44. Ổ SSD dựa trên Flash (Flash-based SSDs)
Sau hàng thập kỷ ổ đĩa cứng (HDD) thống trị, một dạng thiết bị lưu trữ bền vững (persistent storage) mới đã nổi lên và ngày càng quan trọng trên thế giới. Được gọi chung là solid-state storage (lưu trữ thể rắn), các thiết bị này không có bộ phận cơ khí hay chuyển động như ổ cứng; thay vào đó, chúng được chế tạo hoàn toàn từ các transistor, tương tự như bộ nhớ và bộ xử lý. Tuy nhiên, khác với bộ nhớ truy cập ngẫu nhiên thông thường (ví dụ: DRAM), thiết bị lưu trữ thể rắn (hay còn gọi là SSD) vẫn giữ được thông tin ngay cả khi mất điện, và do đó là ứng viên lý tưởng để lưu trữ dữ liệu lâu dài.
Công nghệ mà chúng ta tập trung ở đây được gọi là flash (cụ thể hơn là NAND-based flash), được Fujio Masuoka phát minh vào những năm 1980 [M+14]. Flash, như chúng ta sẽ thấy, có một số đặc tính rất riêng. Ví dụ, để ghi vào một phần dữ liệu của nó (tức là một flash page), trước tiên bạn phải xóa một phần lớn hơn (tức là một flash block), và thao tác này khá tốn kém. Ngoài ra, việc ghi quá thường xuyên vào một page sẽ khiến nó bị mòn (wear out). Hai đặc tính này khiến việc xây dựng một SSD dựa trên flash trở thành một thách thức thú vị:
THE CRUX: LÀM THẾ NÀO ĐỂ XÂY DỰNG MỘT SSD DỰA TRÊN FLASH?
Làm thế nào để chúng ta xây dựng một SSD dựa trên flash? Làm thế nào để xử lý chi phí cao của thao tác xóa? Làm thế nào để chế tạo một thiết bị có tuổi thọ dài, khi việc ghi đè lặp lại sẽ làm thiết bị bị mòn? Liệu tiến bộ công nghệ có bao giờ dừng lại? Hay sẽ luôn khiến chúng ta kinh ngạc?
44.1 Lưu trữ một bit (Storing a Single Bit)
Chip flash được thiết kế để lưu trữ một hoặc nhiều bit trong một transistor; mức điện tích bị giữ trong transistor được ánh xạ thành giá trị nhị phân. Trong single-level cell (SLC) flash, chỉ một bit được lưu trong một transistor (tức là 1 hoặc 0); với multi-level cell (MLC) flash, hai bit được mã hóa thành các mức điện tích khác nhau, ví dụ: 00, 01, 10 và 11 được biểu diễn bằng mức điện tích thấp, hơi thấp, hơi cao và cao. Thậm chí còn có triple-level cell (TLC) flash, mã hóa 3 bit trên mỗi cell. Nhìn chung, chip SLC đạt hiệu năng cao hơn và giá thành đắt hơn.
TIP: CẨN THẬN VỚI THUẬT NGỮ
Bạn có thể nhận thấy rằng một số thuật ngữ chúng ta đã sử dụng nhiều lần trước đây (block, page) đang được dùng trong ngữ cảnh của flash, nhưng theo cách hơi khác so với trước. Các thuật ngữ mới không được tạo ra để làm khó bạn (mặc dù đôi khi có thể gây nhầm lẫn), mà xuất hiện vì không có một cơ quan trung ương nào quyết định thống nhất thuật ngữ. Một block đối với bạn có thể là một page đối với người khác, và ngược lại, tùy thuộc vào ngữ cảnh. Nhiệm vụ của bạn rất đơn giản: nắm rõ các thuật ngữ phù hợp trong từng lĩnh vực, và sử dụng chúng sao cho những người am hiểu trong ngành có thể hiểu bạn đang nói gì. Đây là một trong những trường hợp mà giải pháp duy nhất vừa đơn giản vừa đôi khi gây khó chịu: hãy dùng trí nhớ của bạn.
Tất nhiên, có rất nhiều chi tiết về cách lưu trữ ở mức bit này hoạt động, ở cấp độ vật lý thiết bị. Mặc dù nằm ngoài phạm vi của cuốn sách này, bạn có thể tự tìm hiểu thêm [J10].
44.2 Từ bit đến bank/plane (From Bits to Banks/Planes)
Như người Hy Lạp cổ đại từng nói, lưu trữ một bit (hoặc vài bit) thì chưa thể tạo thành một hệ thống lưu trữ. Do đó, chip flash được tổ chức thành các bank hoặc plane, mỗi cái bao gồm một số lượng lớn cell.
Một bank được truy cập theo hai đơn vị kích thước khác nhau: block (đôi khi gọi là erase block), thường có kích thước 128 KB hoặc 256 KB, và page, có kích thước vài KB (ví dụ: 4 KB). Bên trong mỗi bank có rất nhiều block; bên trong mỗi block lại có nhiều page. Khi nói về flash, bạn phải nhớ thuật ngữ mới này, vốn khác với block mà chúng ta đề cập trong ổ đĩa và RAID, và khác với page mà chúng ta nói đến trong virtual memory (bộ nhớ ảo).
Hình 44.1 cho thấy một ví dụ về flash plane với các block và page; trong ví dụ đơn giản này có ba block, mỗi block chứa bốn page. Chúng ta sẽ thấy bên dưới lý do tại sao cần phân biệt giữa block và page; hóa ra sự phân biệt này là rất quan trọng đối với các thao tác trên flash như đọc và ghi, và còn quan trọng hơn đối với hiệu năng tổng thể của thiết bị. Điều quan trọng (và kỳ lạ) nhất mà bạn sẽ học được là: để ghi vào một page trong một block, trước tiên bạn phải xóa toàn bộ block; chi tiết phức tạp này khiến việc xây dựng một SSD dựa trên flash trở thành một thách thức thú vị và đáng để nghiên cứu, và sẽ là nội dung của nửa sau chương này.
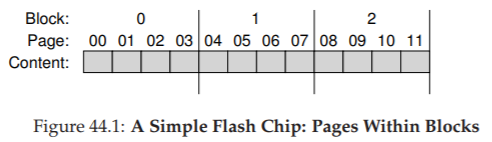
Hình 44.1: Một chip flash đơn giản: Các page bên trong block
44.3 Các thao tác cơ bản trên Flash (Basic Flash Operations)
Với cấu trúc tổ chức của flash như đã mô tả, có ba thao tác mức thấp (low-level operations) mà một chip flash hỗ trợ. Lệnh read được dùng để đọc một page từ flash; erase và program được sử dụng kết hợp để ghi dữ liệu. Chi tiết như sau:
-
Read (một page): Một client (thiết bị hoặc phần mềm sử dụng chip flash) có thể đọc bất kỳ page nào (ví dụ: 2KB hoặc 4KB) chỉ bằng cách gửi lệnh đọc và số hiệu page tương ứng tới thiết bị. Thao tác này thường rất nhanh, chỉ mất vài chục microsecond, bất kể vị trí trên thiết bị, và (gần như) không phụ thuộc vào vị trí của yêu cầu trước đó (khác hẳn với ổ đĩa từ). Khả năng truy cập nhanh đồng đều tới mọi vị trí có nghĩa là thiết bị này là một random access device (thiết bị truy cập ngẫu nhiên).
-
Erase (một block): Trước khi ghi vào một page trong flash, bản chất của thiết bị yêu cầu bạn phải xóa toàn bộ block chứa page đó. Lệnh erase, quan trọng là, sẽ xóa toàn bộ nội dung của block (bằng cách đặt mỗi bit về giá trị 1); do đó, bạn phải đảm bảo rằng mọi dữ liệu quan trọng trong block đã được sao chép sang nơi khác (ví dụ: bộ nhớ, hoặc một block flash khác) trước khi thực hiện lệnh erase. Lệnh erase khá tốn kém, mất vài millisecond để hoàn tất. Sau khi xóa xong, toàn bộ block được đặt lại trạng thái ban đầu và mỗi page trong đó sẵn sàng để được lập trình (program).
