37. Ổ đĩa cứng (Hard Disk Drives)
Chương trước đã giới thiệu khái niệm tổng quát về thiết bị I/O (I/O device) và cho thấy hệ điều hành (OS) có thể tương tác với loại thiết bị này như thế nào. Trong chương này, chúng ta sẽ đi sâu hơn vào chi tiết của một thiết bị cụ thể: ổ đĩa cứng (hard disk drive). Trong nhiều thập kỷ, các ổ đĩa này đã là hình thức lưu trữ dữ liệu bền vững (persistent storage) chính trong các hệ thống máy tính, và phần lớn sự phát triển của công nghệ file system (hệ thống tệp – sẽ được đề cập ở các chương sau) đều dựa trên hành vi của chúng. Do đó, việc hiểu rõ chi tiết hoạt động của ổ đĩa là rất cần thiết trước khi xây dựng phần mềm file system để quản lý nó. Nhiều chi tiết trong số này có thể tìm thấy trong các bài báo xuất sắc của Ruemmler và Wilkes [RW92], cũng như Anderson, Dykes và Riedel [ADR03].
THE CRUX: LÀM THẾ NÀO ĐỂ LƯU TRỮ VÀ TRUY XUẤT DỮ LIỆU TRÊN Ổ ĐĨA
Ổ đĩa cứng hiện đại lưu trữ dữ liệu như thế nào? Giao diện của nó ra sao? Dữ liệu thực sự được bố trí và truy cập như thế nào? Lập lịch đĩa (disk scheduling) cải thiện hiệu năng ra sao?
37.1 Giao diện (The Interface)
Hãy bắt đầu bằng cách tìm hiểu giao diện của một ổ đĩa cứng hiện đại. Giao diện cơ bản của tất cả các ổ đĩa hiện đại khá đơn giản: ổ đĩa bao gồm một số lượng lớn sector (khối 512 byte), mỗi sector có thể được đọc hoặc ghi. Các sector được đánh số từ 0 đến n − 1 trên một ổ đĩa có n sector. Do đó, ta có thể hình dung ổ đĩa như một mảng các sector; dải địa chỉ từ 0 đến n − 1 chính là không gian địa chỉ (address space) của ổ đĩa.
Các thao tác trên nhiều sector là khả thi; trên thực tế, nhiều file system sẽ đọc hoặc ghi 4KB mỗi lần (hoặc nhiều hơn). Tuy nhiên, khi cập nhật ổ đĩa, nhà sản xuất chỉ đảm bảo rằng một lần ghi 512 byte là atomic (nguyên tử – tức là hoặc hoàn tất toàn bộ, hoặc không hoàn tất gì cả); do đó, nếu mất điện đột ngột, chỉ một phần của thao tác ghi lớn hơn có thể hoàn tất (điều này đôi khi được gọi là torn write – ghi bị xé lẻ).
Có một số giả định mà hầu hết các client (thành phần sử dụng ổ đĩa) thường mặc định, nhưng không được quy định trực tiếp trong giao diện; Schlosser và Ganger gọi đây là “hợp đồng ngầm” (unwritten contract) của ổ đĩa [SG04]. Cụ thể:
- Thông thường, có thể giả định rằng việc truy cập hai block¹ gần nhau trong không gian địa chỉ của ổ đĩa sẽ nhanh hơn so với truy cập hai block ở xa nhau.
- Cũng thường có thể giả định rằng việc truy cập các block liền kề (tức là đọc hoặc ghi tuần tự – sequential read/write) là chế độ truy cập nhanh nhất, và thường nhanh hơn nhiều so với bất kỳ mẫu truy cập ngẫu nhiên nào.
Hình 37.1: Ổ đĩa với chỉ một track
37.2 Hình học cơ bản (Basic Geometry)
Hãy bắt đầu tìm hiểu một số thành phần của ổ đĩa hiện đại. Chúng ta bắt đầu với platter – một bề mặt cứng hình tròn, nơi dữ liệu được lưu trữ bền vững bằng cách tạo ra các thay đổi từ tính trên nó. Một ổ đĩa có thể có một hoặc nhiều platter; mỗi platter có 2 mặt, mỗi mặt được gọi là một surface. Các platter này thường được làm từ vật liệu cứng (như nhôm), sau đó phủ một lớp từ tính mỏng cho phép ổ đĩa lưu trữ bit dữ liệu một cách bền vững ngay cả khi tắt nguồn.
Tất cả các platter được gắn chung quanh spindle (trục quay), trục này được nối với một motor (động cơ) để quay các platter (khi ổ đĩa được cấp nguồn) ở một tốc độ cố định. Tốc độ quay thường được đo bằng RPM (rotations per minute – vòng quay mỗi phút), và các giá trị phổ biến hiện nay nằm trong khoảng 7.200 RPM đến 15.000 RPM. Lưu ý rằng chúng ta thường quan tâm đến thời gian của một vòng quay đơn; ví dụ, một ổ đĩa quay ở 10.000 RPM nghĩa là một vòng quay mất khoảng 6 mili-giây (6 ms).
Dữ liệu được mã hóa trên mỗi surface thành các vòng tròn đồng tâm của các sector; mỗi vòng tròn như vậy được gọi là một track. Một surface duy nhất chứa hàng nghìn track, được xếp sát nhau, với hàng trăm track có thể nằm gọn trong bề rộng của một sợi tóc người.
