếp cận này khá chậm, vì làm tăng gấp đôi số lượng I/O cần thiết để hoàn tất một thao tác ghi.
Một số hệ thống thêm checksum ở một vị trí khác trong hệ thống để phát hiện lost write. Ví dụ, Zettabyte File System (ZFS) của Sun bao gồm một checksum trong mỗi inode của file system và trong các indirect block cho mọi block thuộc về một file. Do đó, ngay cả khi thao tác ghi vào một data block bị mất, checksum trong inode sẽ không khớp với dữ liệu cũ. Chỉ khi cả thao tác ghi vào inode và ghi vào dữ liệu đều bị mất đồng thời thì cơ chế này mới thất bại – một tình huống khó xảy ra (nhưng đáng tiếc là vẫn có thể!).
45.7 Scrubbing (Quét kiểm tra đĩa)
Với tất cả những gì đã thảo luận, bạn có thể tự hỏi: khi nào các checksum này thực sự được kiểm tra? Tất nhiên, một phần việc kiểm tra diễn ra khi dữ liệu được ứng dụng truy cập, nhưng phần lớn dữ liệu hiếm khi được truy cập, và do đó sẽ không được kiểm tra. Dữ liệu không được kiểm tra là một vấn đề đối với hệ thống lưu trữ đáng tin cậy, vì bit rot (sự suy giảm bit theo thời gian) có thể cuối cùng ảnh hưởng đến tất cả các bản sao của một dữ liệu nhất định.
Để khắc phục vấn đề này, nhiều hệ thống sử dụng disk scrubbing (quét kiểm tra đĩa) dưới nhiều hình thức khác nhau [K+08]. Bằng cách định kỳ đọc qua từng block của hệ thống và kiểm tra xem checksum có còn hợp lệ hay không, hệ thống lưu trữ có thể giảm khả năng tất cả các bản sao của một dữ liệu nào đó bị hỏng. Các hệ thống điển hình thường lên lịch quét vào ban đêm hoặc hàng tuần.
45.8 Chi phí (Overheads) của việc sử dụng Checksum
Trước khi kết thúc, chúng ta sẽ thảo luận về một số overhead (chi phí phụ trội) khi sử dụng checksum để bảo vệ dữ liệu. Giống như nhiều hệ thống máy tính khác, có hai loại overhead riêng biệt: overhead về không gian (space) và overhead về thời gian (time).
Overhead về không gian có hai dạng:
-
Thứ nhất là trên đĩa (hoặc phương tiện lưu trữ khác) – mỗi checksum được lưu sẽ chiếm một phần dung lượng trên đĩa, phần này không thể dùng cho dữ liệu người dùng. Một tỷ lệ điển hình có thể là một checksum 8 byte cho mỗi block dữ liệu 4 KB, tương đương với khoảng 0,19% overhead dung lượng trên đĩa.
-
Thứ hai là trong bộ nhớ của hệ thống. Khi truy cập dữ liệu, bộ nhớ phải có chỗ chứa cả checksum và dữ liệu. Tuy nhiên, nếu hệ thống chỉ kiểm tra checksum rồi loại bỏ nó sau khi xong, overhead này chỉ tồn tại trong thời gian ngắn và không đáng lo ngại. Chỉ khi checksum được giữ lại trong bộ nhớ (để tăng mức bảo vệ chống lại memory corruption – lỗi hỏng dữ liệu trong bộ nhớ [Z+13]) thì overhead nhỏ này mới trở nên đáng chú ý.
Mặc dù overhead về không gian là nhỏ, nhưng overhead về thời gian do việc tính toán checksum có thể khá đáng kể. Tối thiểu, CPU phải tính toán checksum cho mỗi block, cả khi dữ liệu được lưu (để xác định giá trị checksum sẽ lưu) và khi dữ liệu được truy cập (để tính lại checksum và so sánh với checksum đã lưu).
Một cách tiếp cận để giảm overhead CPU – được nhiều hệ thống sử dụng checksum áp dụng (bao gồm cả network stack) – là kết hợp việc sao chép dữ liệu và tính checksum thành một hoạt động duy nhất; vì việc sao chép là cần thiết (ví dụ: sao chép dữ liệu từ kernel page cache sang user buffer), nên việc kết hợp sao chép/tính checksum có thể rất hiệu quả.
Ngoài overhead CPU, một số cơ chế checksumming có thể gây thêm overhead I/O, đặc biệt khi checksum được lưu tách biệt khỏi dữ liệu (dẫn đến cần thêm I/O để truy cập chúng), và cho bất kỳ I/O bổ sung nào cần cho quá trình background scrubbing (quét kiểm tra nền).
- Trường hợp đầu tiên có thể giảm bằng thiết kế.
- Trường hợp thứ hai có thể điều chỉnh để giới hạn tác động, ví dụ bằng cách kiểm soát thời điểm thực hiện scrubbing.
Thời điểm giữa đêm, khi hầu hết (nhưng không phải tất cả!) những người làm việc năng suất đã đi ngủ, có thể là lúc thích hợp để thực hiện scrubbing và tăng độ bền vững của hệ thống lưu trữ.
45.9 Tóm tắt (Summary)
Chúng ta đã thảo luận về bảo vệ dữ liệu trong các hệ thống lưu trữ hiện đại, tập trung vào việc triển khai và sử dụng checksum. Các loại checksum khác nhau bảo vệ chống lại các loại lỗi khác nhau; khi các thiết bị lưu trữ phát triển, chắc chắn sẽ xuất hiện các dạng lỗi mới.
Có thể những thay đổi này sẽ buộc cộng đồng nghiên cứu và ngành công nghiệp phải xem xét lại một số phương pháp cơ bản này, hoặc phát minh ra những phương pháp hoàn toàn mới. Thời gian sẽ trả lời. Hoặc cũng có thể không. Thời gian vốn dĩ thú vị theo cách đó.