-
Program (một page): Sau khi một block đã được erase, lệnh program có thể được dùng để thay đổi một số bit 1 trong page thành bit 0, và ghi nội dung mong muốn của page vào flash. Việc program một page ít tốn kém hơn erase một block, nhưng tốn hơn đọc một page, thường mất khoảng vài trăm microsecond trên các chip flash hiện đại.
Một cách để hình dung về chip flash là: mỗi page có một trạng thái (state) gắn liền với nó. Các page bắt đầu ở trạng thái INVALID (không hợp lệ). Khi xóa block chứa page, bạn đặt trạng thái của page (và tất cả các page trong block đó) thành ERASED (đã xóa), điều này vừa đặt lại nội dung của mỗi page trong block, vừa (quan trọng) khiến chúng có thể được lập trình. Khi bạn program một page, trạng thái của nó chuyển sang VALID (hợp lệ), nghĩa là nội dung đã được thiết lập và có thể đọc. Các thao tác đọc không ảnh hưởng đến trạng thái này (mặc dù bạn chỉ nên đọc từ các page đã được program). Một khi một page đã được program, cách duy nhất để thay đổi nội dung của nó là xóa toàn bộ block chứa page đó.
Dưới đây là ví dụ về sự chuyển đổi trạng thái sau các thao tác erase và program khác nhau trong một block gồm 4 page:
...
Ví dụ chi tiết (A Detailed Example)
Bởi vì quá trình ghi (tức là erase và program) khá đặc biệt, hãy cùng đi qua một ví dụ chi tiết để đảm bảo bạn hiểu rõ. Trong ví dụ này, giả sử chúng ta có bốn page 8-bit, nằm trong một block gồm 4 page (cả hai kích thước này đều nhỏ hơn thực tế, nhưng hữu ích cho minh họa); mỗi page đang ở trạng thái VALID vì đã được program trước đó.
...
Bây giờ giả sử chúng ta muốn ghi vào page 0, điền vào đó nội dung mới. Để ghi vào bất kỳ page nào, chúng ta phải xóa toàn bộ block trước. Giả sử chúng ta thực hiện điều đó, để lại block ở trạng thái:
...
Tin tốt là: giờ chúng ta có thể program page 0, ví dụ với nội dung 00000011, ghi đè lên page 0 cũ (nội dung 00011000) như mong muốn. Sau khi thực hiện, block của chúng ta trông như sau:
...
Và đây là tin xấu: nội dung trước đó của các page 1, 2 và 3 đều đã mất! Do đó, trước khi ghi đè bất kỳ page nào trong một block, chúng ta phải di chuyển mọi dữ liệu quan trọng sang vị trí khác (ví dụ: bộ nhớ, hoặc một nơi khác trên flash). Bản chất của thao tác erase sẽ có ảnh hưởng mạnh mẽ đến cách chúng ta thiết kế các SSD dựa trên flash, như chúng ta sẽ tìm hiểu ngay sau đây.
Tóm tắt (Summary)
Tóm lại, việc đọc một page là đơn giản: chỉ cần đọc page đó. Các chip flash thực hiện thao tác này khá tốt và nhanh; xét về hiệu năng, chúng có tiềm năng vượt xa hiệu năng đọc ngẫu nhiên (random read) của các ổ đĩa từ hiện đại, vốn chậm do chi phí seek và quay cơ học.
Việc ghi một page thì phức tạp hơn; toàn bộ block phải được xóa trước (đảm bảo rằng mọi dữ liệu quan trọng đã được di chuyển sang vị trí khác), sau đó mới program (lập trình) page mong muốn. Điều này không chỉ tốn kém, mà việc lặp lại chu kỳ program/erase thường xuyên có thể dẫn đến vấn đề độ tin cậy lớn nhất của chip flash: wear out (hao mòn). Khi thiết kế một hệ thống lưu trữ sử dụng flash, hiệu năng và độ tin cậy của thao tác ghi là trọng tâm cần chú ý. Chúng ta sẽ sớm tìm hiểu cách các SSD hiện đại giải quyết những vấn đề này, mang lại hiệu năng và độ tin cậy cao bất chấp các giới hạn nói trên.
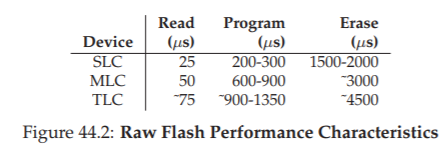
Hình 44.2: Đặc tính hiệu năng của flash thô (Raw Flash Performance Characteristics)
44.4 Hiệu năng và độ tin cậy của Flash (Flash Performance And Reliability)
Vì chúng ta quan tâm đến việc xây dựng một thiết bị lưu trữ từ các chip flash thô, nên việc hiểu các đặc tính hiệu năng cơ bản của chúng là cần thiết. Hình 44.2 trình bày tóm tắt một số số liệu được tìm thấy trên các nguồn báo chí phổ biến [V12]. Trong đó, tác giả đưa ra độ trễ (latency) của các thao tác cơ bản read, program, và erase trên các loại flash SLC, MLC và TLC, lần lượt lưu trữ 1, 2 và 3 bit thông tin trên mỗi cell.
Như ta có thể thấy từ bảng, độ trễ đọc (read latency) khá tốt, chỉ mất vài chục microsecond để hoàn tất. Độ trễ program cao hơn và biến thiên nhiều hơn: thấp nhất khoảng 200 microsecond đối với SLC, nhưng cao hơn khi lưu nhiều bit hơn trên mỗi cell; để đạt hiệu năng ghi tốt, bạn sẽ phải sử dụng nhiều chip flash song song. Cuối cùng, thao tác erase khá tốn kém, thường mất vài millisecond. Việc xử lý chi phí này là yếu tố trung tâm trong thiết kế lưu trữ flash hiện đại.
Bây giờ hãy xét đến độ tin cậy của chip flash. Khác với ổ đĩa cơ khí, vốn có thể hỏng vì nhiều nguyên nhân (bao gồm cả sự cố nghiêm trọng head crash, khi đầu đọc của ổ đĩa tiếp xúc trực tiếp với bề mặt ghi), chip flash được làm hoàn toàn từ silicon và do đó ít gặp vấn đề về độ tin cậy hơn. Mối quan tâm chính là wear out; khi một block flash bị erase và program, nó dần tích tụ một lượng điện tích dư. Theo thời gian, khi điện tích dư này tăng lên, việc phân biệt giữa bit 0 và bit 1 trở nên khó khăn hơn. Khi không thể phân biệt được nữa, block đó trở nên không sử dụng được.
Tuổi thọ điển hình của một block hiện chưa được biết rõ. Các nhà sản xuất đánh giá block dựa trên MLC có tuổi thọ khoảng 10.000 chu kỳ P/E (Program/Erase); tức là mỗi block có thể bị xóa và lập trình 10.000 lần trước khi hỏng. Chip SLC, vì chỉ lưu một bit trên mỗi transistor, được đánh giá có tuổi thọ dài hơn, thường khoảng 100.000 chu kỳ P/E. Tuy nhiên, các nghiên cứu gần đây cho thấy tuổi thọ thực tế có thể dài hơn nhiều so với dự đoán [BD10].
Một vấn đề độ tin cậy khác trong chip flash được gọi là disturbance (nhiễu). Khi truy cập một page cụ thể trong flash, có khả năng một số bit trong các page lân cận bị lật (bit flip); các bit flip này được gọi là read disturb hoặc program disturb, tùy thuộc vào việc page đang được đọc hay được lập trình.