Để đọc và ghi từ surface, chúng ta cần một cơ chế cho phép cảm nhận (read) các mẫu từ tính trên đĩa hoặc tạo ra thay đổi (write) chúng. Quá trình đọc và ghi này được thực hiện bởi disk head (đầu đọc/ghi đĩa); mỗi surface của ổ đĩa có một đầu đọc/ghi. Đầu đọc/ghi được gắn vào một disk arm (cần đĩa), di chuyển ngang qua surface để định vị đầu đọc/ghi trên track mong muốn.
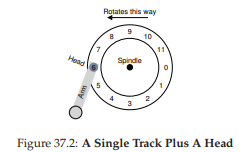
Hình 37.2: Một track đơn và một đầu đọc/ghi
¹Chúng tôi (và nhiều tác giả khác) thường sử dụng các thuật ngữ block và sector thay thế cho nhau, với giả định rằng người đọc sẽ hiểu rõ ý nghĩa trong từng ngữ cảnh. Xin lỗi vì sự bất tiện này!
37.3 Một ổ đĩa đơn giản (A Simple Disk Drive)
Hãy tìm hiểu cách ổ đĩa hoạt động bằng cách xây dựng một mô hình từng track một. Giả sử chúng ta có một ổ đĩa đơn giản với một track duy nhất (Hình 37.1). Track này chỉ có 12 sector, mỗi sector có kích thước 512 byte (kích thước sector tiêu chuẩn, như đã nhắc lại) và được đánh địa chỉ từ 0 đến 11. Platter duy nhất này quay quanh spindle, được nối với một motor.
Tất nhiên, chỉ có track thôi thì chưa đủ thú vị; chúng ta muốn có thể đọc hoặc ghi các sector đó, và do đó cần một disk head gắn vào một disk arm, như minh họa trong Hình 37.2. Trong hình, đầu đọc/ghi đĩa, gắn ở cuối cần đĩa, đang được định vị trên sector số 6, và surface đang quay theo chiều ngược kim đồng hồ.
Độ trễ trên một track: Rotational Delay (độ trễ quay)
Để hiểu cách một yêu cầu được xử lý trên ổ đĩa đơn giản chỉ có một track, hãy tưởng tượng chúng ta nhận được một yêu cầu đọc block 0. Ổ đĩa sẽ phục vụ yêu cầu này như thế nào?
Trong ổ đĩa đơn giản này, ổ đĩa không cần làm nhiều việc. Cụ thể, nó chỉ cần chờ cho sector mong muốn quay đến vị trí ngay dưới disk head (đầu đọc/ghi). Việc chờ này xảy ra khá thường xuyên ở các ổ đĩa hiện đại và là một thành phần đủ quan trọng trong I/O service time (thời gian phục vụ I/O) để có một tên riêng: rotational delay (độ trễ quay – đôi khi gọi là rotation delay, nhưng nghe hơi lạ).
Trong ví dụ, nếu độ trễ quay toàn phần là R, ổ đĩa sẽ phải chịu một độ trễ quay khoảng R/2 để chờ sector 0 đi qua dưới đầu đọc/ghi (nếu bắt đầu từ sector 6). Trường hợp xấu nhất trên track này là yêu cầu tới sector 5, khiến ổ đĩa phải chịu gần như toàn bộ độ trễ quay để phục vụ yêu cầu.
Nhiều track: Seek Time (thời gian tìm kiếm)
Cho đến giờ, ổ đĩa của chúng ta chỉ có một track, điều này không thực tế; các ổ đĩa hiện đại tất nhiên có hàng triệu track. Hãy xem xét một bề mặt đĩa thực tế hơn một chút, với ba track (Hình 37.3, bên trái). Trong hình, đầu đọc/ghi hiện đang ở track trong cùng (chứa các sector từ 24 đến 35); track kế tiếp chứa các sector từ 12 đến 23, và track ngoài cùng chứa các sector từ 0 đến 11.
Để hiểu cách ổ đĩa truy cập một sector nhất định, hãy lần theo những gì xảy ra khi có yêu cầu đọc tới một sector ở xa, ví dụ: đọc sector 11. Để phục vụ yêu cầu này, ổ đĩa phải di chuyển cần đĩa (disk arm) tới đúng track (trong trường hợp này là track ngoài cùng), trong một quá trình gọi là seek (tìm kiếm). Seek, cùng với quay (rotation), là một trong những thao tác tốn kém nhất của ổ đĩa.
Seek có nhiều giai đoạn:
- Tăng tốc khi cần đĩa bắt đầu di chuyển.
- Chạy đều khi cần di chuyển ở tốc độ tối đa.
- Giảm tốc khi cần chậm lại.
- Cuối cùng là ổn định (settling) khi đầu đọc/ghi được định vị chính xác trên track mong muốn.
Thời gian ổn định thường khá đáng kể, ví dụ từ 0,5 đến 2 ms, vì ổ đĩa phải chắc chắn tìm đúng track (hãy tưởng tượng nếu nó chỉ “gần đúng” thì sẽ ra sao!).
Sau khi seek, cần đĩa đã đưa đầu đọc/ghi đến đúng track. Minh họa seek được thể hiện trong Hình 37.3 (bên phải).