TIP: TẦM QUAN TRỌNG CỦA KHẢ NĂNG TƯƠNG THÍCH NGƯỢC (BACKWARDS COMPATIBILITY)
Khả năng tương thích ngược luôn là một mối quan tâm trong các hệ thống phân lớp (layered systems). Bằng cách định nghĩa một giao diện ổn định giữa hai hệ thống, ta cho phép đổi mới ở mỗi phía của giao diện, đồng thời đảm bảo khả năng tương tác liên tục. Cách tiếp cận này đã rất thành công trong nhiều lĩnh vực: hệ điều hành (operating system) duy trì API tương đối ổn định cho ứng dụng, ổ đĩa cung cấp cùng một giao diện dựa trên block cho file system, và mỗi lớp trong ngăn xếp mạng IP (IP networking stack) cung cấp một giao diện cố định, không thay đổi cho lớp phía trên.
Không ngạc nhiên khi sự cứng nhắc này cũng có mặt trái: các giao diện được định nghĩa ở một thế hệ có thể không còn phù hợp ở thế hệ tiếp theo. Trong một số trường hợp, có thể hữu ích khi xem xét thiết kế lại toàn bộ hệ thống. Một ví dụ điển hình là file system ZFS của Sun [B07]; bằng cách xem xét lại cách file system và RAID tương tác, các nhà thiết kế ZFS đã hình dung (và hiện thực hóa) một hệ thống tích hợp hiệu quả hơn.
44.5 Từ Flash thô đến SSD dựa trên Flash (From Raw Flash to Flash-Based SSDs)
Với hiểu biết cơ bản về chip flash, chúng ta đối mặt với nhiệm vụ tiếp theo: làm thế nào để biến một tập hợp chip flash cơ bản thành một thiết bị lưu trữ giống như các thiết bị lưu trữ thông thường. Giao diện lưu trữ tiêu chuẩn là giao diện dựa trên block đơn giản, trong đó các block (sector) có kích thước 512 byte (hoặc lớn hơn) có thể được đọc hoặc ghi khi biết địa chỉ block. Nhiệm vụ của SSD dựa trên flash là cung cấp giao diện block tiêu chuẩn này trên nền các chip flash thô bên trong.
Bên trong, một SSD bao gồm một số chip flash (dùng cho lưu trữ bền vững – persistent storage). SSD cũng chứa một lượng bộ nhớ volatile (không bền vững, ví dụ: SRAM); loại bộ nhớ này hữu ích cho việc caching (lưu đệm) và buffering (đệm) dữ liệu, cũng như cho các bảng ánh xạ (mapping tables) mà chúng ta sẽ tìm hiểu bên dưới. Cuối cùng, SSD chứa control logic (mạch điều khiển) để điều phối hoạt động của thiết bị. Xem Agrawal và cộng sự [A+08] để biết chi tiết; Hình 44.3 minh họa sơ đồ khối logic đơn giản của một SSD dựa trên flash.
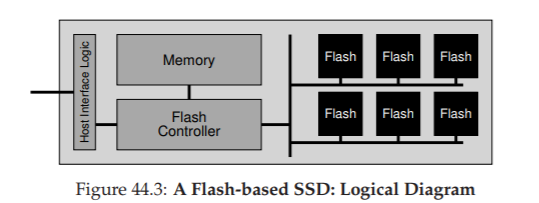
Hình 44.3: SSD dựa trên Flash – Sơ đồ logic
Một trong những chức năng thiết yếu của control logic là đáp ứng các yêu cầu đọc và ghi từ phía client, chuyển chúng thành các thao tác flash nội bộ khi cần. Flash Translation Layer (FTL – lớp dịch địa chỉ flash) cung cấp chính xác chức năng này. FTL nhận các yêu cầu đọc và ghi trên các logical block (khối logic – tạo thành giao diện thiết bị) và chuyển chúng thành các lệnh mức thấp read, erase, và program trên các physical block và physical page (tạo thành thiết bị flash vật lý thực tế). FTL phải thực hiện nhiệm vụ này với mục tiêu đạt hiệu năng cao và độ tin cậy cao.
Hiệu năng cao, như chúng ta sẽ thấy, có thể đạt được thông qua sự kết hợp của nhiều kỹ thuật. Một yếu tố then chốt là tận dụng nhiều chip flash song song; mặc dù chúng ta sẽ không bàn sâu về kỹ thuật này, nhưng có thể khẳng định rằng tất cả các SSD hiện đại đều sử dụng nhiều chip bên trong để đạt hiệu năng cao hơn. Một mục tiêu hiệu năng khác là giảm write amplification – được định nghĩa là tổng lưu lượng ghi (tính bằng byte) mà FTL gửi tới các chip flash chia cho tổng lưu lượng ghi (tính bằng byte) mà client gửi tới SSD. Như chúng ta sẽ thấy bên dưới, các cách tiếp cận FTL ngây thơ sẽ dẫn đến write amplification cao và hiệu năng thấp.
Độ tin cậy cao sẽ đạt được thông qua sự kết hợp của một số phương pháp khác nhau. Mối quan tâm chính, như đã thảo luận ở trên, là wear out (hao mòn). Nếu một block bị erase và program quá thường xuyên, nó sẽ trở nên không sử dụng được; do đó, FTL nên cố gắng phân tán các thao tác ghi đều trên các block của flash, đảm bảo rằng tất cả các block của thiết bị hao mòn gần như đồng thời; việc này được gọi là wear leveling và là một phần thiết yếu của bất kỳ FTL hiện đại nào.
Một mối quan tâm khác về độ tin cậy là program disturbance (nhiễu khi lập trình). Để giảm thiểu nhiễu này, FTL thường sẽ program các page trong một block đã erase theo thứ tự, từ page thấp đến page cao. Cách lập trình tuần tự này giúp giảm thiểu nhiễu và được sử dụng rộng rãi.
44.6 Tổ chức FTL: Một cách tiếp cận tệ (FTL Organization: A Bad Approach)
Cách tổ chức đơn giản nhất của một FTL (Flash Translation Layer – lớp dịch địa chỉ flash) là phương pháp mà chúng ta gọi là direct mapped (ánh xạ trực tiếp). Trong cách tiếp cận này, một thao tác đọc tới logical page N (trang logic N) sẽ được ánh xạ trực tiếp thành thao tác đọc physical page N (trang vật lý N). Một thao tác ghi tới logical page N thì phức tạp hơn; FTL trước tiên phải đọc toàn bộ block chứa page N; sau đó phải erase (xóa) block đó; cuối cùng, FTL program (lập trình) lại các page cũ cũng như page mới.
Như bạn có thể đoán, FTL kiểu direct-mapped có nhiều vấn đề, cả về hiệu năng lẫn độ tin cậy. Vấn đề hiệu năng xuất hiện ở mỗi lần ghi: thiết bị phải đọc toàn bộ block (tốn kém), xóa block (rất tốn kém), rồi program lại (tốn kém). Kết quả cuối cùng là write amplification (khuếch đại ghi) nghiêm trọng (tỷ lệ thuận với số lượng page trong một block) và do đó hiệu năng ghi rất tệ, thậm chí còn chậm hơn cả ổ cứng thông thường với các thao tác seek và quay cơ học.
Tệ hơn nữa là độ tin cậy của cách tiếp cận này. Nếu metadata của file system hoặc dữ liệu file của người dùng bị ghi đè nhiều lần, cùng một block sẽ bị erase và program lặp đi lặp lại, nhanh chóng làm nó bị mòn (wear out) và có thể gây mất dữ liệu. Cách tiếp cận direct-mapped đơn giản là trao quá nhiều quyền kiểm soát việc hao mòn cho workload (tải công việc) của client; nếu workload không phân bổ đều tải ghi trên các logical block, các physical block chứa dữ liệu được truy cập thường xuyên sẽ nhanh chóng bị mòn. Vì cả lý do độ tin cậy lẫn hiệu năng, một FTL kiểu direct-mapped là một ý tưởng tồi.