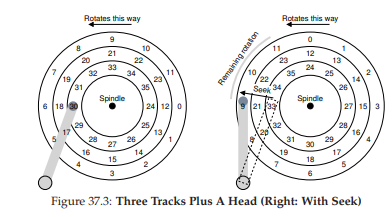
Hình 37.3: Ba track và một đầu đọc/ghi (phải: với seek)
Như ta thấy, trong quá trình seek, cần đĩa đã di chuyển tới track mong muốn, và platter tất nhiên vẫn quay — trong ví dụ này là khoảng 3 sector. Do đó, sector 9 sắp đi qua dưới đầu đọc/ghi, và chúng ta chỉ cần chịu một độ trễ quay ngắn để hoàn tất việc truyền dữ liệu.
Khi sector 11 đi qua dưới đầu đọc/ghi, giai đoạn cuối của I/O sẽ diễn ra, gọi là transfer (truyền dữ liệu), nơi dữ liệu được đọc từ hoặc ghi xuống bề mặt đĩa. Như vậy, ta có bức tranh hoàn chỉnh về I/O time (thời gian I/O): đầu tiên là seek, sau đó là rotational delay, và cuối cùng là transfer.
Một số chi tiết khác
Mặc dù chúng ta sẽ không đi quá sâu, nhưng có một số chi tiết thú vị khác về cách ổ đĩa cứng hoạt động:
- Nhiều ổ đĩa sử dụng một dạng track skew (độ lệch track) để đảm bảo rằng các thao tác đọc tuần tự (sequential read) có thể được phục vụ chính xác ngay cả khi vượt qua ranh giới giữa các track. Trong ổ đĩa ví dụ đơn giản của chúng ta, điều này có thể trông như trong Hình 37.4.
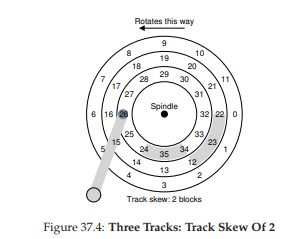
Hình 37.4: Ba track với track skew bằng 2
Các sector thường được sắp xếp lệch như vậy vì khi chuyển từ track này sang track khác, ổ đĩa cần thời gian để định vị lại đầu đọc/ghi (ngay cả khi chỉ sang track liền kề). Nếu không có skew, khi đầu đọc/ghi được chuyển sang track tiếp theo, block mong muốn có thể đã quay qua mất, khiến ổ đĩa phải chờ gần như toàn bộ độ trễ quay để truy cập block tiếp theo.
-
Một thực tế khác là các track ngoài thường có nhiều sector hơn các track trong, do yếu tố hình học — đơn giản là ở ngoài có nhiều không gian hơn. Các ổ đĩa như vậy thường được gọi là multi-zoned disk drives (ổ đĩa đa vùng), trong đó đĩa được tổ chức thành nhiều zone (vùng), mỗi vùng là một tập hợp liên tiếp các track trên một surface. Mỗi zone có cùng số sector trên mỗi track, và các zone ngoài có nhiều sector hơn các zone trong.
-
Cuối cùng, một phần quan trọng của bất kỳ ổ đĩa hiện đại nào là cache (bộ nhớ đệm), vì lý do lịch sử đôi khi được gọi là track buffer. Cache này chỉ là một lượng nhỏ bộ nhớ (thường khoảng 8 hoặc 16 MB) mà ổ đĩa có thể dùng để lưu dữ liệu đọc từ hoặc ghi xuống đĩa.
Ví dụ: khi đọc một sector từ đĩa, ổ đĩa có thể quyết định đọc toàn bộ các sector trên track đó và lưu vào cache; điều này cho phép ổ đĩa phản hồi nhanh hơn với các yêu cầu tiếp theo tới cùng track. -
Khi ghi (write), ổ đĩa có hai lựa chọn:
- Xác nhận ghi hoàn tất khi dữ liệu đã được đưa vào bộ nhớ của nó.
- Xác nhận ghi hoàn tất chỉ sau khi dữ liệu đã thực sự được ghi xuống đĩa.
Cách thứ nhất gọi là write-back caching (hoặc đôi khi là immediate reporting), cách thứ hai gọi là write-through. Write-back caching đôi khi khiến ổ đĩa trông “nhanh hơn”, nhưng có thể nguy hiểm; nếu file system hoặc ứng dụng yêu cầu dữ liệu phải được ghi xuống đĩa theo một thứ tự nhất định để đảm bảo tính đúng đắn, write-back caching có thể gây ra vấn đề (hãy đọc chương về file-system journaling để biết chi tiết).
ASIDE: PHÂN TÍCH KÍCH THƯỚC (DIMENSIONAL ANALYSIS)
Bạn còn nhớ trong lớp Hóa học, cách mà bạn giải hầu hết mọi bài toán chỉ bằng cách thiết lập các đơn vị sao cho chúng triệt tiêu lẫn nhau, và bằng cách nào đó câu trả lời xuất hiện? “Phép màu” hóa học đó có tên gọi “cao siêu” là dimensional analysis (phân tích kích thước), và hóa ra nó cũng hữu ích trong phân tích hệ thống máy tính.Hãy làm một ví dụ để xem dimensional analysis hoạt động thế nào và tại sao nó hữu ích. Trong trường hợp này, giả sử bạn cần tính xem một vòng quay của ổ đĩa mất bao lâu, tính bằng mili-giây. Không may là bạn chỉ được cho RPM (rotations per minute – số vòng quay mỗi phút) của ổ đĩa. Giả sử chúng ta đang nói về một ổ đĩa 10K RPM (tức là quay 10.000 vòng mỗi phút). Làm thế nào để thiết lập phân tích kích thước để nhận được thời gian mỗi vòng quay tính bằng mili-giây?
Để làm điều đó, ta bắt đầu bằng cách đặt đơn vị mong muốn ở bên trái; trong trường hợp này, ta muốn có thời gian (ms) trên mỗi vòng quay, vì vậy ta viết:
Time (ms) / Rotation.
Sau đó, ta viết ra tất cả những gì mình biết, đảm bảo triệt tiêu đơn vị khi có thể. Đầu tiên, ta có:
1 minute / 10,000 Rotations (giữ “rotation” ở mẫu số, vì nó cũng ở mẫu số bên trái), sau đó đổi phút sang giây: 60 seconds / 1 minute, và cuối cùng đổi giây sang mili-giây: 1000 ms / 1 second.
Kết quả cuối cùng (với các đơn vị được triệt tiêu gọn gàng) là:Time (ms) / Rot. = (1 minute / 10,000 Rot.) * (60 seconds / 1 minute) * (1000 ms / 1 second) Time (ms) / Rot. = 60,000 ms / 10,000 Rot. = 6 ms / Rot.Như bạn thấy từ ví dụ này, dimensional analysis biến điều tưởng chừng trực giác thành một quy trình đơn giản và có thể lặp lại. Ngoài phép tính RPM ở trên, nó còn hữu ích thường xuyên trong phân tích I/O.
Ví dụ: bạn thường được cho tốc độ truyền của một ổ đĩa, chẳng hạn 100 MB/second, và được hỏi: mất bao lâu để truyền một block 512 KB (tính bằng mili-giây)? Với dimensional analysis, điều này rất dễ:Time (ms) / Request = (1 Request / 512 KB) * (1 MB / 100 MB/second) * (1024 KB / 1 MB) * (1000 ms / 1 second) Time (ms) / Request = (512 * 1024 * 1000) / (100 * 1024) = 5.12 ms (xấp xỉ, bản gốc có sai số nhỏ trong phép tính)
37.4 Thời gian I/O: Thực hiện phép tính (I/O Time: Doing The Math)
Bây giờ, khi đã có một mô hình trừu tượng về ổ đĩa, chúng ta có thể sử dụng một chút phân tích để hiểu rõ hơn về hiệu năng của ổ đĩa. Cụ thể, chúng ta có thể biểu diễn thời gian I/O như tổng của ba thành phần chính:
[ T_{I/O} = T_{seek} + T_{rotation} + T_{transfer} \tag{37.1} ]
Lưu ý rằng tốc độ I/O ((R_{I/O})), thường dễ sử dụng hơn để so sánh giữa các ổ đĩa (như chúng ta sẽ làm bên dưới), có thể dễ dàng tính từ thời gian. Chỉ cần chia kích thước dữ liệu truyền cho thời gian thực hiện:
[ R_{I/O} = \frac{Size_{Transfer}}{T_{I/O}} \tag{37.2} ]
Để cảm nhận rõ hơn về thời gian I/O, hãy thực hiện phép tính sau. Giả sử có hai loại workload (khối lượng công việc) mà chúng ta quan tâm:
- Random workload: phát ra các yêu cầu đọc nhỏ (ví dụ: 4KB) tới các vị trí ngẫu nhiên trên ổ đĩa. Loại workload ngẫu nhiên này phổ biến trong nhiều ứng dụng quan trọng, bao gồm cả database management systems (hệ quản trị cơ sở dữ liệu).
- Sequential workload: chỉ đơn giản đọc một số lượng lớn sector liên tiếp từ ổ đĩa, không nhảy lung tung. Mẫu truy cập tuần tự này cũng rất phổ biến và quan trọng.
Để hiểu sự khác biệt về hiệu năng giữa workload ngẫu nhiên và tuần tự, trước tiên chúng ta cần đưa ra một số giả định về ổ đĩa. Hãy xem xét hai ổ đĩa hiện đại của Seagate:
- Cheetah 15K.5 [S09b]: một ổ SCSI hiệu năng cao.
- Barracuda [S09a]: một ổ được thiết kế cho dung lượng lớn.
Chi tiết của cả hai được thể hiện trong Hình 37.5.
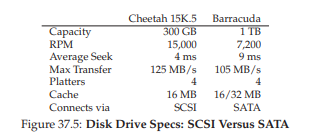
Hình 37.5: Thông số ổ đĩa – SCSI so với SATA
Như bạn có thể thấy, hai ổ đĩa có các đặc tính khá khác nhau, và theo nhiều cách, chúng tóm tắt khá rõ hai phân khúc quan trọng của thị trường ổ đĩa. Phân khúc thứ nhất là thị trường “high performance” (hiệu năng cao), nơi các ổ đĩa được thiết kế để quay nhanh nhất có thể, đạt thời gian seek thấp và truyền dữ liệu nhanh. Phân khúc thứ hai là thị trường “capacity” (dung lượng), nơi chi phí trên mỗi byte là yếu tố quan trọng nhất; do đó, các ổ đĩa này chậm hơn nhưng lưu trữ được nhiều bit nhất có thể trong không gian sẵn có.