44.7 FTL kiểu Log-Structured (A Log-Structured FTL)
Vì những lý do trên, hầu hết các FTL ngày nay đều được thiết kế theo kiểu log-structured (cấu trúc nhật ký), một ý tưởng hữu ích cả trong thiết bị lưu trữ (như chúng ta sẽ thấy ngay sau đây) và trong các file system phía trên (ví dụ: log-structured file system). Khi ghi vào logical block N, thiết bị sẽ append (nối thêm) dữ liệu ghi vào vị trí trống tiếp theo trong block đang được ghi; chúng ta gọi kiểu ghi này là logging. Để cho phép đọc lại block N sau này, thiết bị duy trì một mapping table (bảng ánh xạ) trong bộ nhớ (và được lưu bền vững ở một dạng nào đó trên thiết bị); bảng này lưu địa chỉ vật lý của mỗi logical block trong hệ thống.
Hãy cùng đi qua một ví dụ để đảm bảo chúng ta hiểu cách tiếp cận log-based cơ bản hoạt động. Đối với client, thiết bị trông giống như một ổ đĩa thông thường, có thể đọc và ghi các sector 512 byte (hoặc nhóm sector). Để đơn giản, giả sử client đọc hoặc ghi các khối dữ liệu kích thước 4 KB. Giả sử thêm rằng SSD chứa một số lượng lớn các block kích thước 16 KB, mỗi block được chia thành bốn page 4 KB; các thông số này là không thực tế (block flash thường gồm nhiều page hơn) nhưng sẽ phục vụ tốt cho mục đích minh họa.
Giả sử client thực hiện chuỗi thao tác sau:
Write(100)với nội dung a1Write(101)với nội dung a2Write(2000)với nội dung b1Write(2001)với nội dung b2
Các logical block address (địa chỉ block logic, ví dụ: 100) được client của SSD (ví dụ: một file system) sử dụng để ghi nhớ vị trí lưu trữ thông tin. Bên trong, thiết bị phải chuyển đổi các thao tác ghi block này thành các thao tác erase và program được phần cứng flash hỗ trợ, và bằng cách nào đó ghi nhận, cho mỗi logical block address, physical page nào của SSD đang lưu dữ liệu của nó. Giả sử tất cả các block của SSD hiện đều INVALID (không hợp lệ) và phải được erase trước khi bất kỳ page nào có thể được program. Dưới đây là trạng thái ban đầu của SSD, với tất cả các page được đánh dấu INVALID (i):
...
Khi thao tác ghi đầu tiên được gửi tới SSD (tới logical block 100), FTL quyết định ghi nó vào physical block 0, block này chứa bốn physical page: 0, 1, 2 và 3. Vì block chưa được erase, chúng ta chưa thể ghi vào; thiết bị trước tiên phải gửi lệnh erase tới block 0. Thao tác này dẫn đến trạng thái sau:
...
Block 0 giờ đã sẵn sàng để được program. Hầu hết các SSD sẽ ghi các page theo thứ tự (tức là từ page thấp đến page cao), giúp giảm các vấn đề về độ tin cậy liên quan đến program disturbance (nhiễu khi lập trình). SSD sau đó sẽ ghi logical block 100 vào physical page 0:
...
Bây giờ bạn có thể thấy điều gì xảy ra khi client ghi vào SSD. SSD tìm một vị trí cho thao tác ghi, thường là chọn page trống tiếp theo; sau đó nó program page đó với nội dung của block, và ghi nhận ánh xạ logical-to-physical (từ logic sang vật lý) trong bảng ánh xạ. Các thao tác đọc sau đó chỉ cần sử dụng bảng này để dịch logical block address mà client đưa ra thành số physical page cần đọc dữ liệu.
Hãy tiếp tục xem xét các thao tác ghi còn lại trong chuỗi ví dụ: 101, 2000 và 2001. Sau khi ghi các block này, trạng thái của thiết bị là:
...
Cách tiếp cận log-based, theo bản chất của nó, cải thiện hiệu năng (erase chỉ cần thực hiện thỉnh thoảng, và tránh hoàn toàn thao tác read-modify-write tốn kém của phương pháp direct-mapped), đồng thời nâng cao đáng kể độ tin cậy. FTL giờ đây có thể phân bổ các thao tác ghi trên tất cả các page, thực hiện cái gọi là wear leveling và kéo dài tuổi thọ của thiết bị; chúng ta sẽ thảo luận thêm về wear leveling ở phần sau.
ASIDE: TÍNH BỀN VỮNG CỦA THÔNG TIN ÁNH XẠ FTL (FTL MAPPING INFORMATION PERSISTENCE)
Bạn có thể tự hỏi: điều gì xảy ra nếu thiết bị bị mất điện? Liệu bảng ánh xạ trong bộ nhớ (in-memory mapping table) có biến mất không? Rõ ràng, thông tin này không thể bị mất hoàn toàn, vì nếu vậy thiết bị sẽ không thể hoạt động như một thiết bị lưu trữ bền vững (persistent storage device). Một SSD phải có cơ chế để khôi phục thông tin ánh xạ.Cách đơn giản nhất là ghi kèm một số thông tin ánh xạ với mỗi page, trong vùng gọi là out-of-band (OOB) area. Khi thiết bị mất điện và được khởi động lại, nó phải tái tạo bảng ánh xạ bằng cách quét các vùng OOB và dựng lại bảng ánh xạ trong bộ nhớ. Cách tiếp cận cơ bản này có một số vấn đề; việc quét một SSD dung lượng lớn để tìm toàn bộ thông tin ánh xạ cần thiết là chậm. Để khắc phục hạn chế này, một số thiết bị cao cấp hơn sử dụng các kỹ thuật logging (ghi nhật ký) và checkpointing (tạo điểm kiểm) phức tạp hơn để tăng tốc quá trình khôi phục; bạn có thể tìm hiểu thêm về logging trong các chương nói về crash consistency và log-structured file system [AD14a].
Thật không may, cách tiếp cận log structuring cơ bản này có một số nhược điểm. Thứ nhất, việc ghi đè (overwrite) các logical block dẫn đến hiện tượng mà chúng ta gọi là garbage (rác), tức là các phiên bản dữ liệu cũ nằm rải rác trên ổ và chiếm dung lượng. Thiết bị phải định kỳ thực hiện garbage collection (GC) để tìm các block này và giải phóng không gian cho các lần ghi trong tương lai; việc garbage collection quá mức sẽ làm tăng write amplification và giảm hiệu năng. Thứ hai là chi phí cao của bảng ánh xạ trong bộ nhớ; thiết bị càng lớn thì bảng này càng cần nhiều bộ nhớ. Chúng ta sẽ lần lượt thảo luận từng vấn đề.
44.8 Garbage Collection
Chi phí đầu tiên của bất kỳ cách tiếp cận log-structured nào như thế này là việc tạo ra garbage, và do đó phải thực hiện garbage collection (tức là thu hồi các block chết – dead-block reclamation). Hãy tiếp tục sử dụng ví dụ trước để hiểu rõ hơn. Nhớ lại rằng các logical block 100, 101, 2000 và 2001 đã được ghi vào thiết bị.
Bây giờ, giả sử các block 100 và 101 được ghi lại, với nội dung c1 và c2. Các thao tác ghi này được ghi vào các page trống tiếp theo (trong trường hợp này là physical page 4 và 5), và bảng ánh xạ được cập nhật tương ứng. Lưu ý rằng thiết bị phải erase block 1 trước để có thể thực hiện thao tác program này:
...