Từ các con số này, chúng ta có thể bắt đầu tính toán hiệu năng của các ổ đĩa dưới hai loại workload (khối lượng công việc) đã nêu ở trên. Hãy bắt đầu với random workload. Giả sử mỗi lần đọc 4 KB xảy ra tại một vị trí ngẫu nhiên trên đĩa, ta có thể tính thời gian cho mỗi lần đọc như vậy. Với ổ Cheetah:
Tseek = 4 ms, Trotation = 2 ms, Ttransfer = 30 microseconds
(37.3)
Thời gian seek trung bình (4 mili-giây) được lấy từ thông số trung bình do nhà sản xuất công bố; lưu ý rằng một lần seek toàn phần (từ một đầu bề mặt đến đầu kia) có thể mất gấp hai hoặc ba lần thời gian này. Độ trễ quay trung bình được tính trực tiếp từ RPM. 15000 RPM tương đương 250 RPS (rotations per second – vòng quay mỗi giây); do đó, mỗi vòng quay mất 4 ms. Trung bình, ổ đĩa sẽ phải chờ nửa vòng quay, tức khoảng 2 ms. Cuối cùng, thời gian truyền dữ liệu chỉ đơn giản là kích thước dữ liệu chia cho tốc độ truyền tối đa; ở đây nó rất nhỏ (30 micro-giây; lưu ý rằng cần 1000 micro-giây mới được 1 mili-giây!).
Do đó, từ phương trình ở trên, (T_{I/O}) cho Cheetah xấp xỉ 6 ms. Để tính tốc độ I/O ((R_{I/O})), ta chỉ cần chia kích thước dữ liệu truyền cho thời gian trung bình, và thu được (R_{I/O}) cho Cheetah dưới random workload vào khoảng 0,66 MB/s. Cùng phép tính cho Barracuda cho ra (T_{I/O}) khoảng 13,2 ms (chậm hơn hơn gấp đôi), và tốc độ khoảng 0,31 MB/s.
Bây giờ hãy xem sequential workload. Ở đây, ta có thể giả định chỉ có một lần seek và quay trước khi thực hiện một lần truyền dữ liệu rất dài. Để đơn giản, giả sử kích thước dữ liệu truyền là 100 MB. Khi đó, (T_{I/O}) cho Cheetah và Barracuda lần lượt khoảng 800 ms và 950 ms. Tốc độ I/O do đó gần bằng tốc độ truyền tối đa: 125 MB/s và 105 MB/s. Hình 37.6 tóm tắt các con số này.
TIP: SỬ DỤNG Ổ ĐĨA THEO TUẦN TỰ
Khi có thể, hãy truyền dữ liệu tới và từ ổ đĩa theo cách tuần tự. Nếu không thể tuần tự, ít nhất hãy nghĩ đến việc truyền dữ liệu theo các khối lớn: càng lớn càng tốt. Nếu I/O được thực hiện thành các mảnh nhỏ ngẫu nhiên, hiệu năng I/O sẽ giảm nghiêm trọng. Người dùng sẽ chịu khổ. Và bạn cũng sẽ chịu khổ, khi biết rằng mình đã gây ra nỗi khổ đó với những thao tác I/O ngẫu nhiên bất cẩn.

Hình 37.6: Hiệu năng ổ đĩa – SCSI so với SATA
| | Cheetah | Barracuda |
| :---------------- | :------------ | :-------- |
| RI/O Random | 0.66 MB/s | 0.31 MB/s |
| RI/O Sequential | 125 MB/s | 105 MB/s |
Bảng trên cho thấy một số điểm quan trọng. Thứ nhất, và quan trọng nhất, là khoảng cách rất lớn về hiệu năng giữa random workload và sequential workload — gần 200 lần đối với Cheetah và hơn 300 lần đối với Barracuda. Và từ đó, chúng ta rút ra một lời khuyên thiết kế hiển nhiên nhất trong lịch sử ngành máy tính.
Điểm thứ hai, tinh tế hơn: có sự khác biệt lớn về hiệu năng giữa các ổ “performance” cao cấp và các ổ “capacity” giá rẻ. Vì lý do này (và nhiều lý do khác), mọi người thường sẵn sàng trả giá cao cho loại thứ nhất, trong khi cố gắng mua loại thứ hai với giá rẻ nhất có thể.
ASIDE: TÍNH “SEEK” TRUNG BÌNH
Trong nhiều sách và bài báo, bạn sẽ thấy thời gian seek trung bình của ổ đĩa được trích dẫn là xấp xỉ một phần ba thời gian seek toàn phần. Điều này đến từ đâu?Hóa ra nó xuất phát từ một phép tính đơn giản dựa trên khoảng cách seek trung bình, không phải thời gian. Hãy hình dung ổ đĩa như một tập hợp các track, từ 0 đến N. Khoảng cách seek giữa hai track x và y được tính là giá trị tuyệt đối của hiệu số giữa chúng: (|x − y|).