Vấn đề bây giờ đã rõ: physical page 0 và 1, mặc dù được đánh dấu VALID, thực chất chứa garbage, tức là các phiên bản cũ của block 100 và 101. Do bản chất log-structured của thiết bị, các thao tác overwrite tạo ra các block rác, và thiết bị phải thu hồi chúng để cung cấp không gian trống cho các lần ghi mới.
Quá trình tìm các block rác (còn gọi là dead block) và thu hồi chúng để sử dụng trong tương lai được gọi là garbage collection, và đây là một thành phần quan trọng của bất kỳ SSD hiện đại nào. Quy trình cơ bản rất đơn giản: tìm một block chứa một hoặc nhiều page rác, đọc các page live (không phải rác) từ block đó, ghi các page live này vào log, và (cuối cùng) thu hồi toàn bộ block để sử dụng cho việc ghi.
Hãy minh họa bằng một ví dụ. Thiết bị quyết định thu hồi các page chết trong block 0 ở trên. Block 0 có hai page chết (page 0 và 1) và hai page live (page 2 và 3, lần lượt chứa block 2000 và 2001). Để làm điều này, thiết bị sẽ:
- Đọc dữ liệu live (page 2 và 3) từ block 0
- Ghi dữ liệu live vào cuối log
- Erase block 0 (giải phóng nó để sử dụng sau này)
Để garbage collector hoạt động, trong mỗi block phải có đủ thông tin để SSD xác định được mỗi page là live hay dead. Một cách tự nhiên để đạt được điều này là lưu, tại một vị trí nào đó trong mỗi block, thông tin về logical block nào được lưu trong mỗi page. Thiết bị sau đó có thể sử dụng bảng ánh xạ để xác định liệu mỗi page trong block có chứa dữ liệu live hay không.
Từ ví dụ trên (trước khi garbage collection diễn ra), block 0 chứa các logical block 100, 101, 2000, 2001. Bằng cách kiểm tra bảng ánh xạ (trước khi garbage collection, bảng này chứa 100→4, 101→5, 2000→2, 2001→3), thiết bị có thể dễ dàng xác định page nào trong block SSD chứa thông tin live. Ví dụ, page 2 và 3 rõ ràng vẫn được trỏ tới trong bảng ánh xạ; page 0 và 1 thì không, và do đó là ứng viên cho garbage collection.
Khi quá trình garbage collection này hoàn tất trong ví dụ của chúng ta, trạng thái của thiết bị sẽ là:
...
Như bạn có thể thấy, garbage collection (GC) có thể rất tốn kém, vì yêu cầu phải đọc và ghi lại dữ liệu live (dữ liệu còn sử dụng). Ứng viên lý tưởng để thu hồi là một block chỉ chứa toàn dead page (trang chết); trong trường hợp này, block có thể được erase (xóa) ngay lập tức và dùng cho dữ liệu mới, mà không cần thực hiện di chuyển dữ liệu tốn kém.
ASIDE: MỘT API LƯU TRỮ MỚI GỌI LÀ TRIM
Khi nghĩ về ổ cứng (hard drive), chúng ta thường chỉ nghĩ đến giao diện cơ bản nhất để đọc và ghi: read và write (thường cũng có một lệnh cache flush để đảm bảo dữ liệu ghi đã thực sự được lưu bền vững, nhưng đôi khi chúng ta bỏ qua để đơn giản hóa). Với log-structured SSD, và thực tế là bất kỳ thiết bị nào duy trì ánh xạ logical-to-physical block (từ block logic sang block vật lý) một cách linh hoạt và thay đổi, một giao diện mới trở nên hữu ích, được gọi là thao táctrim.Thao tác
trimnhận vào một địa chỉ (và có thể là một độ dài), và đơn giản là thông báo cho thiết bị rằng block (hoặc các block) được chỉ định bởi địa chỉ (và độ dài) đã bị xóa; thiết bị do đó không còn phải theo dõi bất kỳ thông tin nào về vùng địa chỉ này nữa. Đối với ổ cứng thông thường,trimkhông đặc biệt hữu ích, vì ổ đĩa có ánh xạ tĩnh từ địa chỉ block tới platter, track và sector cụ thể. Tuy nhiên, đối với log-structured SSD, việc biết rằng một block không còn cần thiết là rất hữu ích, vì SSD có thể xóa thông tin này khỏi FTL và sau đó thu hồi không gian vật lý trong quá trình garbage collection.Mặc dù đôi khi chúng ta nghĩ giao diện (interface) và hiện thực (implementation) là hai thực thể tách biệt, nhưng trong trường hợp này, chúng ta thấy rằng hiện thực đã định hình giao diện. Với các ánh xạ phức tạp, việc biết block nào không còn cần thiết sẽ giúp hiện thực hiệu quả hơn.
Để giảm chi phí GC, một số SSD overprovision (dự phòng dư) [A+08]; bằng cách thêm dung lượng flash bổ sung, việc dọn dẹp có thể được trì hoãn và thực hiện ở chế độ nền, có thể vào thời điểm thiết bị ít bận rộn hơn. Việc thêm dung lượng cũng làm tăng băng thông nội bộ (internal bandwidth), có thể được sử dụng cho việc dọn dẹp và do đó không làm giảm băng thông mà client cảm nhận. Nhiều ổ đĩa hiện đại overprovision theo cách này, đây là một yếu tố quan trọng để đạt hiệu năng tổng thể xuất sắc.
44.9 Kích thước bảng ánh xạ (Mapping Table Size)
Chi phí thứ hai của log-structuring là khả năng bảng ánh xạ trở nên cực kỳ lớn, với một mục (entry) cho mỗi page 4 KB của thiết bị. Ví dụ, với một SSD 1 TB, chỉ cần một entry 4 byte cho mỗi page 4 KB đã dẫn đến 1 GB bộ nhớ cần thiết chỉ để lưu các ánh xạ này! Do đó, sơ đồ FTL ở mức page (page-level FTL) là không khả thi.
Block-Based Mapping (Ánh xạ theo block)
Một cách tiếp cận để giảm chi phí ánh xạ là chỉ giữ một con trỏ cho mỗi block của thiết bị, thay vì cho mỗi page, từ đó giảm lượng thông tin ánh xạ theo tỷ lệ:
[ \frac{\text{block size}}{\text{page size}} ]
FTL ở mức block này tương tự như việc sử dụng kích thước page lớn hơn trong hệ thống virtual memory (bộ nhớ ảo); khi đó, bạn dùng ít bit hơn cho VPN (Virtual Page Number – số trang ảo) và có phần offset lớn hơn trong mỗi địa chỉ ảo.
Tuy nhiên, việc sử dụng block-based mapping bên trong một log-based FTL lại không hoạt động tốt về mặt hiệu năng. Vấn đề lớn nhất xuất hiện khi có một small write (ghi nhỏ) – tức là một thao tác ghi nhỏ hơn kích thước của một block vật lý. Trong trường hợp này, FTL phải đọc một lượng lớn dữ liệu live từ block cũ và sao chép nó sang block mới (cùng với dữ liệu từ thao tác ghi nhỏ). Việc sao chép dữ liệu này làm tăng write amplification đáng kể và do đó làm giảm hiệu năng.
Để làm rõ vấn đề này, hãy xem một ví dụ. Giả sử client trước đó đã ghi các logical block 2000, 2001, 2002 và 2003 (với nội dung a, b, c, d), và chúng được lưu trong physical block 1 tại các physical page 4, 5, 6 và 7. Với ánh xạ theo page (per-page mapping), bảng dịch sẽ phải ghi nhận bốn ánh xạ cho các logical block này:
2000 → 4, 2001 → 5, 2002 → 6, 2003 → 7.
Nếu thay vào đó, chúng ta sử dụng block-level mapping, FTL chỉ cần ghi nhận một ánh xạ địa chỉ cho toàn bộ dữ liệu này. Tuy nhiên, ánh xạ địa chỉ sẽ hơi khác so với các ví dụ trước. Cụ thể, chúng ta coi không gian địa chỉ logic của thiết bị được chia thành các chunk có kích thước bằng các block vật lý trong flash. Do đó, logical block address sẽ bao gồm hai phần: chunk number (số thứ tự chunk) và offset (độ lệch). Vì giả sử có bốn logical block nằm trong mỗi physical block, phần offset của địa chỉ logic cần 2 bit; các bit còn lại (bit có trọng số cao hơn) tạo thành chunk number.
Các logical block 2000, 2001, 2002 và 2003 đều có cùng chunk number (500), và có các offset khác nhau (0, 1, 2 và 3, tương ứng). Do đó, với block-level mapping, FTL ghi nhận rằng chunk 500 ánh xạ tới block 1 (bắt đầu tại physical page 4), như minh họa trong sơ đồ sau:
...
Trong một block-based FTL (FTL ánh xạ theo block), thao tác đọc là khá đơn giản. Trước tiên, FTL trích xuất chunk number (số thứ tự chunk) từ logical block address (địa chỉ block logic) mà client gửi đến, bằng cách lấy các bit cao nhất của địa chỉ. Sau đó, FTL tra cứu ánh xạ từ chunk number sang physical page (trang vật lý) trong bảng ánh xạ. Cuối cùng, FTL tính toán địa chỉ của flash page cần đọc bằng cách cộng offset (độ lệch) từ địa chỉ logic vào địa chỉ vật lý của block.
Ví dụ, nếu client gửi yêu cầu đọc tới địa chỉ logic 2002, thiết bị sẽ trích xuất chunk number logic (500), tra cứu bảng ánh xạ (tìm được giá trị 4), và cộng offset từ địa chỉ logic (2) vào giá trị ánh xạ (4). Kết quả là địa chỉ physical page (6) – nơi dữ liệu được lưu; FTL sau đó có thể phát lệnh đọc tới địa chỉ vật lý này và lấy về dữ liệu mong muốn (c).
Nhưng nếu client ghi vào logical block 2002 (với nội dung c’) thì sao? Trong trường hợp này, FTL phải đọc các block 2000, 2001 và 2003, sau đó ghi lại cả bốn logical block này vào một vị trí mới, đồng thời cập nhật bảng ánh xạ. Block 1 (nơi dữ liệu từng được lưu) sau đó có thể được erase và tái sử dụng, như minh họa dưới đây.
...
Như bạn có thể thấy từ ví dụ này, mặc dù ánh xạ ở mức block giúp giảm đáng kể lượng bộ nhớ cần cho việc dịch địa chỉ, nhưng nó lại gây ra các vấn đề hiệu năng nghiêm trọng khi các thao tác ghi nhỏ hơn kích thước block vật lý của thiết bị; vì các block vật lý thực tế có thể lớn tới 256KB hoặc hơn, nên các thao tác ghi nhỏ như vậy rất dễ xảy ra thường xuyên. Do đó, cần có một giải pháp tốt hơn. Bạn có cảm nhận được đây là đoạn trong chương mà chúng tôi sẽ tiết lộ giải pháp đó không? Hoặc tốt hơn, bạn có thể tự tìm ra trước khi đọc tiếp?
Hybrid Mapping (Ánh xạ lai)
Để cho phép ghi linh hoạt nhưng vẫn giảm chi phí ánh xạ, nhiều FTL hiện đại áp dụng kỹ thuật hybrid mapping (ánh xạ lai). Với cách tiếp cận này, FTL giữ sẵn một vài block đã được erase và hướng tất cả các thao tác ghi vào đó; các block này được gọi là log block. Vì FTL muốn có khả năng ghi bất kỳ page nào vào bất kỳ vị trí nào trong log block mà không cần thực hiện toàn bộ thao tác sao chép dữ liệu như trong ánh xạ thuần block-based, nó sẽ duy trì ánh xạ ở mức page cho các log block này.
Do đó, về mặt logic, FTL có hai loại bảng ánh xạ trong bộ nhớ:
- Một tập nhỏ các ánh xạ theo page trong bảng gọi là log table
- Một tập lớn hơn các ánh xạ theo block trong bảng gọi là data table
Khi tìm kiếm một logical block cụ thể, FTL sẽ tra cứu log table trước; nếu không tìm thấy vị trí của logical block trong đó, FTL sẽ tra cứu data table để tìm vị trí và sau đó truy cập dữ liệu được yêu cầu.
Yếu tố then chốt của chiến lược hybrid mapping là giữ số lượng log block ở mức nhỏ. Để làm được điều này, FTL phải định kỳ kiểm tra các log block (vốn có con trỏ cho từng page) và chuyển chúng thành các block có thể được trỏ tới chỉ bằng một con trỏ block duy nhất. Việc chuyển đổi này được thực hiện bằng một trong ba kỹ thuật chính, dựa trên nội dung của block [KK+02].
Ví dụ, giả sử FTL trước đó đã ghi các logical page 1000, 1001, 1002 và 1003, và đặt chúng vào physical block 2 (các physical page 8, 9, 10, 11); giả sử nội dung ghi vào 1000, 1001, 1002 và 1003 lần lượt là a, b, c và d.
...
Bây giờ giả sử client ghi đè từng block này (với dữ liệu a’, b’, c’ và d’), theo đúng thứ tự như trước, vào một trong các log block hiện có, giả sử là physical block 0 (các physical page 0, 1, 2, 3). Trong trường hợp này, FTL sẽ có trạng thái như sau:
...
Vì các block này đã được ghi chính xác theo cùng một cách như trước, FTL có thể thực hiện kỹ thuật gọi là switch merge. Trong trường hợp này, log block (0) giờ trở thành nơi lưu trữ cho các block 0, 1, 2 và 3, và được trỏ tới bởi một con trỏ block duy nhất; block cũ (2) sẽ được erase và sử dụng làm log block. Trong kịch bản tốt nhất này, tất cả các con trỏ theo page cần thiết được thay thế bằng một con trỏ block duy nhất.
...
Trường hợp switch merge là tình huống tốt nhất đối với một hybrid FTL (FTL lai). Thật không may, đôi khi FTL không gặp may như vậy. Hãy tưởng tượng trường hợp chúng ta có cùng điều kiện ban đầu (các logical block 1000 … 1003 được lưu trong physical block 2) nhưng sau đó client ghi đè lên logical block 1000 và 1001. Bạn nghĩ điều gì sẽ xảy ra trong trường hợp này? Tại sao việc xử lý lại khó khăn hơn? (hãy suy nghĩ trước khi xem kết quả ở trang tiếp theo)
...
Để hợp nhất các page còn lại của physical block này, và do đó có thể tham chiếu đến chúng chỉ bằng một block pointer duy nhất, FTL thực hiện thao tác gọi là partial merge (hợp nhất một phần). Trong thao tác này, các logical block 1002 và 1003 được đọc từ physical block 2, sau đó được append (nối thêm) vào log. Trạng thái cuối cùng của SSD giống như trong trường hợp switch merge ở trên; tuy nhiên, trong trường hợp này, FTL phải thực hiện thêm các thao tác I/O để đạt được mục tiêu, do đó làm tăng write amplification (khuếch đại ghi).