Để tính khoảng cách seek trung bình, trước tiên bạn chỉ cần cộng tất cả các khoảng cách seek có thể:
SUM(x=0 to N) SUM(y=0 to N) |x - y| (37.4)Sau đó, chia cho số lượng seek có thể có: (N^2). Để tính tổng, ta dùng dạng tích phân:
Integral(x=0 to N) Integral(y=0 to N) |x - y| dy dx (37.5)Để tính tích phân bên trong, ta tách giá trị tuyệt đối:
Integral(y=0 to x) (x - y) dy + Integral(y=x to N) (y - x) dy (37.6)Giải ra được ((xy − (1/2)y^2)) từ 0 đến x cộng với (((1/2)y^2 − xy)) từ x đến N, có thể rút gọn thành ((x^2 − Nx + (1/2)N^2)). Bây giờ ta tính tích phân bên ngoài:
Integral(x=0 to N) (x^2 − Nx + (1/2)N^2) dx (37.7)Kết quả là:
(1/3)x^3 − (1/2)Nx^2 + (1/2)N^2x từ 0 đến N (1/3)N^3 − (1/2)N^3 + (1/2)N^3 = (1/3)N^3 (37.8)Nhớ rằng ta vẫn phải chia cho tổng số seek ((N^2)) để tính khoảng cách seek trung bình: (((1/3)N^3) / N^2 = (1/3)N).
Do đó, khoảng cách seek trung bình trên một ổ đĩa, xét trên tất cả các seek có thể, là một phần ba khoảng cách toàn phần. Và bây giờ, khi nghe rằng seek trung bình bằng một phần ba seek toàn phần, bạn sẽ biết nó đến từ đâu.
37.5 Lập lịch đĩa (Disk Scheduling)
Do chi phí I/O cao, hệ điều hành (OS) từ trước đến nay luôn đóng vai trò trong việc quyết định thứ tự các yêu cầu I/O được gửi tới ổ đĩa. Cụ thể hơn, khi có một tập hợp các yêu cầu I/O, disk scheduler (bộ lập lịch đĩa) sẽ xem xét các yêu cầu và quyết định yêu cầu nào sẽ được lập lịch tiếp theo [SCO90, JW91].
Không giống như job scheduling (lập lịch công việc), nơi thời lượng của mỗi job thường không được biết trước, với disk scheduling, ta có thể ước lượng khá tốt thời gian một “job” (tức là một yêu cầu đĩa) sẽ mất. Bằng cách ước lượng seek time (thời gian tìm kiếm) và rotational delay (độ trễ quay) có thể xảy ra của một yêu cầu, disk scheduler có thể biết mỗi yêu cầu sẽ mất bao lâu, và do đó (theo cách tham lam) chọn yêu cầu mất ít thời gian nhất để phục vụ trước. Vì vậy, disk scheduler sẽ cố gắng tuân theo nguyên tắc SJF (shortest job first – công việc ngắn nhất trước) trong hoạt động của mình.
SSTF: Shortest Seek Time First
Một phương pháp lập lịch đĩa sớm được biết đến là shortest-seek-time-first (SSTF) (còn gọi là shortest-seek-first hoặc SSF). SSTF sắp xếp hàng đợi các yêu cầu I/O theo track, chọn các yêu cầu trên track gần nhất để hoàn thành trước.
Ví dụ: giả sử vị trí hiện tại của đầu đọc/ghi (head) đang ở track trong cùng, và chúng ta có các yêu cầu cho sector 21 (track giữa) và sector 2 (track ngoài cùng), khi đó ta sẽ xử lý yêu cầu tới sector 21 trước, chờ hoàn tất, rồi mới xử lý yêu cầu tới sector 2 (Hình 37.7).
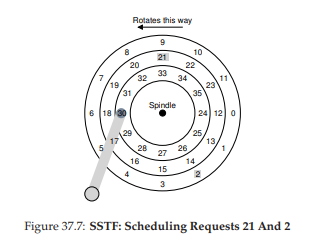
Hình 37.7: SSTF – Lập lịch các yêu cầu 21 và 2
SSTF hoạt động tốt trong ví dụ này, tìm tới track giữa trước rồi tới track ngoài cùng. Tuy nhiên, SSTF không phải là “thuốc chữa bách bệnh”, vì các lý do sau:
- Thứ nhất, drive geometry (hình học của ổ đĩa) không được cung cấp cho OS; thay vào đó, OS chỉ thấy một mảng các block. May mắn là vấn đề này khá dễ khắc phục: thay vì SSTF, OS có thể triển khai nearest-block-first (NBF), lập lịch yêu cầu có địa chỉ block gần nhất tiếp theo.
- Vấn đề thứ hai mang tính cơ bản hơn: starvation (đói tài nguyên). Hãy tưởng tượng trong ví dụ trên, nếu có một luồng yêu cầu liên tục tới track trong cùng (nơi head đang ở), thì các yêu cầu tới các track khác sẽ bị bỏ qua hoàn toàn nếu dùng SSTF thuần túy.
THE CRUX: LÀM THẾ NÀO ĐỂ XỬ LÝ STARVATION TRÊN Ổ ĐĨA
Làm thế nào để triển khai lập lịch kiểu SSTF nhưng tránh được starvation?
Elevator (còn gọi là SCAN hoặc C-SCAN)
Câu trả lời cho vấn đề này đã được phát triển từ lâu (xem [CKR72] chẳng hạn) và khá đơn giản. Thuật toán, ban đầu gọi là SCAN, chỉ đơn giản di chuyển qua lại trên ổ đĩa, phục vụ các yêu cầu theo thứ tự trên các track. Ta gọi một lần quét toàn bộ ổ đĩa (từ track ngoài vào track trong, hoặc ngược lại) là một sweep. Do đó, nếu một yêu cầu tới một block trên track đã được phục vụ trong sweep hiện tại, nó sẽ không được xử lý ngay, mà sẽ được đưa vào hàng đợi để xử lý ở sweep tiếp theo (theo hướng ngược lại).