Trường hợp cuối cùng mà FTL gặp phải được gọi là full merge (hợp nhất toàn phần), và yêu cầu nhiều công việc hơn nữa. Trong trường hợp này, FTL phải tập hợp các page từ nhiều block khác nhau để thực hiện cleaning (dọn dẹp). Ví dụ, hãy tưởng tượng rằng các logical block 0, 4, 8 và 12 được ghi vào log block A. Để chuyển log block này thành một block được ánh xạ theo block (block-mapped), FTL trước tiên phải tạo ra một data block chứa các logical block 0, 1, 2 và 3, do đó FTL phải đọc 1, 2 và 3 từ nơi khác rồi ghi lại 0, 1, 2 và 3 cùng nhau. Tiếp theo, quá trình merge phải thực hiện tương tự cho logical block 4, tìm 5, 6 và 7 và hợp nhất chúng thành một physical block duy nhất. Điều tương tự phải được thực hiện cho logical block 8 và 12, và sau đó (cuối cùng), log block A mới có thể được giải phóng. Việc full merge xảy ra thường xuyên, như không có gì ngạc nhiên, có thể gây hại nghiêm trọng cho hiệu năng và do đó nên tránh bất cứ khi nào có thể [GY+09].
Page Mapping Plus Caching (Ánh xạ theo page kết hợp bộ nhớ đệm)
Với sự phức tạp của phương pháp hybrid ở trên, một số người đã đề xuất những cách đơn giản hơn để giảm tải bộ nhớ của các FTL ánh xạ theo page (page-mapped FTL). Có lẽ cách đơn giản nhất là chỉ lưu trong bộ nhớ các phần active (đang hoạt động) của FTL, từ đó giảm lượng bộ nhớ cần thiết [GY+09].
Cách tiếp cận này có thể hoạt động tốt. Ví dụ, nếu một workload nhất định chỉ truy cập một tập nhỏ các page, các ánh xạ của những page này sẽ được lưu trong FTL trong bộ nhớ, và hiệu năng sẽ rất tốt mà không tốn nhiều bộ nhớ. Tất nhiên, cách tiếp cận này cũng có thể hoạt động kém. Nếu bộ nhớ không thể chứa working set (tập làm việc) của các ánh xạ cần thiết, mỗi lần truy cập sẽ tối thiểu yêu cầu một lần đọc flash bổ sung để nạp ánh xạ bị thiếu trước khi có thể truy cập dữ liệu. Tệ hơn nữa, để tạo chỗ cho ánh xạ mới, FTL có thể phải evict (loại bỏ) một ánh xạ cũ, và nếu ánh xạ đó là dirty (tức là chưa được ghi bền vững xuống flash), sẽ phát sinh thêm một lần ghi. Tuy nhiên, trong nhiều trường hợp, workload sẽ thể hiện tính locality (tính cục bộ), và cách tiếp cận caching này vừa giảm chi phí bộ nhớ vừa duy trì hiệu năng cao.
44.10 Wear Leveling (Cân bằng hao mòn)
Cuối cùng, một hoạt động nền liên quan mà các FTL hiện đại phải triển khai là wear leveling (cân bằng hao mòn), như đã giới thiệu ở trên. Ý tưởng cơ bản rất đơn giản: vì nhiều chu kỳ erase/program sẽ làm mòn một flash block, FTL nên cố gắng phân bổ đều công việc này trên tất cả các block của thiết bị. Bằng cách này, tất cả các block sẽ bị mòn gần như cùng lúc, thay vì chỉ một vài block “phổ biến” nhanh chóng trở nên không sử dụng được.
Cách tiếp cận log-structuring cơ bản thực hiện khá tốt việc phân bổ tải ghi ban đầu, và garbage collection cũng giúp ích. Tuy nhiên, đôi khi một block sẽ chứa dữ liệu sống lâu dài (long-lived data) mà không bị ghi đè; trong trường hợp này, garbage collection sẽ không bao giờ thu hồi block đó, và do đó nó không nhận được phần tải ghi công bằng.
Để khắc phục vấn đề này, FTL phải định kỳ đọc toàn bộ dữ liệu live từ các block như vậy và ghi lại chúng ở nơi khác, từ đó làm cho block sẵn sàng để ghi mới. Quá trình wear leveling này làm tăng write amplification của SSD, và do đó giảm hiệu năng vì cần thêm I/O để đảm bảo tất cả các block bị mòn ở tốc độ gần như nhau. Có nhiều thuật toán khác nhau đã được công bố trong tài liệu [A+08, M+14]; bạn có thể tìm hiểu thêm nếu quan tâm.
44.11 Hiệu năng và chi phí của SSD (SSD Performance And Cost)
Trước khi kết thúc, hãy xem xét hiệu năng và chi phí của các SSD hiện đại, để hiểu rõ hơn cách chúng có thể được sử dụng trong các hệ thống lưu trữ bền vững (persistent storage systems). Trong cả hai khía cạnh này, chúng ta sẽ so sánh với ổ đĩa cứng truyền thống (HDD – Hard Disk Drive) và làm nổi bật những khác biệt lớn nhất giữa chúng.
Hiệu năng (Performance)
Không giống như ổ đĩa cứng, SSD dựa trên flash không có thành phần cơ khí, và trên thực tế, ở nhiều khía cạnh chúng giống DRAM hơn, vì chúng là các thiết bị random access (truy cập ngẫu nhiên). Sự khác biệt lớn nhất về hiệu năng, so với ổ đĩa cứng, thể hiện rõ khi thực hiện các thao tác đọc và ghi ngẫu nhiên; trong khi một ổ đĩa cứng thông thường chỉ có thể thực hiện vài trăm I/O ngẫu nhiên mỗi giây, SSD có thể làm tốt hơn nhiều. Ở đây, chúng ta sử dụng một số dữ liệu từ các SSD hiện đại để thấy SSD thực sự nhanh hơn bao nhiêu; chúng ta đặc biệt quan tâm đến việc FTL (Flash Translation Layer – lớp dịch địa chỉ flash) che giấu các vấn đề hiệu năng của chip flash thô tốt đến mức nào.
Bảng 44.4 cho thấy một số dữ liệu hiệu năng của ba SSD khác nhau và một ổ đĩa cứng cao cấp; dữ liệu được lấy từ một số nguồn trực tuyến [S13, T15]. Hai cột bên trái thể hiện hiệu năng I/O ngẫu nhiên, và hai cột bên phải thể hiện hiệu năng tuần tự; ba hàng đầu tiên là dữ liệu của ba SSD khác nhau (từ Samsung, Seagate và Intel), và hàng cuối cùng là hiệu năng của một ổ đĩa cứng (HDD), trong trường hợp này là một ổ Seagate cao cấp.
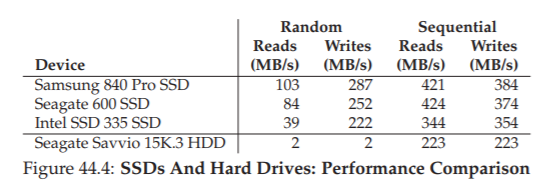
Hình 44.4: So sánh hiệu năng giữa SSD và HDD (SSDs And Hard Drives: Performance Comparison)
Từ bảng này, chúng ta có thể rút ra một số điểm thú vị.
Thứ nhất, và rõ ràng nhất, là sự khác biệt về hiệu năng I/O ngẫu nhiên giữa SSD và ổ đĩa cứng duy nhất trong bảng. Trong khi SSD đạt hàng chục hoặc thậm chí hàng trăm MB/s trong các thao tác I/O ngẫu nhiên, thì ổ đĩa cứng “hiệu năng cao” này chỉ đạt tối đa khoảng vài MB/s (thực tế, chúng tôi đã làm tròn lên để được 2 MB/s).
Thứ hai, bạn có thể thấy rằng về hiệu năng tuần tự, sự khác biệt ít hơn nhiều; mặc dù SSD vẫn nhanh hơn, nhưng ổ đĩa cứng vẫn là lựa chọn tốt nếu tất cả những gì bạn cần là hiệu năng tuần tự.
Thứ ba, bạn có thể thấy rằng hiệu năng đọc ngẫu nhiên của SSD không tốt bằng hiệu năng ghi ngẫu nhiên. Lý do cho hiệu năng ghi ngẫu nhiên tốt một cách bất ngờ này là nhờ thiết kế log-structured (cấu trúc nhật ký) của nhiều SSD, biến các thao tác ghi ngẫu nhiên thành ghi tuần tự và cải thiện hiệu năng.
Cuối cùng, vì SSD vẫn thể hiện sự khác biệt nhất định giữa I/O tuần tự và I/O ngẫu nhiên, nhiều kỹ thuật trong các chương về cách xây dựng file system cho ổ đĩa cứng vẫn áp dụng được cho SSD [AD14b]; mặc dù mức độ chênh lệch giữa I/O tuần tự và I/O ngẫu nhiên nhỏ hơn, nhưng khoảng cách này vẫn đủ để cân nhắc kỹ lưỡng khi thiết kế file system nhằm giảm I/O ngẫu nhiên.
Chi phí (Cost)
Như chúng ta đã thấy ở trên, hiệu năng của SSD vượt xa ổ đĩa cứng hiện đại, ngay cả khi thực hiện I/O tuần tự. Vậy tại sao SSD chưa hoàn toàn thay thế ổ đĩa cứng như là phương tiện lưu trữ phổ biến? Câu trả lời rất đơn giản: chi phí, hay cụ thể hơn là chi phí trên mỗi đơn vị dung lượng.
Hiện tại [A15], một SSD có giá khoảng 150 USD cho dung lượng 250 GB; tức là khoảng 0,60 USD cho mỗi GB. Một ổ đĩa cứng thông thường có giá khoảng 50 USD cho dung lượng 1 TB, tức là khoảng 0,05 USD cho mỗi GB. Như vậy, vẫn tồn tại sự chênh lệch hơn 10 lần về chi phí giữa hai loại phương tiện lưu trữ này.
Sự khác biệt về hiệu năng và chi phí này quyết định cách các hệ thống lưu trữ quy mô lớn được xây dựng. Nếu hiệu năng là mối quan tâm chính, SSD là lựa chọn tuyệt vời, đặc biệt nếu hiệu năng đọc ngẫu nhiên là quan trọng. Ngược lại, nếu bạn đang xây dựng một trung tâm dữ liệu lớn và muốn lưu trữ khối lượng thông tin khổng lồ, sự chênh lệch chi phí lớn sẽ khiến bạn nghiêng về ổ đĩa cứng.
Tất nhiên, một cách tiếp cận lai (hybrid) có thể hợp lý – một số hệ thống lưu trữ hiện nay được xây dựng với cả SSD và ổ đĩa cứng, sử dụng một số lượng nhỏ SSD cho dữ liệu “nóng” (hot data) được truy cập thường xuyên để đạt hiệu năng cao, trong khi lưu trữ phần dữ liệu “lạnh” (cold data) ít được sử dụng hơn trên ổ đĩa cứng để tiết kiệm chi phí. Chừng nào khoảng cách về giá vẫn tồn tại, ổ đĩa cứng vẫn sẽ tiếp tục được sử dụng.
44.12 Tóm tắt (Summary)
Các SSD (Solid-State Drive – ổ lưu trữ thể rắn) dựa trên flash đang trở nên phổ biến trong laptop, desktop và cả các máy chủ bên trong các trung tâm dữ liệu (datacenter) – nơi vận hành nền kinh tế toàn cầu. Vì vậy, bạn nên biết đôi điều về chúng, đúng không?
Tin không vui là: chương này (giống như nhiều chương khác trong cuốn sách này) chỉ là bước khởi đầu để hiểu về công nghệ tiên tiến hiện nay. Một số nguồn để tìm hiểu thêm về công nghệ flash thô bao gồm các nghiên cứu về hiệu năng thực tế của thiết bị (ví dụ như của Chen et al. [CK+09] và Grupp et al. [GC+09]), các vấn đề trong thiết kế FTL (Flash Translation Layer – lớp dịch địa chỉ flash) (bao gồm các công trình của Agrawal et al. [A+08], Gupta et al. [GY+09], Huang et al. [H+14], Kim et al. [KK+02], Lee et al. [L+07], và Zhang et al. [Z+12]), và thậm chí cả các hệ thống phân tán sử dụng flash (bao gồm Gordon [CG+09] và CORFU [B+12]). Và, nếu được phép gợi ý, một cái nhìn tổng quan rất hay về tất cả những gì bạn cần làm để khai thác hiệu năng cao từ SSD có thể tìm thấy trong bài báo về “unwritten contract” [HK+17].
Đừng chỉ đọc các bài báo học thuật; hãy đọc cả những thông tin về các tiến bộ gần đây trên báo chí phổ thông (ví dụ: [V12]). Ở đó, bạn sẽ biết thêm những thông tin thực tiễn (nhưng vẫn hữu ích), chẳng hạn như việc Samsung sử dụng cả cell TLC và SLC trong cùng một SSD để tối đa hóa hiệu năng (SLC có thể buffer dữ liệu ghi nhanh) cũng như dung lượng (TLC có thể lưu nhiều bit hơn trên mỗi cell). Và như người ta thường nói, đây mới chỉ là “phần nổi của tảng băng”. Hãy tự mình tìm hiểu sâu hơn về “tảng băng” nghiên cứu này, có thể bắt đầu với bản khảo sát xuất sắc và gần đây của Ma et al. [M+14]. Nhưng hãy cẩn thận; ngay cả những con tàu vĩ đại nhất cũng có thể bị đánh chìm bởi tảng băng [W15].
ASIDE: CÁC THUẬT NGỮ CHÍNH VỀ SSD (KEY SSD TERMS)
- Một flash chip (chip flash) bao gồm nhiều bank, mỗi bank được tổ chức thành các erase block (khối xóa, đôi khi chỉ gọi là block). Mỗi block lại được chia nhỏ thành một số lượng page nhất định.
- Block có kích thước lớn (128KB–2MB) và chứa nhiều page, vốn có kích thước nhỏ hơn nhiều (1KB–8KB).
- Để đọc từ flash, phát lệnh read kèm địa chỉ và độ dài; điều này cho phép client đọc một hoặc nhiều page.
- Việc ghi vào flash phức tạp hơn. Trước tiên, client phải erase toàn bộ block (xóa toàn bộ thông tin trong block). Sau đó, client có thể program (lập trình) mỗi page đúng một lần, hoàn tất thao tác ghi.
- Một thao tác mới là
trimrất hữu ích để thông báo cho thiết bị biết khi một block (hoặc một dải block) không còn cần thiết nữa.- Độ tin cậy của flash chủ yếu được quyết định bởi wear out (hao mòn); nếu một block bị erase và program quá thường xuyên, nó sẽ trở nên không sử dụng được.
- Một thiết bị lưu trữ thể rắn dựa trên flash (SSD) hoạt động như một ổ đĩa đọc/ghi dựa trên block thông thường; bằng cách sử dụng FTL, nó chuyển đổi các thao tác đọc và ghi từ client thành các thao tác đọc, erase và program trên các chip flash bên dưới.
- Hầu hết các FTL đều có cấu trúc log-structured, giúp giảm chi phí ghi bằng cách tối thiểu hóa số chu kỳ erase/program. Một lớp dịch địa chỉ trong bộ nhớ sẽ theo dõi vị trí các ghi logic trên phương tiện vật lý.
- Một vấn đề chính của FTL log-structured là chi phí garbage collection (thu gom rác), dẫn đến write amplification (khuếch đại ghi).
- Một vấn đề khác là kích thước của mapping table (bảng ánh xạ), vốn có thể trở nên rất lớn. Sử dụng hybrid mapping (ánh xạ lai) hoặc chỉ cache các phần “nóng” của FTL là những cách khắc phục khả thi.
- Vấn đề cuối cùng là wear leveling (cân bằng hao mòn); FTL đôi khi phải di chuyển dữ liệu từ các block chủ yếu được đọc để đảm bảo các block này cũng nhận được phần tải erase/program tương ứng.