SCAN có một số biến thể, tất cả đều hoạt động tương tự. Ví dụ, Coffman và cộng sự giới thiệu F-SCAN, đóng băng hàng đợi cần phục vụ khi đang thực hiện một sweep [CKR72]; các yêu cầu đến trong khi sweep đang diễn ra sẽ được đưa vào hàng đợi để xử lý sau. Cách này tránh starvation cho các yêu cầu ở xa, bằng cách trì hoãn xử lý các yêu cầu đến muộn nhưng ở gần.
C-SCAN là một biến thể phổ biến khác, viết tắt của Circular SCAN. Thay vì quét theo cả hai hướng, thuật toán chỉ quét từ ngoài vào trong, rồi “reset” về track ngoài cùng để bắt đầu lại. Cách này công bằng hơn cho các track ngoài và trong, vì SCAN thuần túy ưu tiên các track giữa (sau khi phục vụ track ngoài, SCAN sẽ đi qua track giữa hai lần trước khi quay lại track ngoài).
Vì lý do này, thuật toán SCAN (và các biến thể) đôi khi được gọi là elevator algorithm (thuật toán thang máy), vì nó hoạt động giống như một thang máy chỉ đi lên hoặc đi xuống, chứ không phục vụ các tầng chỉ dựa trên việc tầng nào gần hơn. Hãy tưởng tượng bạn đang đi xuống từ tầng 10 xuống tầng 1, và ai đó ở tầng 3 bấm tầng 4, và thang máy lại đi lên tầng 4 vì nó “gần” hơn tầng 1! Trong thực tế, elevator algorithm giúp tránh những tình huống khó chịu như vậy; còn trong ổ đĩa, nó giúp tránh starvation.
Tuy nhiên, SCAN và các biến thể không phải là công nghệ lập lịch tốt nhất. Đặc biệt, SCAN (hoặc thậm chí SSTF) không tuân thủ nguyên tắc SJF một cách chặt chẽ nhất có thể, vì chúng bỏ qua yếu tố rotation. Và do đó, một vấn đề trọng tâm khác xuất hiện:
THE CRUX: LÀM THẾ NÀO ĐỂ TÍNH ĐẾN CHI PHÍ QUAY CỦA Ổ ĐĨA
Làm thế nào để triển khai một thuật toán gần với SJF hơn bằng cách tính cả seek và rotation?
SPTF: Shortest Positioning Time First
Trước khi thảo luận về shortest positioning time first (SPTF) (đôi khi còn gọi là shortest access time first hoặc SATF) – giải pháp cho vấn đề trên – hãy đảm bảo rằng chúng ta hiểu rõ vấn đề. Hình 37.8 đưa ra một ví dụ.
Trong ví dụ, head hiện đang ở sector 30 trên track trong cùng. Bộ lập lịch phải quyết định: nên lập lịch sector 16 (trên track giữa) hay sector 8 (trên track ngoài cùng) cho yêu cầu tiếp theo? Vậy nên phục vụ yêu cầu nào trước?
Câu trả lời, tất nhiên, là “còn tùy”. Trong kỹ thuật, “còn tùy” gần như luôn là câu trả lời, phản ánh rằng các đánh đổi (trade-off) là một phần tất yếu trong công việc của kỹ sư; đây cũng là một câu trả lời “an toàn” khi bạn chưa biết câu trả lời cho câu hỏi của sếp. Tuy nhiên, gần như luôn tốt hơn nếu biết tại sao lại “còn tùy”, và đó là điều chúng ta sẽ bàn ở đây.
Điều mà nó “tùy” ở đây là tương quan giữa thời gian seek và thời gian quay. Nếu, trong ví dụ này, thời gian seek lớn hơn nhiều so với độ trễ quay, thì SSTF (và các biến thể) là đủ tốt. Tuy nhiên, hãy tưởng tượng nếu seek nhanh hơn đáng kể so với rotation. Khi đó, trong ví dụ này, sẽ hợp lý hơn nếu seek xa hơn để phục vụ yêu cầu 8 trên track ngoài cùng, thay vì thực hiện seek ngắn hơn tới track giữa để phục vụ yêu cầu 16, vốn phải quay gần như cả vòng mới đi qua dưới đầu đọc/ghi.
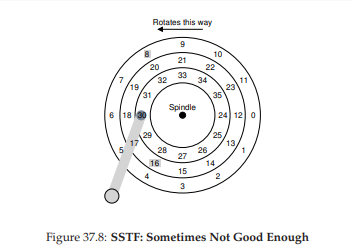
Hình 37.8: SSTF – Đôi khi là chưa đủ tốt
TIP: LUÔN LUÔN “CÒN TÙY” (ĐỊNH LUẬT CỦA LIVNY)
Hầu như bất kỳ câu hỏi nào cũng có thể trả lời bằng “còn tùy”, như đồng nghiệp của chúng tôi, Miron Livny, vẫn thường nói. Tuy nhiên, hãy sử dụng một cách thận trọng, vì nếu bạn trả lời quá nhiều câu hỏi theo cách này, mọi người sẽ ngừng hỏi bạn luôn. Ví dụ, ai đó hỏi: “Muốn đi ăn trưa không?” Bạn trả lời: “Còn tùy, bạn có đi cùng không?”
Trên các ổ đĩa hiện đại, như chúng ta đã thấy ở trên, cả seek (tìm kiếm) và rotation (quay) đều có thời gian gần tương đương nhau (tất nhiên còn tùy thuộc vào yêu cầu cụ thể), và do đó SPTF (Shortest Positioning Time First) là hữu ích và cải thiện hiệu năng. Tuy nhiên, việc triển khai nó trong hệ điều hành còn khó hơn, vì OS thường không biết rõ ranh giới track ở đâu hoặc đầu đọc/ghi (disk head) hiện đang ở vị trí nào (theo nghĩa quay). Do đó, SPTF thường được thực hiện bên trong ổ đĩa, như mô tả dưới đây.
Các vấn đề lập lịch khác
Có nhiều vấn đề khác mà chúng ta không bàn sâu trong phần mô tả ngắn gọn này về hoạt động cơ bản của ổ đĩa, lập lịch và các chủ đề liên quan. Một vấn đề như vậy là: lập lịch đĩa được thực hiện ở đâu trong các hệ thống hiện đại?
Trong các hệ thống cũ, hệ điều hành thực hiện toàn bộ việc lập lịch; sau khi xem xét tập hợp các yêu cầu đang chờ, OS sẽ chọn yêu cầu tốt nhất và gửi nó tới ổ đĩa. Khi yêu cầu đó hoàn tất, yêu cầu tiếp theo sẽ được chọn, và cứ thế tiếp tục. Ổ đĩa khi đó đơn giản hơn, và cuộc sống cũng vậy.
Trong các hệ thống hiện đại, ổ đĩa có thể xử lý nhiều yêu cầu đang chờ cùng lúc, và bản thân chúng có các internal scheduler (bộ lập lịch nội bộ) tinh vi (có thể triển khai SPTF một cách chính xác; bên trong disk controller – bộ điều khiển đĩa – mọi chi tiết liên quan đều có sẵn, bao gồm cả vị trí chính xác của đầu đọc và thông tin bố trí track chi tiết). Do đó, bộ lập lịch của OS thường chọn ra một số yêu cầu mà nó cho là tốt nhất (ví dụ 16 yêu cầu) và gửi tất cả tới ổ đĩa; ổ đĩa sau đó sử dụng kiến thức nội bộ về vị trí đầu đọc và bố trí track để phục vụ các yêu cầu đó theo thứ tự tối ưu nhất (SPTF).
Một nhiệm vụ quan trọng khác mà bộ lập lịch đĩa thực hiện là I/O merging (gộp I/O). Ví dụ, hãy tưởng tượng một loạt yêu cầu đọc các block 33, sau đó 8, rồi 34, như trong Hình 37.8. Trong trường hợp này, bộ lập lịch nên gộp các yêu cầu cho block 33 và 34 thành một yêu cầu đọc hai block duy nhất; mọi thao tác sắp xếp lại mà bộ lập lịch thực hiện sẽ được áp dụng trên các yêu cầu đã gộp. Việc gộp đặc biệt quan trọng ở cấp OS, vì nó giảm số lượng yêu cầu gửi tới ổ đĩa và do đó giảm chi phí xử lý.
Một vấn đề cuối cùng mà các bộ lập lịch hiện đại xử lý là: hệ thống nên chờ bao lâu trước khi gửi một yêu cầu I/O tới ổ đĩa?
Có thể bạn sẽ nghĩ một cách đơn giản rằng ổ đĩa, khi có bất kỳ yêu cầu I/O nào, nên lập tức gửi yêu cầu đó tới thiết bị; cách tiếp cận này được gọi là work-conserving, vì ổ đĩa sẽ không bao giờ nhàn rỗi nếu còn yêu cầu cần xử lý. Tuy nhiên, nghiên cứu về anticipatory disk scheduling (lập lịch đĩa dự đoán) đã chỉ ra rằng đôi khi tốt hơn là nên chờ một chút [ID01], trong cách tiếp cận gọi là non-work-conserving. Bằng cách chờ, có thể sẽ xuất hiện một yêu cầu mới và “tốt hơn” tới ổ đĩa, từ đó tăng hiệu quả tổng thể. Tất nhiên, việc quyết định khi nào nên chờ và chờ bao lâu có thể rất phức tạp; hãy xem bài báo nghiên cứu để biết chi tiết, hoặc xem triển khai trong Linux kernel để thấy cách những ý tưởng này được áp dụng vào thực tế (nếu bạn là người ưa thử thách).
37.6 Tóm tắt
Chúng ta đã trình bày một bản tóm tắt về cách ổ đĩa hoạt động. Bản tóm tắt này thực chất là một mô hình chức năng chi tiết; nó không mô tả những yếu tố vật lý, điện tử và khoa học vật liệu tuyệt vời được áp dụng trong thiết kế ổ đĩa thực tế.
Nếu bạn quan tâm đến những chi tiết sâu hơn về các khía cạnh này, có lẽ bạn nên chọn một chuyên ngành (hoặc chuyên ngành phụ) khác; còn nếu bạn hài lòng với mô hình này, thì tốt! Giờ đây, chúng ta có thể tiếp tục sử dụng mô hình này để xây dựng những hệ thống thú vị hơn dựa trên các thiết bị tuyệt vời này.